
Jerry Liu • 2024-02-20
介绍 LlamaCloud 和 LlamaParse
今天是 LlamaIndex 生态系统的重要日子:我们宣布推出 LlamaCloud,新一代托管解析、摄取和检索服务,旨在为您的 LLM 和 RAG 应用带来生产级的语境增强能力。
作为企业 AI 工程师,使用 LlamaCloud,您可以专注于编写业务逻辑,而不是数据处理。处理大量生产数据,即刻提高响应质量。LlamaCloud 包含以下关键组件:
- LlamaParse: 专有解析服务,用于解析包含嵌入对象(如表格和图表)的复杂文档。LlamaParse 直接集成 LlamaIndex 的摄取和检索功能,让您能够对复杂、半结构化文档进行检索。您将能够回答之前无法解决的复杂问题。
- 托管摄取和检索 API: 一个 API,允许您轻松加载、处理和存储用于 RAG 应用的数据,并以任何语言使用。由 LlamaHub 中的数据源(包括 LlamaParse)以及我们的数据存储集成提供支持。
LlamaParse 从今天开始提供公开预览。目前支持 PDF,且公共使用有上限;如需商业条款,请联系我们。托管摄取和检索 API 提供私有预览;我们仅提供给有限的企业设计合作伙伴。如果您感兴趣,请联系我们。(我们还推出了一个新版网站 🦙!)
RAG 的好坏取决于您的数据
LLM 的核心承诺之一是能够自动化对任何非结构化数据源进行知识搜索、合成、提取和规划。在过去一年里,出现了一个新的数据堆栈,用于支持这些语境增强的 LLM 应用,通常称为检索增强生成 (RAG)。这个堆栈包括加载数据、处理数据、嵌入数据,然后加载到向量数据库中。这使得下游可以编排检索和提示,从而在 LLM 应用中提供语境。
这个堆栈与之前的任何 ETL 堆栈都不同,因为与传统软件不同,数据堆栈中的每个决策都直接影响整个 LLM 系统的准确性。诸如块大小和嵌入模型等每个决策都会影响 LLM 的输出,而且由于 LLM 是黑箱,您无法通过单元测试来确保其行为正确。
过去一年里,我们一直在努力工作,处于提供工具和教育用户如何为各种用例构建高性能、先进 RAG 的前沿。我们的月下载量已突破 200 万次,并被从大型企业到初创公司广泛使用,包括 Adyen、T-Systems、Jasper.ai、Weights and Biases、DataStax 等等。
但是,虽然使用我们著名的 5 行入门示例很容易,但构建生产级 RAG 仍然是一个复杂而微妙的问题。在我们与数百名用户的交流中,我们了解到最大的痛点是:
- 结果不够准确: 应用无法为长尾输入任务/查询生成令人满意的结果。
- 要调整的参数过多: 在数据解析、摄取、检索等环节,不清楚应该调整哪些参数。
- PDF 尤其 problematic: 我有很多格式混乱的复杂文档。如何正确地表示这些文档,以便 LLM 能够理解?
- 数据同步是一个挑战: 生产数据经常更新,持续同步新数据带来了一系列新的挑战。
这些正是我们着手用 LlamaCloud 解决的问题。
助您实现生产就绪的数据管道
我们构建了 LlamaCloud 和 LlamaParse 作为数据管道,以帮助您的 RAG 应用更快地投入生产。
LlamaParse
LlamaParse 是一款最先进的解析器,专为解锁对包含嵌入表格和图表的复杂 PDF 进行 RAG 而设计。这在之前通过其他方法根本无法实现,我们对此技术感到非常兴奋。
在过去的几个月里,我们一直专注于这个问题。这是一个在各种数据类型和垂直领域(从 ArXiv 论文到 10K 文件再到医疗报告)中都出奇普遍的用例。
简单的分块和检索算法效果很差。我们率先提出了一种新颖的递归检索 RAG 技术,用于分层索引和查询文档中的表格和文本。唯一剩下的挑战是如何首先正确地解析出表格和文本。
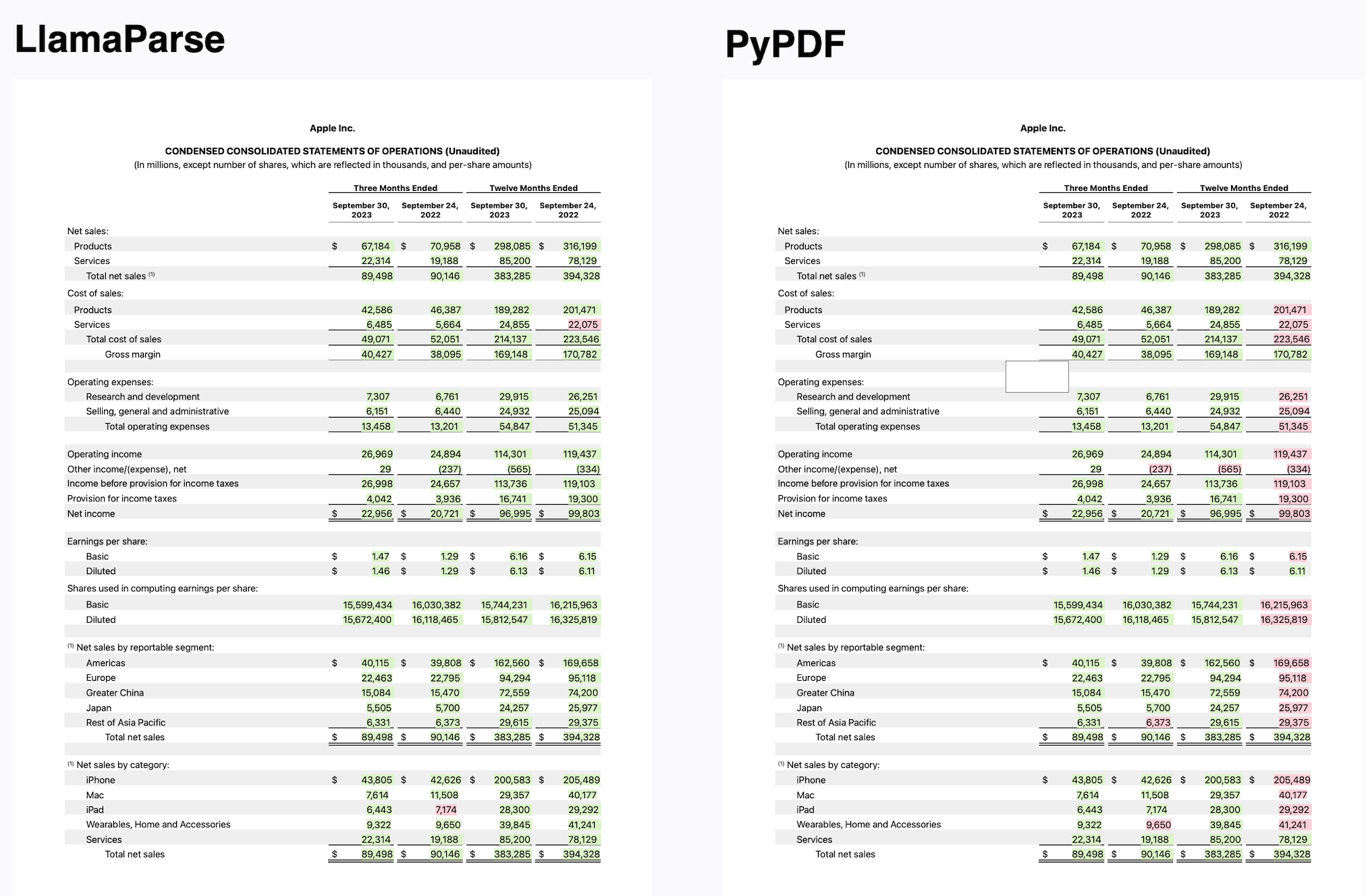
这就是 LlamaParse 的用武之地。我们开发了一种专有的解析服务,它在将包含复杂表格的 PDF 解析成结构良好的 Markdown 格式方面表现出色。这种表示形式直接与开源库中提供的高级 Markdown 解析和递归检索算法结合。最终结果是,您能够构建对复杂文档进行 RAG 的能力,这些文档可以回答关于表格数据和非结构化数据的问题。请参阅下面的结果进行比较


此服务以公开预览模式提供:面向所有人开放,但有使用限制(每天 1k 页)。它可以作为独立服务运行,也可接入我们的托管摄取和检索 API(见下文)。请在此查看我们的 LlamaParse 入门指南了解更多详情。
from llama_parse import LlamaParse
parser = LlamaParse(
api_key="llx-...", # can also be set in your env as LLAMA_CLOUD_API_KEY
result_type="markdown", # "markdown" and "text" are available
verbose=True
)如需 LlamaParse 的无限商业使用,请联系我们。
后续步骤
我们的早期用户已经就他们接下来想看到的功能提供了重要的反馈。目前我们主要支持包含表格的 PDF 文件,但我们也在构建对图表更好的支持,并扩展支持最流行的文档类型:.docx、.pptx、.html。
托管摄取与检索
我们在 LlamaCloud 中的另一项主要产品是托管摄取和检索 API,它允许您轻松声明用于任何语境增强型 LLM 应用的高性能数据管道。
为您的 LLM 应用获取干净的数据,这样您可以花费更少的时间处理数据,更多的时间编写核心应用逻辑。LlamaCloud 为企业开发者提供以下优势:
- 节省工程时间: 无需在 Python 中编写自定义连接器和解析逻辑,我们的 API 允许您直接连接到不同的数据源。
- 性能: 我们为不同数据类型提供良好的开箱即用性能,同时提供直观的路径进行实验、评估和改进。
- 简化系统复杂性: 处理大量数据源的增量更新。
让我们快速浏览一下核心组件!
- 摄取: 声明一个托管管道,用于处理、转换/分块/嵌入数据,支持我们在 LlamaHub 中的 150 多个数据源以及 40 多个存储集成作为目的地。自动处理同步和负载均衡。可通过 UI 或我们的开源库定义。
- 检索: 通过我们的开源库和您的数据存储,访问最先进的高级检索功能。将其封装在一个易于使用的 REST API 中,您可以用任何语言调用。
- Playground: 交互式 UI,用于在部署前测试和优化您的摄取/检索策略,并包含评估反馈。
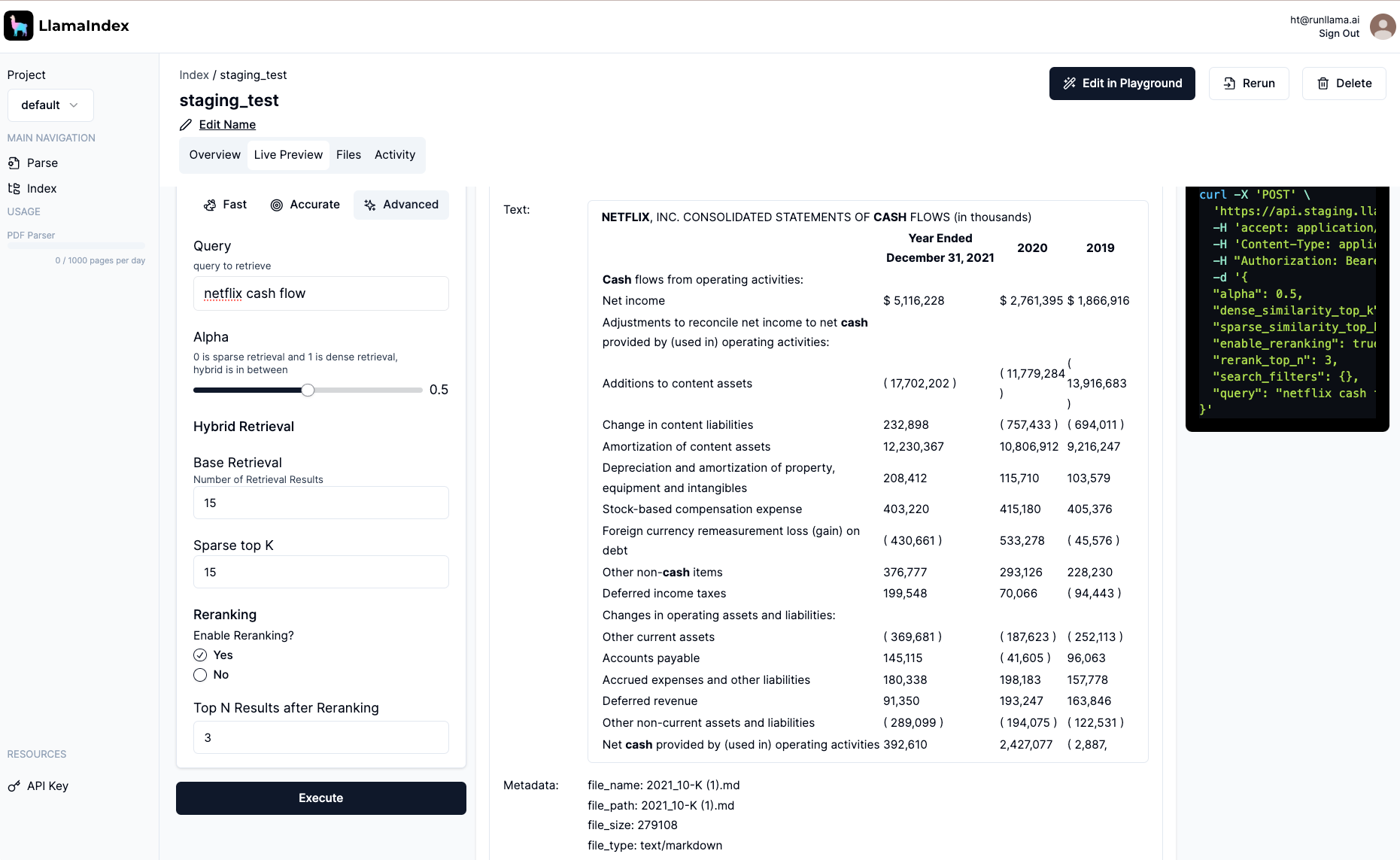
我们正在向有限数量的企业合作伙伴开放托管摄取和检索 API 的私有测试版。如果您有兴趣集中管理数据管道,并将更多时间花在实际的 RAG 用例上,请联系我们。
启动合作伙伴与合作者
我们在二月初与 Futureproof Labs 和 Datastax 共同举办的黑客马拉松中开放了 LlamaParse 的使用权限。我们看到了 LlamaParse 在实际应用中的一些令人惊叹的用例,包括解析附属居住单元 (ADU) 规划的建筑规范,解析购房的房地产披露文件,以及数十个其他用例。
Mendable AI 的联合创始人 Eric Ciarla 将 LlamaParse 集成到 Mendable 的数据堆栈中:“我们将 LlamaParse 集成到了我们的开源数据连接器仓库,它为我们的生产摄取套件提供支持。它易于集成,并且比我们尝试过的任何替代方案都更强大。”
我们也激动地宣布,在 LLM 和 AI 生态系统中,从存储到计算领域的首批启动合作伙伴和合作者加入了我们。
DataStax
DataStax 已将 LlamaParse 集成到他们的 RAGStack 中,为企业带来隐私保护的即用型 RAG 解决方案:DataStax 首席技术官兼执行副总裁 Davor Bonaci 表示:“上周,我们的一家客户 Imprompt 推出了一个开创性的‘Chat-to-Everything’平台,该平台利用由 LlamaIndex 提供支持的 RAGStack,在优先考虑隐私的同时增强其企业服务。我们非常高兴能与 LlamaIndex 合作,将一个简化的解决方案推向市场。通过将 LlamaIndex 集成到 RAGStack 中,我们为企业开发者提供了一个全面的 Gen AI 堆栈,该堆栈简化了 RAG 实现的复杂性,同时提供长期支持和兼容性保证。”
MongoDB
MongoDB 人工智能生态系统全球负责人 Greg Maxson 表示:“MongoDB 与 LlamaIndex 的合作允许将数据摄取到 MongoDB Atlas Vector 数据库中,并通过 LlamaParse 和 LlamaCloud 从 Atlas 检索索引,从而支持 RAG 系统和其他 AI 应用的开发。现在,开发者可以抽象数据摄取相关的复杂性,简化 RAG 管道实现,并更具成本效益地开发大型语言模型应用,最终加速生成式 AI 应用的开发并更快地将应用推向市场。”
Qdrant
Qdrant 首席执行官 André Zayarni 表示:“Qdrant 团队很高兴能与 LlamaIndex 合作,将最优数据预处理、向量化和摄取能力与 Qdrant 相结合,共同打造强大的全栈 RAG 解决方案。”
NVIDIA
我们也很高兴与 NVIDIA 合作,将 LlamaIndex 与用于生产 AI 的 NVIDIA AI Enterprise 软件平台集成:NVIDIA 企业计算和边缘计算副总裁 Justin Boitano 表示:“LlamaCloud 将通过连接专有数据与大型语言模型的强大能力,帮助企业将生成式 AI 应用从开发推向生产。将 LlamaCloud 与 NVIDIA AI Enterprise 结合使用,可以加速端到端 LLM 管道——包括在跨云、数据中心和边缘的加速计算上进行数据处理、嵌入创建、索引和模型推理。”
常见问题
这与向量数据库有竞争关系吗?
不是。LlamaCloud 主要专注于数据解析和摄取,这是对任何向量存储提供商的补充层。检索层是建立在现有存储系统之上的编排层。LlamaIndex 开源版本与 40 多个最流行的向量数据库集成,我们正在努力做以下事情:
- 将 LlamaCloud 与现有设计合作伙伴的存储提供商集成
- 以更“自助”的方式提供 LlamaCloud。
后续步骤
如上文所述,LlamaParse 从今天开始提供公开预览,有使用上限。LlamaCloud 处于私有预览模式;我们正在向有限数量的企业设计合作伙伴提供访问权限。如果您感兴趣,请联系我们!
LlamaCloud:联系我们



