
Logan Markewich • 2024-01-02
使用 AWS 和 Hugging Face 扩展 LlamaIndex
假期期间,我使用 LlamaIndex 运行了一些检索基准测试。我发现自己需要反复用 3 万份文档重建索引,每次等待 10-20 分钟让人难以忍受。
为了解决这个问题,我决定硬着头皮研究如何在 AWS 上部署 LlamaIndex,并创建一个可扩展的 ETL 管道来索引我的数据。这使得处理时间缩短到大约 5 分钟!
如果您想跳过详细步骤,可以直接查看以下存储库中的代码
https://github.com/run-llama/llamaindex_aws_ingestion
注意: 我不是 AWS 专家,在这个项目之前对它没有任何经验。我提出的设计可能还有改进空间。这篇博客只是记录了我首次尝试在 AWS 上构建系统。我希望这能帮助其他人入门,并为其他工程师部署更具可扩展性的系统打开大门。
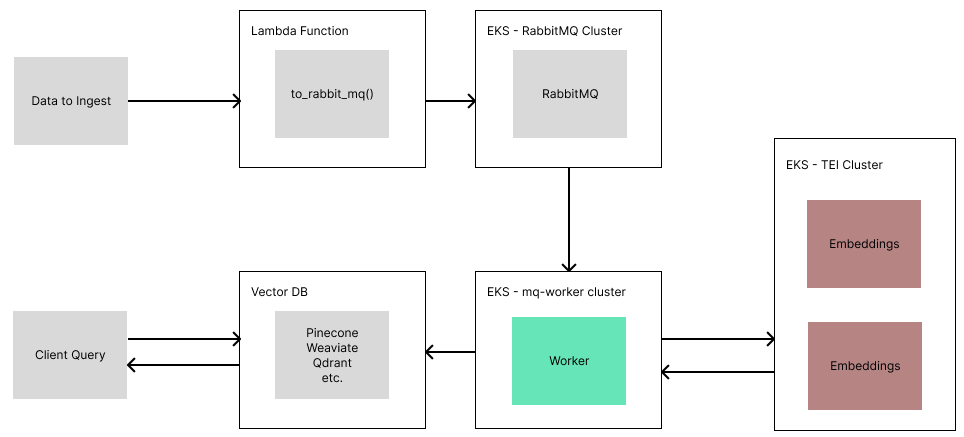
步骤 1:了解 AWS 的工作原理
为了有效地使用 AWS,您需要以下几个软件包和工具
- AWS 账户注册
- 安装 AWS CLI
- 用于通过 CLI 工具验证您的 AWS 账户
- 安装 eksctl
- 用于轻松创建
EKS集群 - 安装 kubectl
- 用于配置和调试部署、Pods、服务等。
- 安装 Docker
正如您将看到的,几乎所有的 AWS 部署都围绕着描述您要部署的内容及其连接方式的 yaml 文件,以及一些实际运行部署的 CLI 命令。
如果您在任何时候不确定发生了什么,我发现访问 AWS 控制面板并查看我实际部署的资源很有帮助。通常,您会想要访问。我在 AWS 中收藏了以下页面。另外,请记住在右上角正确设置您的区域!

关于部署工作原理的说明
对于大多数部署,您通常会包含
- 集群
- 部署的应用,扩展到 X 个副本
- 一个负载均衡器,用于在 X 个副本之间平衡传入请求
在下面的示例中,大多数将包含一个用于部署应用的 yaml 文件、一个用于负载均衡器的 yaml 文件,以及一个用于创建您要运行的集群的命令。
有用的 CLI 命令
几个 CLI 命令对于调试和监控部署非常有帮助。
# get the state of pods/deployments
kubectl get pods
kubectl get deployments
# useful for seeing logs/events of pods + full yaml config
kubectl describe pod <pod name>
kubectl logs <pod name>
# list clusters kubectl knows about
kubectl config get-contexts
# switch kubectl to another cluster
kubectl config use-context <context name>
# delete things
kubectl delete <pod/deployment/service> <name>步骤 2:部署文本嵌入接口
为了快速运行嵌入,我们将使用 HuggingFace 的 Text Embedding Interface (TEI) 部署一个嵌入服务器。这个服务器开箱即用,具备生产级特性和优化,包括连续批处理、Flash Attention、Rust 实现等。HuggingFace 提供了预构建的 Docker 镜像以简化部署。
然而,快速运行嵌入的第一步是拥有一个 GPU。如果您刚注册 AWS,则需要请求提高配额。就我而言,我多次请求 G5 实例(运行 Nvidia A10G GPU),在 CPU 上测试几天后,AWS 允许我使用最多 4 个 G5 实例。
获得 GPU 实例(如 G5 节点)的配额后,您可以创建集群并进行部署
eksctl create cluster --name embeddings --node-type=g5.xlarge --nodes 1
sleep 5
kubectl create -f ./tei-deployment.yaml
sleep 5
kubectl create -f ./tei-service.yaml
sleep 5
echo "Embeddings URL is: <http://$>(kubectl get svc tei-service -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')"上方的代码将创建一个集群、一个部署(即我们的 TEI 服务器)和一个负载均衡器服务器。
您可以在 仓库中 查看 yaml 配置,并根据需要进行编辑。
注意: 请务必记下最后打印出的 URL!如果您忘记了,可以在 AWS 的 EKS 页面中找到该 URL。您需要的是负载均衡器的外部 IP。
步骤 3:部署 RabbitMQ
RabbitMQ 是我们将用于排队待摄取文档的地方。RabbitMQ 是一个消息代理系统,可以实现强大而简单的任务排队。由于某些摄取任务(如元数据提取、嵌入)可能很慢,使用 REST API 这种更幼稚的方法会在处理数据时保持连接开放。相反,使用队列使我们能够快速上传数据并将处理卸载到可扩展的消息消费者。它还使我们可以轻松地添加并行性,在我们的系统中,每个 Document 对象由一个消费者独立处理。
在 EKS 上部署 RabbitMQ 有点棘手,但使用通过 krew 安装的 RabbitMQ operator,许多事情都被抽象化了。
首先,您需要创建集群。出于某种原因,除非我也指定了可用区,否则这不起作用
eksctl create cluster \
--name mqCluster \
--zones us-east-1a,us-east-1b,us-east-1c,us-east-1d,us-east-1f由于 RabbitMQ 需要存储,并且每个副本需要共享相同的存储,我们应该授予集群权限来配置和使用 EBS 进行存储。这是一个令人沮丧的步骤,因为大多数现有指南都跳过了这个细节!
eksctl utils associate-iam-oidc-provider \
--cluster=mqCluster \
--region us-east-1 \
--approve
sleep 5
eksctl create iamserviceaccount \
--name ebs-csi-controller-sa \
--namespace kube-system \
--cluster mqCluster \
--role-name AmazonEKS_EBS_CSI_DriverRole \
--role-only \
--attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEBSCSIDriverPolicy \
--approve
sleep 5
eksctl create addon \
--name aws-ebs-csi-driver \
--cluster mqCluster \
--service-account-role-arn arn:aws:iam::$(aws sts get-caller-identity --query Account --output text):role/AmazonEKS_EBS_CSI_DriverRole \
--force从那里,我们可以安装 RabbitMQ operator 并创建我们的部署
kubectl apply -f <https://github.com/rabbitmq/cluster-operator/releases/latest/download/cluster-operator.yml>
sleep 5
kubectl apply -f rabbitmqcluster.yaml
sleep 5
echo "RabbitMQ URL is: $(kubectl get svc production-rabbitmqcluster -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')"像往常一样,所有这些代码都可以在 git 仓库中 找到。
注意: 请务必记下最后打印出的 URL!如果您忘记了,可以在 AWS 的 EKS 页面中找到该 URL。您需要的是负载均衡器的外部 IP。
您可以通过访问“<rabbitmq_url>:15672”并使用“guest”/“guest”登录来监控您的 RabbitMQ 队列。
步骤 4:部署 IngestionPipeline Worker
这是真正的工作重点所在。我们需要创建一个 consumer,它将不断地从我们的 RabbitMQ 队列中拉取数据,借助 TEI 摄取数据,然后将这些数据放入我们的向量数据库中。
为此,我们可以创建一个 FastAPI 服务器,它做两件事
- 启动一个线程从我们的队列中消费
- 启动一个 Web 服务器,以便我们能够指定就绪检查,并为将来添加更多功能留出空间(例如,探测队列状态、日志等)
首先,我们编写代码,如您在 worker.py 中所见
然后,我们通过创建一个简单的 Dockerfile 并运行以下命令来将我们的应用 Docker 化
docker build -t <image_name> .
docker tag <image_name>:latest <image_name>:<version>
docker push <image_name>:<version>将我们的应用 Docker 化后,我们可以通过填写以下内容来完成 worker-deployment.yaml 文件
TEI_URL下的嵌入 URLRABBITMQ_URL下的 RabbitMQ URL- 容器镜像下的镜像名称
- 集群详细信息(在本例中为 Weaviate URL 和 API 密钥)
完成 yaml 文件后,现在我们可以正确部署 Worker
eksctl create cluster --name mq-workers --zones us-east-1a,us-east-1b,us-east-1c,us-east-1d,us-east-1f
sleep 5
kubectl create -f ./worker-deployment.yaml
sleep 5
kubectl create -f ./worker-service.yaml步骤 5:创建面向用户的 Lambda 函数
我们的 Lambda 函数将依赖于一个外部依赖项 — pika — 用于与 RabbitMQ 通信。
创建一个名为 lambda_function.py 的 Python 文件,其中包含以下代码
import pika
import json
def lambda_handler(event, context):
try:
body = json.loads(event.get('body', '{}'))
except:
body = event.get('body', {})
user = body.get('user', '')
documents = body.get('documents', [])
if not user or not documents:
return {
'statusCode': 400,
'body': json.dumps('Missing user or documents')
}
credentials = pika.PlainCredentials("guest", "guest")
parameters = pika.ConnectionParameters(
host="hostname.amazonaws.com",
port=5672,
credentials=credentials
)
connection = pika.BlockingConnection(parameters=parameters)
channel = connection.channel()
channel.queue_declare(queue='etl')
for document in documents:
data = {
'user': user,
'documents': [document]
}
channel.basic_publish(
exchange="",
routing_key='etl',
body=json.dumps(data)
)
return {
'statusCode': 200,
'body': json.dumps('Documents queued for ingestion')
}上述函数处理传入请求,并将每个文档作为单个消息发布到我们的 RabbitMQ 集群中。
要部署带依赖项的 Lambda 文件,我们需要创建 Lambda 函数 + 所有依赖项的 zip 文件。为此,我们可以创建一个包含依赖项的 requirements.txt 文件,然后运行
pip install -r requirements.txt -t .
zip -r9 ../ingestion_lambda.zip . -x "*.git*" "*setup.sh*" "*requirements.txt*" "*.zip*"准备好代码和 zip 文件后,在浏览器中前往 Lambda AWS 页面。
- 选择
Create function(创建函数) - 为其命名,选择一个 Python 运行时(我使用了 Python 3.11)
- 点击底部的
Create function(创建函数) - 在代码编辑器中,您将看到一个
Upload from(上传来源)按钮 — 点击它,然后上传您的 zip 文件 - 点击测试,为测试命名,并粘贴以下 JSON
{
"body": {"user": "Test", "documents": [{"text": "test"}]}
}测试通过后,Deploy(部署)按钮将不再是灰色,您可以点击它。
您的公共 URL 将列在右上角的 Function URL(函数 URL)下 — 这是您可以从任何地方调用您的 Lambda 函数的 URL!
步骤 6:享受扩展带来的好处
现在,我们可以端到端运行我们的系统了!
要摄取数据,您可以运行
import requests
from llama_index import Document, SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
# this will also be the namespace for the vector store
# -- for weaviate, it needs to start with a captial and only alpha-numeric
user = "Loganm"
# upload in batches
for batch_idx in range(0, len(documents), 30):
documents_batch = documents[batch_idx:batch_idx+30]
body = {
'user': user,
'documents': [doc.json() for doc in documents_batch]
}
# use the URL of our lambda function here
response = requests.post("<lambda_url>", json=body)
print(response.text)然后,使用我们的数据
from llama_index import VectorStoreIndex
from llama_index.vector_stores import WeaviateVectorStore
import weaviate
auth_config = weaviate.AuthApiKey(api_key="...")
client = weaviate.Client(url="...", auth_client_secret=auth_config)
vector_store = WeaviateVectorStore(weaviate_client=client, class_prefix="<user>")
index = VectorStoreIndex.from_vector_store(vector_store)步骤 7:清理
AWS 很难估算所有这些的成本。但在运行和测试了几天后,我只花了大约 40 加元。这包括让一些服务整夜运行(哎呀!)。
完成部署后,您需要删除资源,以免为您不使用的东西付费。要删除我的集群,我运行了以下命令
eksctl delete cluster embeddings
eksctl delete cluster mq-worker
kubectl rabbitmq delete production-rabbitmqcluster然后,我在 AWS UI 控制台中删除了 EC2 和 CloudFormation 页面上剩余的任何资源,并仔细检查了 EKS 页面上是否所有内容都已删除。
结论
使用这种设置,我能够大幅缩短创建大型索引的构建时间。之前,为 2.5 万份文档创建索引大约需要 10-20 分钟,而使用此设置(2 个 RabbitMQ 节点、2 个 Worker、2 个嵌入),时间缩短到了 5 分钟!通过进一步扩展,还可以更快。
后续步骤
在此基础上,我想到了几个改进点
- 更好的密钥管理
- 添加自动扩展
- 添加检索 Lambda 函数(需要为 Lambda + LlamaIndex 创建 Docker 镜像)
- 向 FastAPI 服务器添加队列状态
- 在 IngestionPipeline 上部署 Redis 用于文档管理
我鼓励任何人在此基础上进行开发和改进。请务必将任何改进分享到 GitHub 仓库中!



