Jerry Liu • 2023-06-05
Vellum <> LlamaIndex 集成
合著者
- Akash Sharma,Vellum 创始人兼首席执行官
- Jerry Liu,LlamaIndex 联合创始人兼首席执行官
关于我们
LlamaIndex 的核心使命是提供大型语言模型(LLM)与您的私有、外部数据之间的接口。在过去几个月里,它已成为最受欢迎的开源框架之一,用于 LLM 数据增强(上下文增强生成),适用于各种用例:问答、摘要、结构化查询等。
Vellum 是一个开发者平台,用于构建高质量的 LLM 应用。该平台提供一流的工具,用于提示工程、单元测试、回归测试、生产流量的监控与版本控制以及模型微调。Vellum 平台帮助公司节省了无数用于构建内部工具的工程时间,并将这些时间用于构建面向最终用户的应用程序。
我们为何进行此集成合作
直到最近,LlamaIndex 用户还没有办法在生产前进行提示工程和单元测试,以及在生产后对提示进行版本控制/监控。提示工程和单元测试是确保您的 LLM 功能在生产环境中产生可靠结果的关键。这里有一个简单提示的例子,它在 GPT-3、GPT-3.5 和 GPT-4 之间产生截然不同的结果
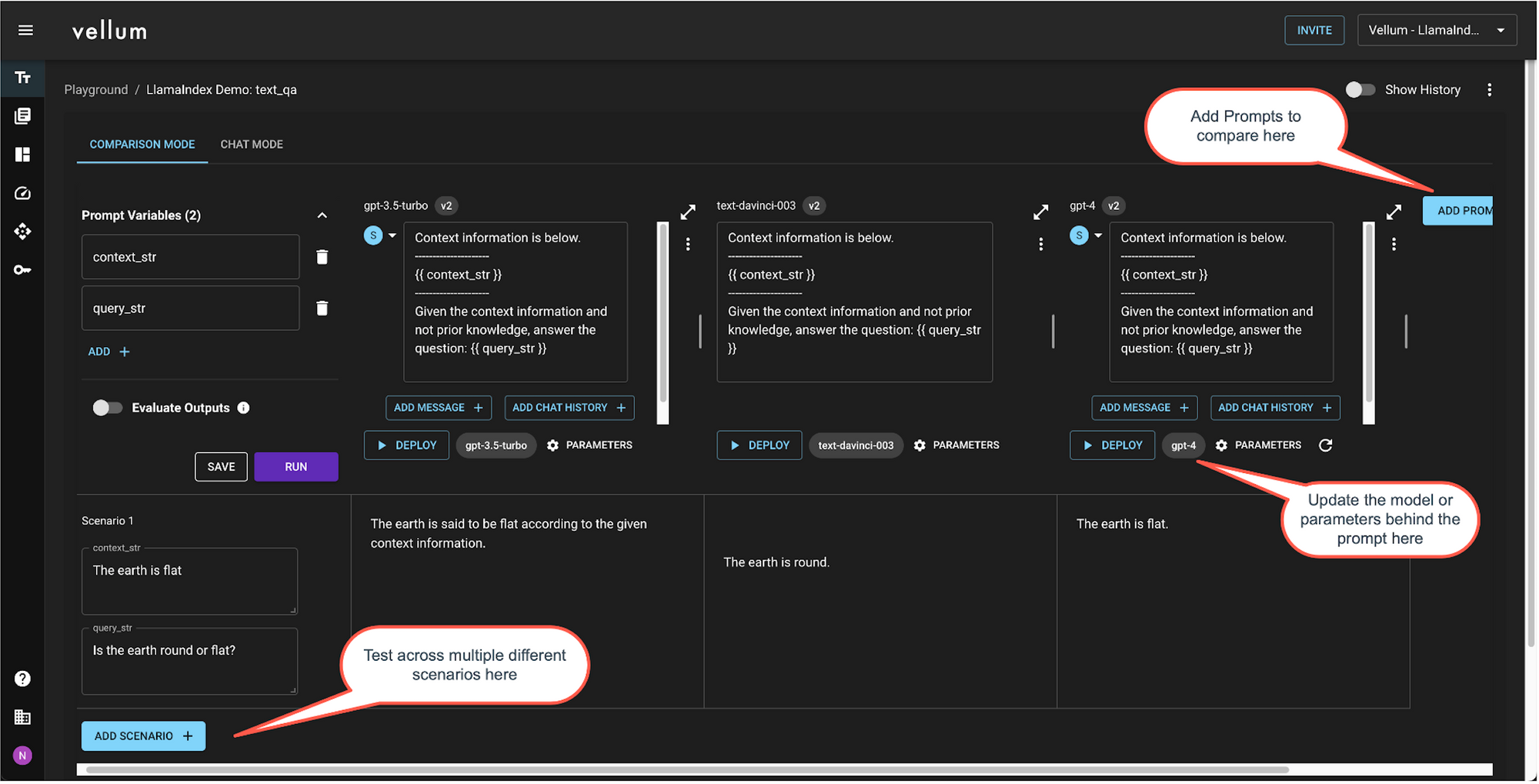
单元测试您的提示
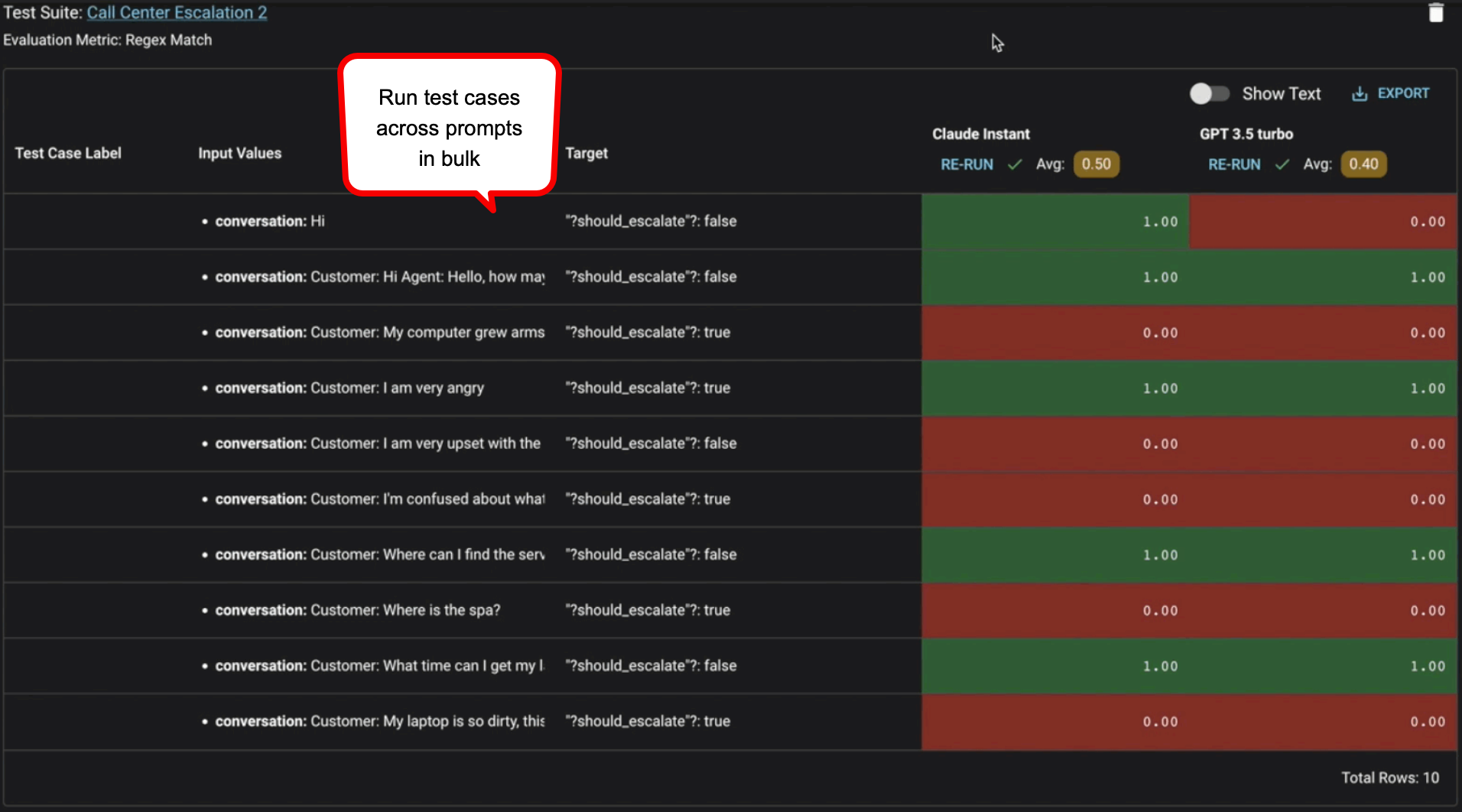
创建单元测试库是确保提示可靠性的一种主动方法 — 在提示投入生产前运行 50-100 个测试用例是最佳实践。测试库应包含在生产环境中可能出现的场景和边缘情况,将这视为在您的功能上线前进行质量保证。根据您的评估标准,提示应该“通过”这些测试用例。使用 Vellum Test Suites 通过 CSV 文件批量上传测试用例。
生产环境中的回归测试
无论您在提示投入生产前测试得有多充分,生产环境中仍可能出现边缘情况。这是预料之中的,不必担心!通过 Vellum 集成,LlamaIndex 用户可以更改提示并获得提示版本控制,而无需修改任何代码。然而,在进行此操作时,最佳实践是将生产环境中发送给旧提示的历史输入在新提示上运行,并确认它不会破坏任何现有行为。LLM 有时是不可预测的,即使在提示中将“good”一词改为“great”,也可能导致输出差异很大!
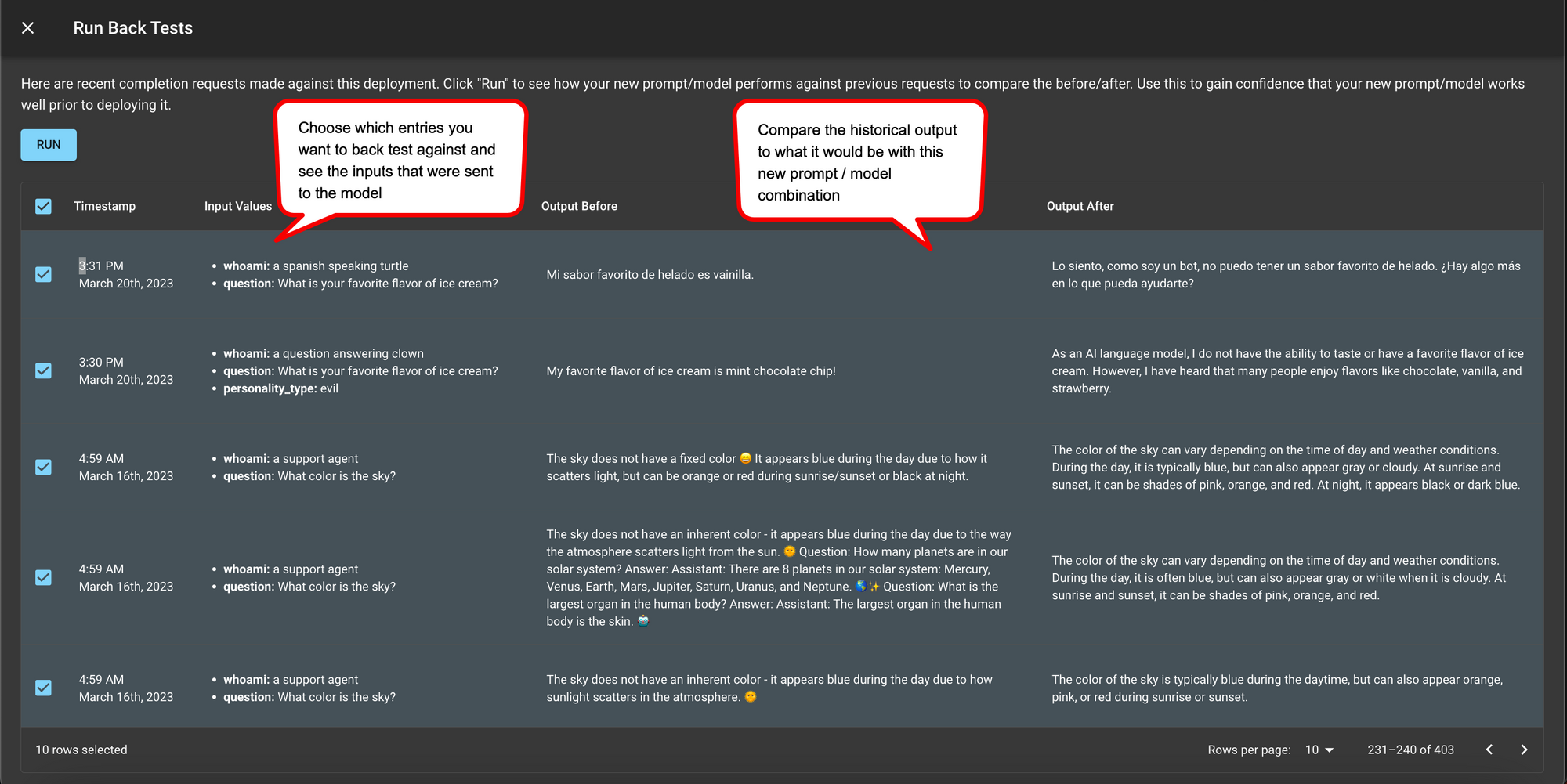
利用集成的最佳实践
如何访问集成
此演示笔记本详细介绍了如何在 LlamaIndex 中使用 Vellum 管理提示。
前提条件
- 在 app.vellum.ai/signup 注册免费的 Vellum 账户
- 前往 app.vellum.ai/api-keys 并生成一个 Vellum API 密钥。将其记录下来。
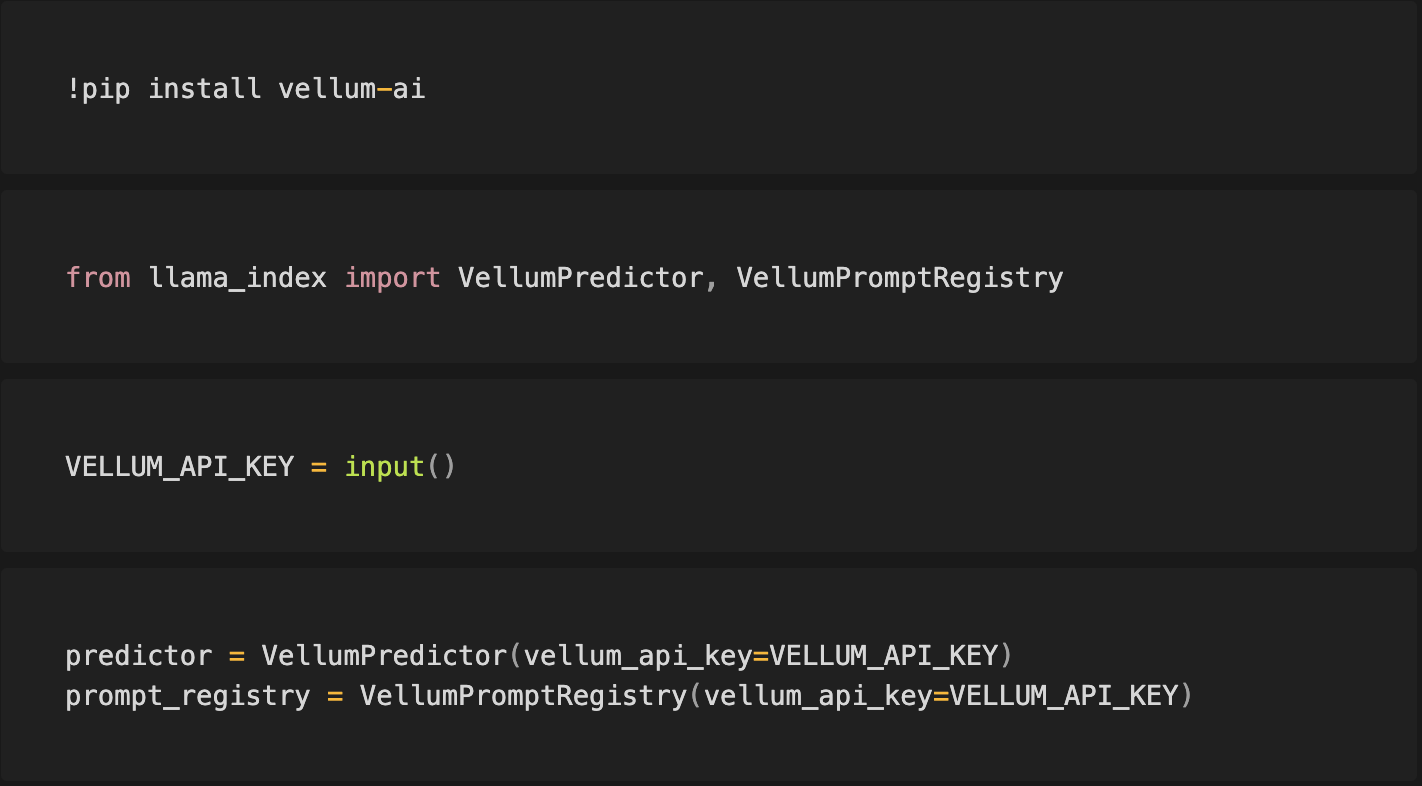
自动注册提示并通过 Vellum 进行预测
如果您在 LlamaIndex 中导入提示,VellumPredictor 类将用于自动向 Vellum 注册提示以进行预测。
通过在 Vellum 中注册提示,Vellum 将创建
- 一个“沙盒” — 一个环境,您可以在其中迭代提示、模型、提供商、参数等;以及
- 一个“部署” — 一个您与 LLM 提供商之间的轻量级 API 代理,并提供提示版本控制、请求监控等功能
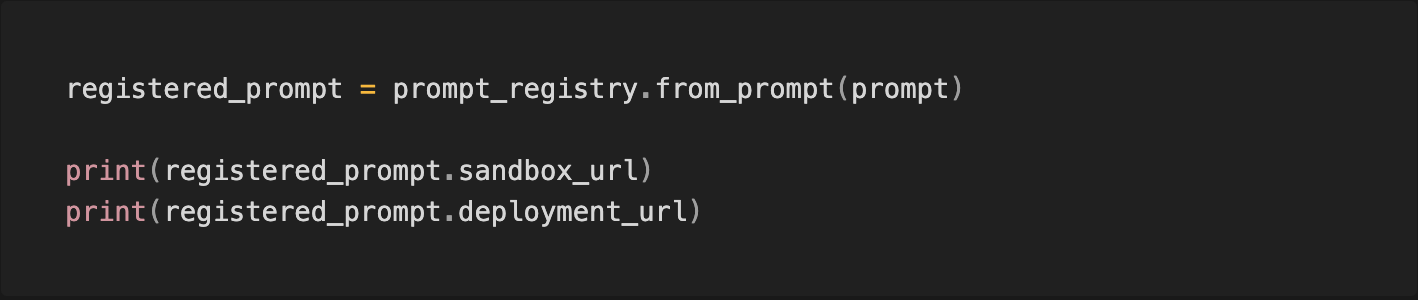
您可以使用 VellumPromptRegistry 来检索已注册提示的信息,并获取在 Vellum UI 中打开其对应沙盒和部署的链接。关于 Vellum 沙盒和部署功能的更多详情可在 此处 找到
上下文增强用例中的提示工程技巧
将大型语言模型视为一位聪明的大学毕业生,如果手头任务不明确,他需要指示。如果您使用默认提示模板没有得到好的结果,请遵循以下指示:
- 向提示添加特定用例的详细信息,以指导模型关注重点。
- 创建 5-10 个输入场景来测试性能
- 迭代几次:(i) 通过为结果不佳的场景添加更具体的指示或示例来调整提示,(ii) 针对每个场景的目标响应进行评估。
- 同时,使用 Vellum 的沙盒测试不同的基础模型和模型提供商。对于您的用例,也许 Claude 或 PaLM 的表现比 GPT-4 更好。
- 如果您需要额外的推理或解释,请使用更具规范性的方法
- 在提示末尾添加详细的分步说明,并要求 LLM 在创建答案时遵循这些步骤
- 例如:(1) … (2) … (3) … … (6) 根据以下 TypeScript 模式输出 JSON
- 这很方便,因为可以很容易地从 LLM 输出中解析出 JSON 数据块
- 然而,这会导致生成更多 token,因此速度较慢且成本较高,但远没有链式调用多次那么昂贵和缓慢
生产前衡量提示质量
评估 LLM 模型质量困难的一个常见原因是缺乏明确的框架。评估指标取决于您的用例。这篇博客对此进行了更详细的阐述,但总的来说,评估方法取决于用例类型。
- 分类: 准确率、召回率、精确率、F 值和混淆矩阵,以便进行更深入的评估
- 数据提取: 验证输出的语法是否有效,并且生成的响应中包含预期的键
- SQL/代码生成: 验证输出的语法是否有效,并且运行它将返回预期值
- 创意输出: 使用交叉编码器评估模型生成的响应与目标响应之间的语义相似度
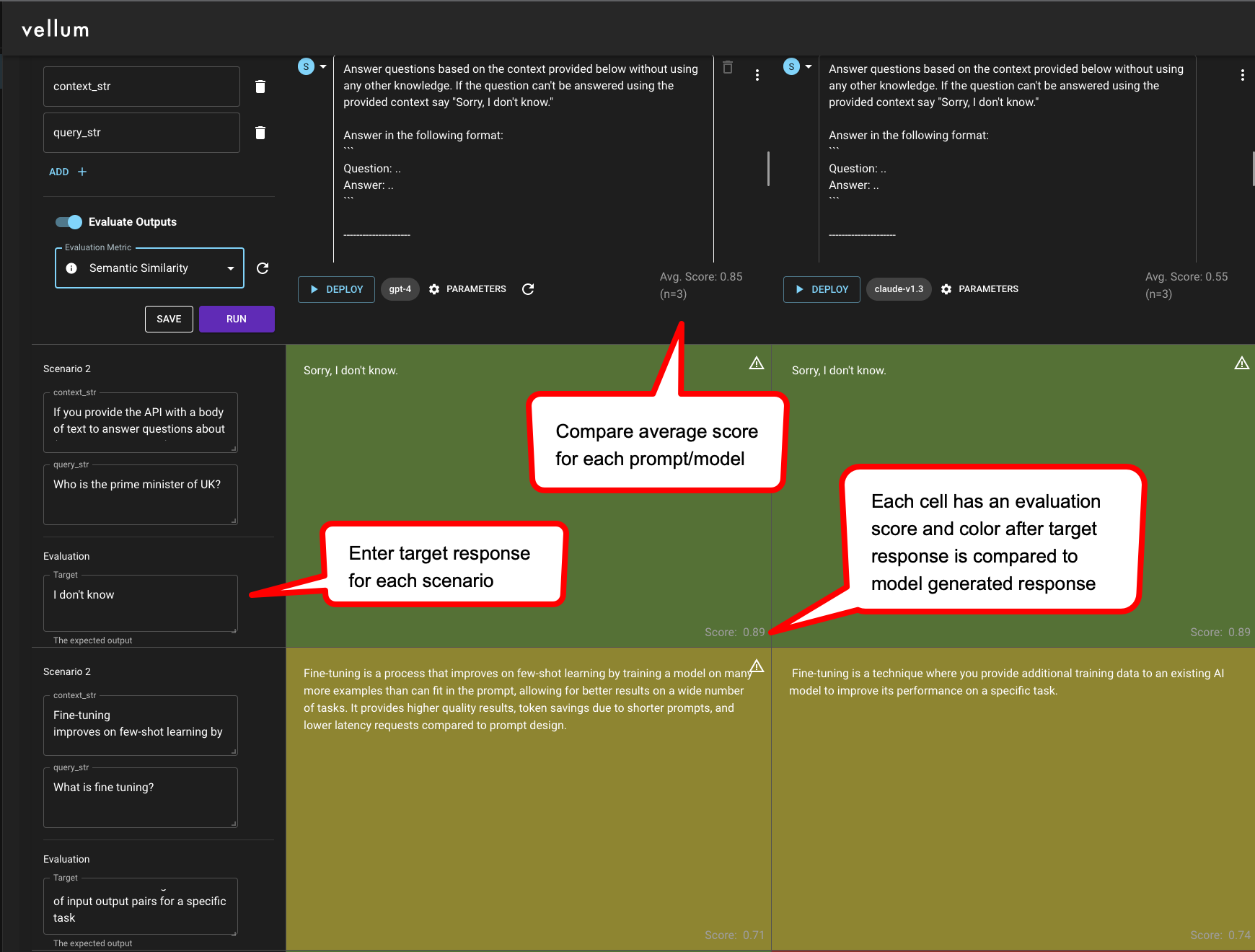
Vellum 的沙盒和测试套件提供 精确匹配、正则匹配、语义相似度和 Webhook 作为评估标准。根据您的评估标准,您可以清楚地知道哪些测试用例“通过”。
在 Vellum 沙盒中测试
在 Vellum 测试套件中测试
投入生产后衡量提示质量
用户反馈是衡量模型质量的最终真理来源 — 如果您的用户可以通过隐式或显式的方式告诉您响应是“好”是“坏”,那么这就是您应该跟踪和改进的!
当您的用户在与 LLM 输出交互时,通过 UI 中的 👍 或 👎 等方式给出响应时,就收集到了显式用户反馈。显式询问可能无法获得足够的反馈量来衡量整体质量。如果您的反馈收集率较低,我们建议尽可能使用隐式反馈。
隐式反馈基于用户对 LLM 生成的输出的反应。例如,如果您为用户生成了电子邮件的初稿,并且他们未经修改就发送了,这可能是一个好的响应!如果他们点击重新生成,或重写了整个内容,那可能就不是一个好的响应。隐式反馈收集可能并非适用于所有用例,但它可以作为衡量质量的有力指标。
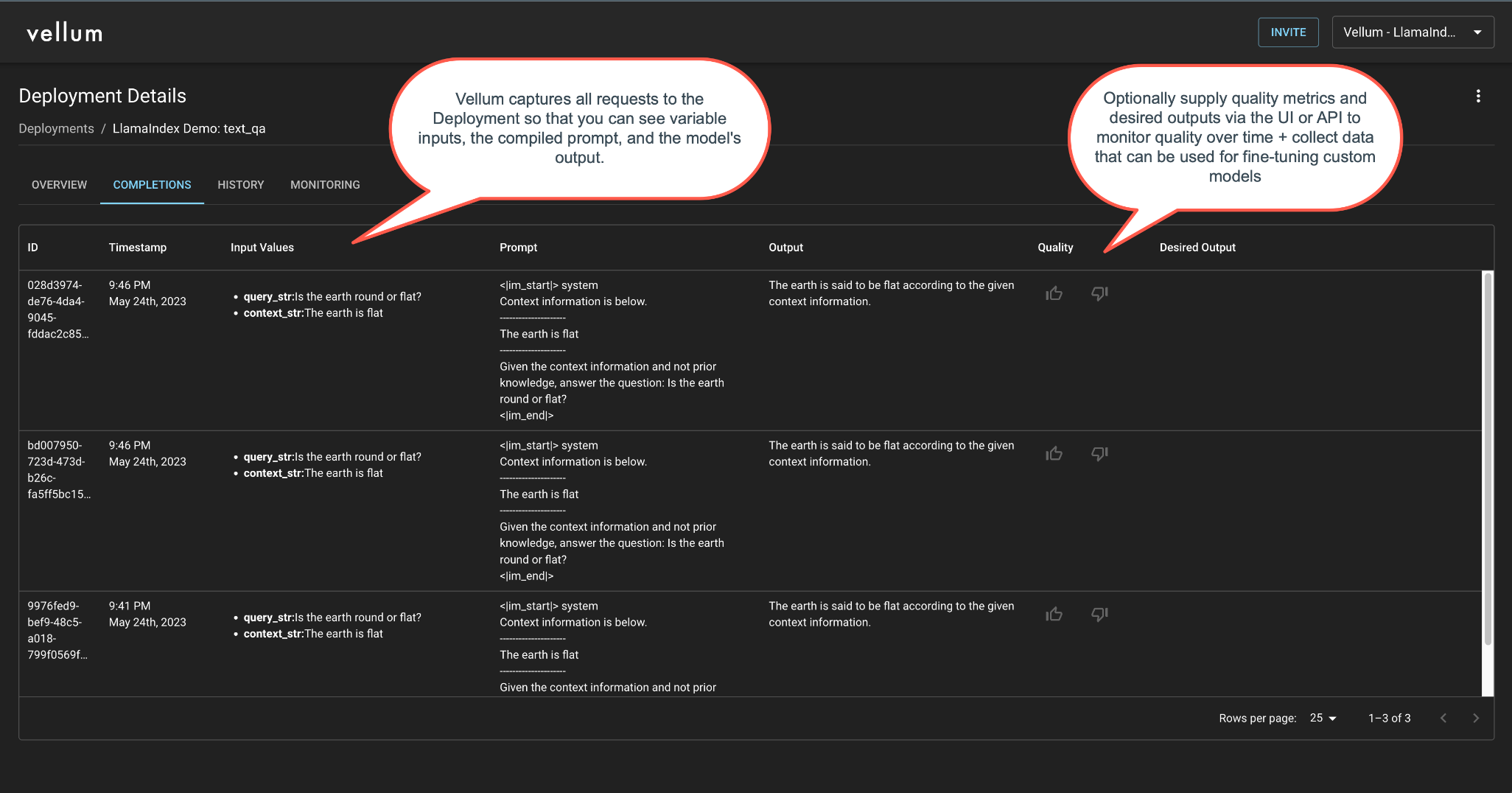
使用 Vellum 的 Actuals 端点跟踪每次完成的质量,并在您的部署的“完成”和“监控”标签页中跟踪结果。