
LlamaIndex • 2023-12-20
两个新的 llama 数据集以及一场 Gemini 对抗 GPT 的较量
(作者:LlamaIndex 的 Andrei Fajardo)
引言
几周前,我们发布了我们的第一批 llama 数据集,即 LabelledRagDataset。这些 llama 数据集的主要目的是为构建者提供有效且高效地对其 LLM 系统进行基准测试的手段。自发布以来,在短短几周内,我们通过员工和社区贡献积累了十几个 LabelledRagDataset(所有这些都可通过 LlamaHub 下载)!
然而,乐趣不止于此:今天我们推出两种新的 llama 数据集类型:LabelledEvaluatorDataset 和 LabelledPairwiseEvaluatorDataset。这些新的 llama 数据集类型旨在评估或基准测试 LLM 评估器。事实上,评估 LLM 响应的通行标准是使用强大的 LLM 作为评估器。这种方法无疑比通过众包使用人类评估器更具可伸缩性、更快且更便宜。然而,这些 LLM 评估器本身也必须持续评估,而不是盲目信任。
在本文中,我们简要概述了新的 llama 数据集,并提供了将 MT-Bench 数据集转换为新 llama 数据集类型后,使用这些数据集对 Google 的 Gemini 和 OpenAI 的 GPT 模型作为 LLM 评估器进行的基准测试的一些非常有趣的结果。
新 llama 数据集入门
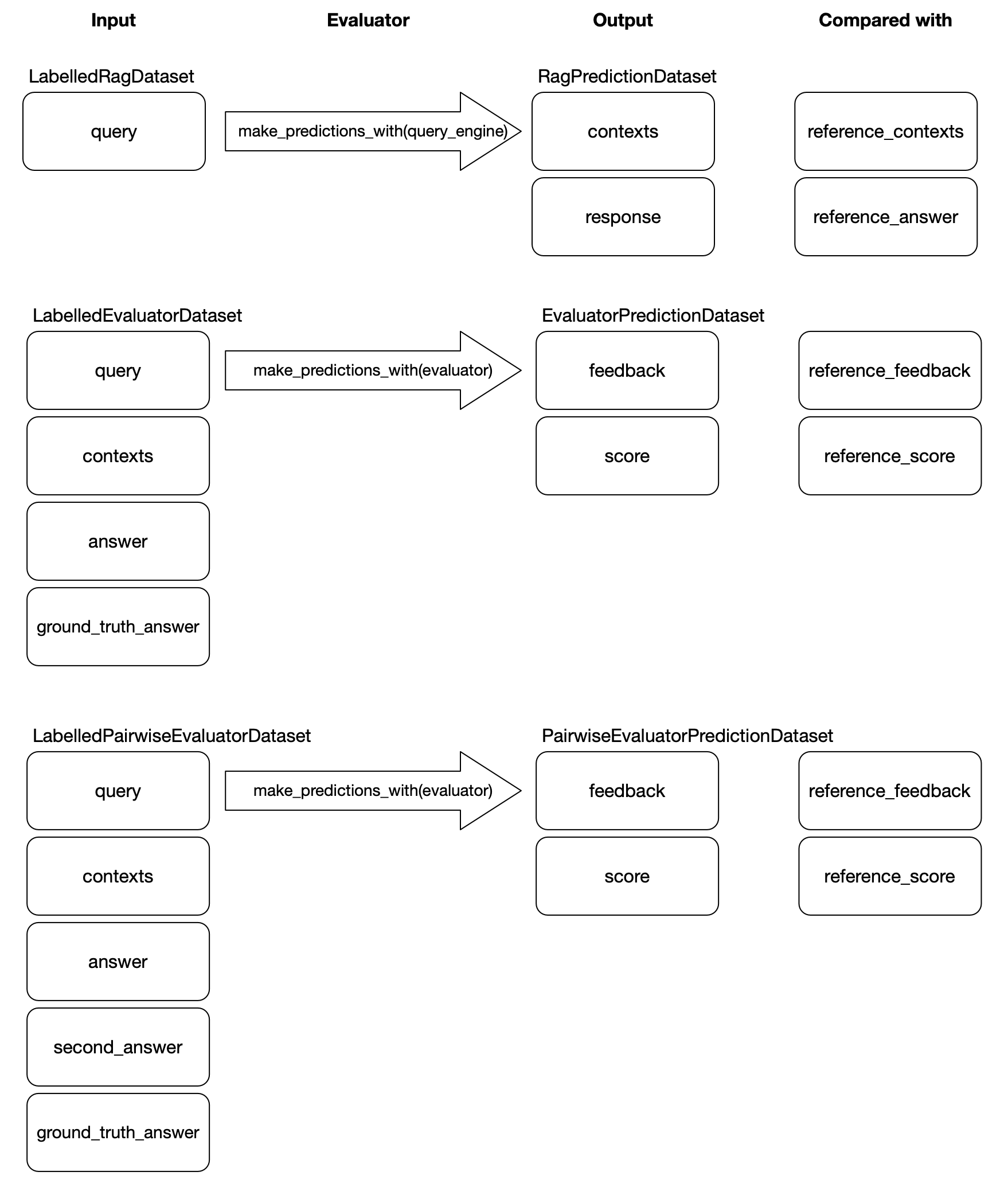
在深入了解新 llama 数据集之前,回顾一下,使用 LabelledRagDataset,我们的最终目标是将其用于评估或基准测试检索增强生成 (RAG) 系统。使用我们的 llama 数据集抽象来实现这一目标的方式是构建一个 QueryEngine(即 RAG 系统),然后使用它对 LabelledRagDataset 进行“预测”。有了预测结果,我们可以通过将其与 LabelledRagDataset 的相应参考属性进行比较来评估这些预测的质量。
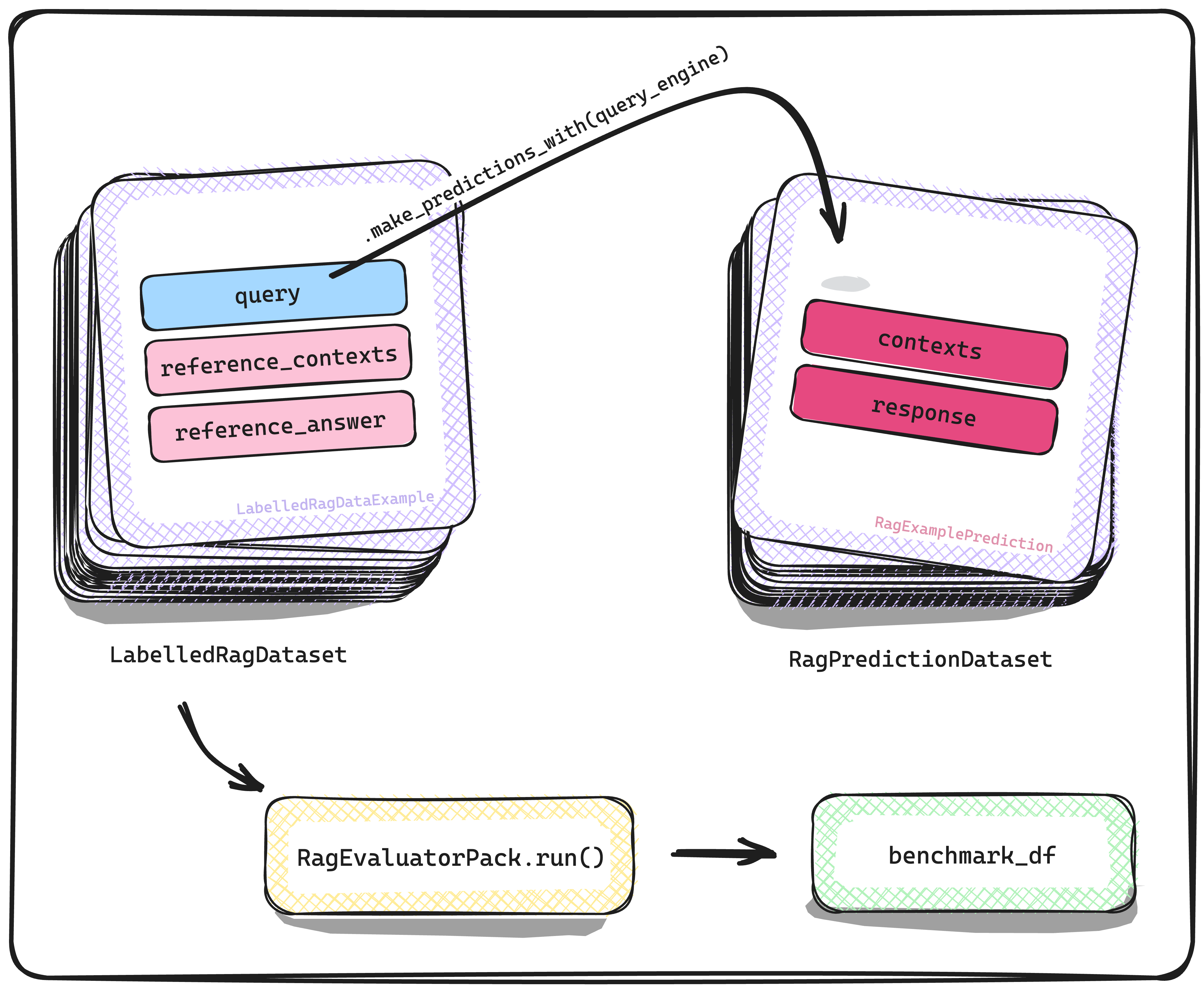
类似地,新的 llama 数据集旨在基准测试 LLM 评估器。让我们来看看第一种类型,即 LabelledEvaluatorDataset。在这里,不是 RAG 系统对 LabelledRagDataset 进行预测,而是 LLM 评估器对 LabelledEvaluatorDataset 进行“预测”——在此上下文中,“预测”意味着 LLM 评估器正在评估另一个 LLM 模型对给定查询产生的响应。与之前一样,有了预测结果,我们可以通过将其与 LabelledEvaluatorDataset 的相应参考属性进行比较来衡量 LLM 评估器评估的优劣。
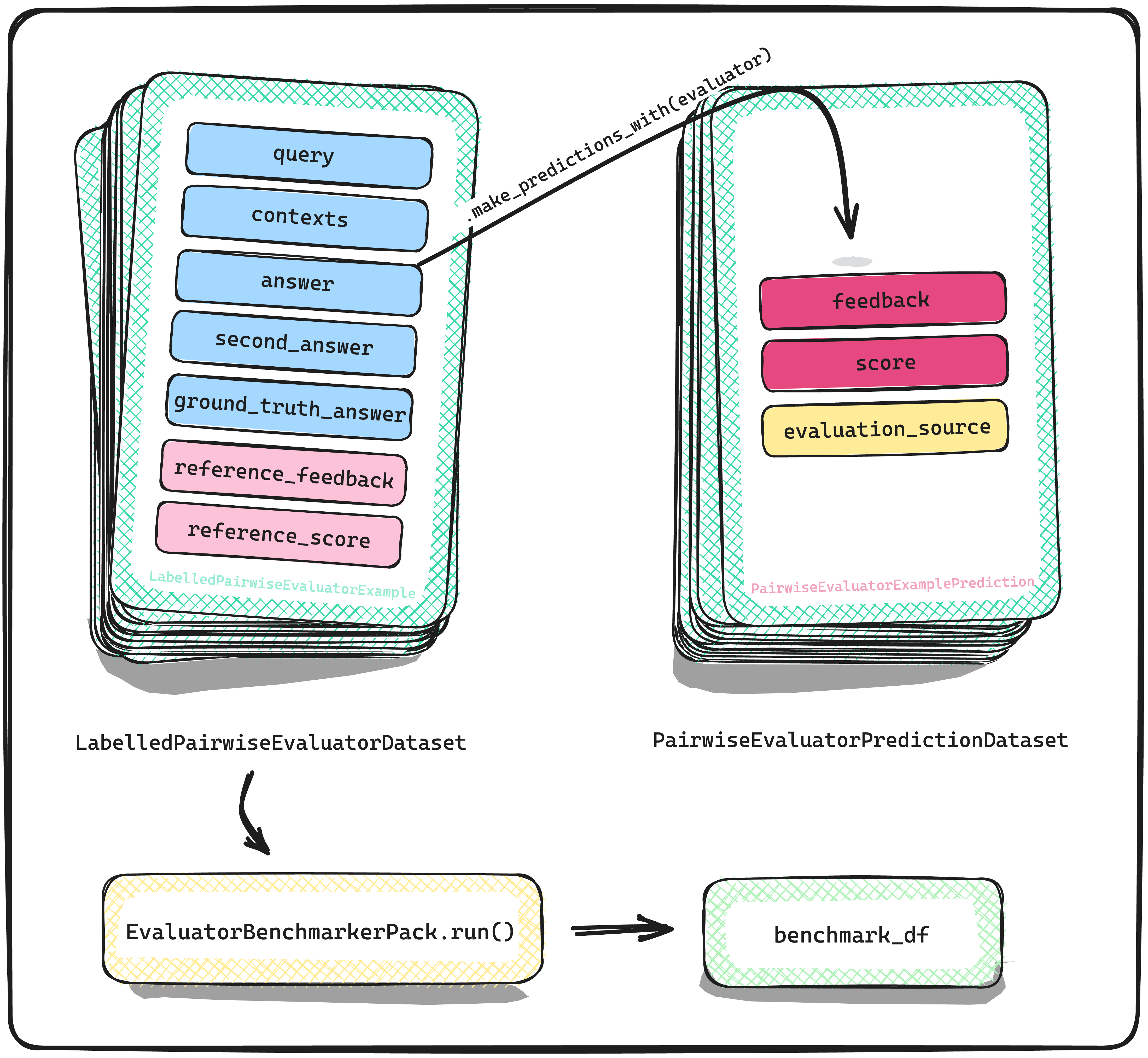
我们今天介绍的第二种 llama 数据集可以视为第一种的扩展。 LabelledPairwiseEvaluatorDataset 也同样用于基准测试 LLM 评估器。然而,评估任务上存在微妙差异,因为这里的 LLM 评估器比较来自两个不同 LLM 生成的两个答案。除了这个差异之外,使用这种 llama 数据集来基准测试评估器的流程保持不变。
将 Gemini 和 GPT 模型作为 LLM 评估器进行基准测试:Gemini 达到 GPT-3.5 的性能!
在本节中,我们将使用新的 llama 数据集类型来让 Gemini Pro 与 GPT 模型一较高下。为此,我们将使用经过稍微修改的 MT-Bench 数据集版本。这些修改后的版本已随同今天的发布一起,通过 LlamaHub 提供下载和使用!
Mini MT-Bench 单一评分数据集
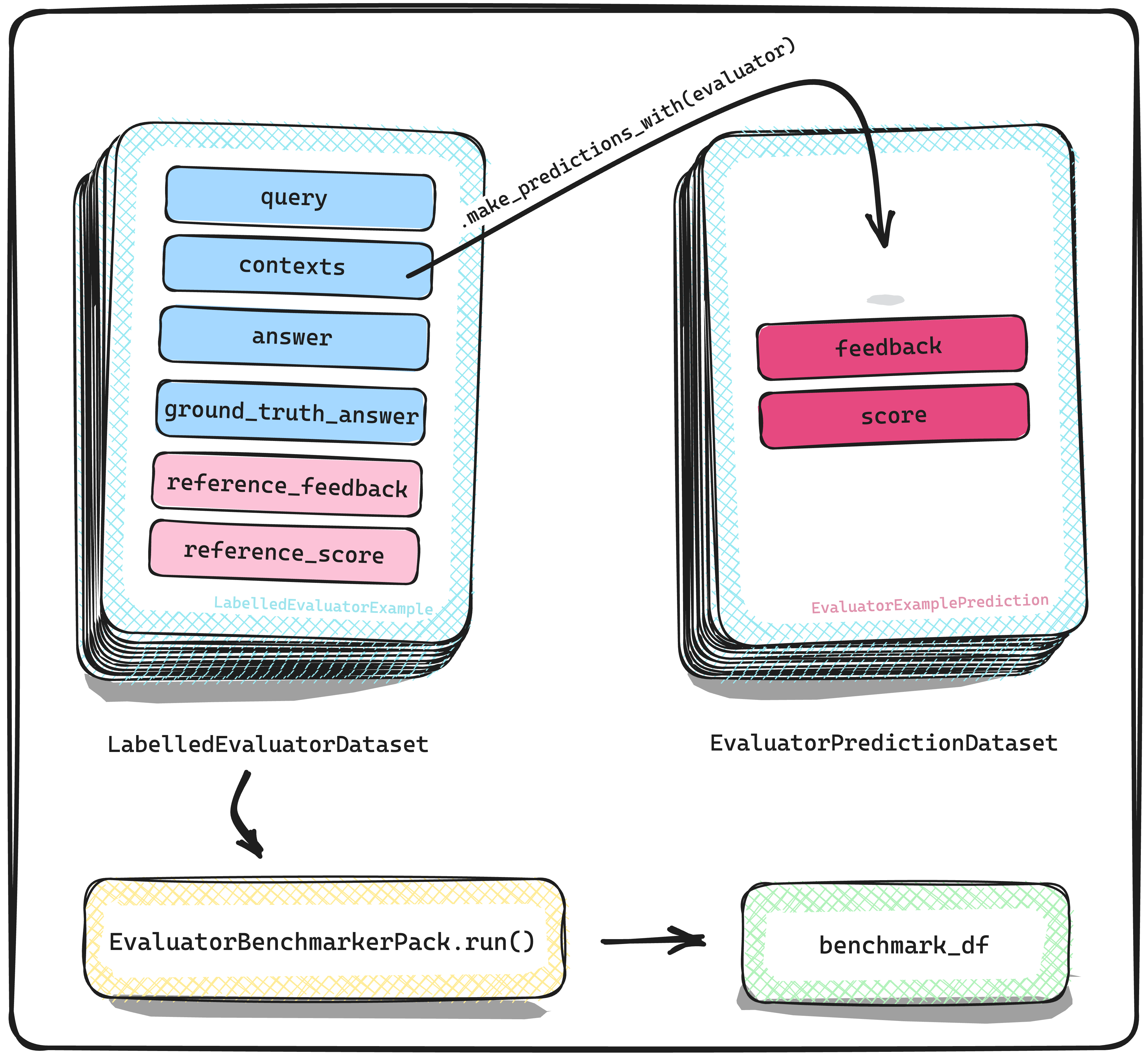
此 llama 数据集是 LabelledEvaluatorDataset 类型,是 MT-Bench 单一评分数据集的微型版本。具体来说,我们考虑所有 160 个原始问题(即 80 x 2,因为 MT Bench 是一个两轮对话问题数据集),但仅考虑由 Llama2-70b 生成的响应。对于参考评估,我们使用 GPT-4。与原始的 LabelledRagDataset 一样,我们制作了一个新的 llama-pack EvaluatorBenchmarkerPack(当然,也随同今天的发布一起提供!)以使在新的 llama 数据集上对 LLM 评估器进行基准测试相对轻松。下面的代码片段展示了如何复现此基准测试的结果
from llama_index.llama_dataset import download_llama_dataset
from llama_index.llama_pack import download_llama_pack
from llama_index.evaluation import CorrectnessEvaluator
from llama_index.llms import Gemini
from llama_index import ServiceContext# download dataset evaluator_dataset, _ = download_llama_dataset( "MiniMtBenchSingleGradingDataset", "./mini_mt_bench_data" )# define evaluator gemini_pro_context = ServiceContext.from_defaults( llm = Gemini(model="models/gemini-pro", temperature=0) ) evaluator = CorrectnessEvaluator(service_context=gemini_pro_context)# download EvaluatorBenchmarkerPack and define the benchmarker EvaluatorBenchmarkerPack = download_llama_pack("EvaluatorBenchmarkerPack", "./pack") evaluator_benchmarker = EvaluatorBenchmarkerPack( evaluator=evaluators["gpt-3.5"], eval_dataset=evaluator_dataset, show_progress=True, )# produce the benchmark result benchmark_df = await evaluator_benchmarker.arun( batch_size=5, sleep_time_in_seconds=0.5 )
基准测试结果
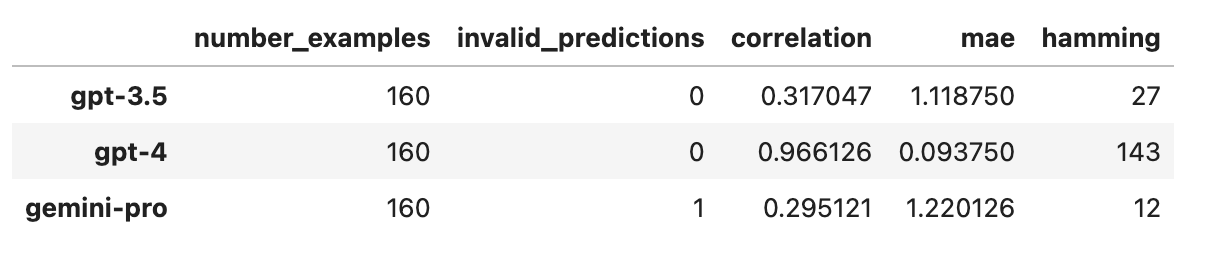
观察结果
- 似乎 Gemini-Pro 和 GPT-3.5 在与参考评估器 GPT-4 的接近程度上非常相似!
- 至于 GPT-4 与参考 GPT-4 的比较,这主要用于评估 LLM 的自洽性,在这方面我们看到它做得相当不错。
MT-Bench 人类判断数据集
对于此基准测试,我们将评估 LLM 评估器对两个 LLM 响应进行排名的任务,以确定两者中哪个更好。正是为了这种任务,LabelledPairwiseEvaluatorDataset 应运而生。我们在此整理的 llama 数据集是原始 MT-Bench 人类判断数据集的微调版本。具体来说,在原始数据集中,关于三元组(查询、模型 A、模型 B)的示例存在一些重复,因为其中一些示例提供了不止一次人类评估。由于我们的提示允许 LLM 评估器判定平局,并且据我们所知,这对于人类评估器来说不是一个选项,因此我们汇总了不同人类评估的结果,以获得对于每个三元组(查询、模型 A、模型 B),模型 A 获胜与模型 B 获胜的比例。然后,如果比例在 0.4 到 0.6 之间,我们就认为人类评估器判定为平局。在此应强调的是,参考评估是由人类提供的,因此我们在此生成和分享的基准指标代表了 LLM 与人类的一致性。
(我们在此跳过展示生成结果的代码片段,因为它们与之前分享的代码片段基本相同,只是需要 PairwiseComparisonEvaluator 而不是 CorrectnessEvaluator。)
基准测试结果

观察结果
- 就一致性率而言,这三个模型似乎非常接近。再次强调,这些一致性率都基于预测/评估有效的前提。因此,应该用无效和不确定的计数来“折算”这些结果。
- Gemini Pro 和 GPT-3.5 似乎比 GPT-4 更果断一些,导致它们只有 50-60 次平局,而 GPT-4 有 100 次平局。
- 总的来说,Gemini Pro 似乎能与 GPT 模型相匹敌,并且我认为它优于 GPT-3.5!
现在就去评估你的评估器吧(别忘了吃蔬菜)!
出于显而易见的原因,评估您的 LLM 评估器非常重要,因为现在我们依赖它们来评估我们的 LLM 系统的性能——一个坏掉的指南针真的没什么用!有了这些新推出的 llama 数据集,我们希望您可以轻松地在自己的数据上编译自己的基准测试数据集,然后更轻松地生成您的基准指标。如前所述,本博客中讨论的两个 llama 数据集可通过 LlamaHub 下载和使用。请务必访问并利用那里的数据集来构建一个详尽的基准测试套件!(我们也欢迎贡献 llama 数据集!)



