
Raghav Dixit • 2024-02-17
多模态 RAG 实现高级视频处理,结合 LlamaIndex 和 LanceDB
视频在 YouTube、Instagram 等平台上的广泛消费,凸显了高效处理和分析视频内容的重要性。这一能力为媒体娱乐、安全和教育等各个领域带来了巨大的机遇。然而,主要的挑战在于如何有效地从视频中提取有意义的信息,因为视频本质上是复杂的多模态数据流。
本篇博客文章介绍了一种解决方案,该方案利用 LlamaIndex 的 Python API,以利用 OpenAI GPT4V 的高级能力,并结合 LanceDB 在各种数据格式上的高效数据管理,来处理视频。
...但“RAG”到底是什么意思?
检索增强生成(RAG)是一种将信息检索与生成式 AI 相结合的技术,通过利用大型数据存储库来生成精确且与上下文相关的响应。
RAG 的核心概念
RAG 分为两个阶段
- 检索:利用语义搜索查找与查询相关的文档,利用上下文和含义,而不仅仅是关键词。
- 生成:整合检索到的信息以生成连贯的响应,使 AI 能够动态地从广泛的内容中“学习”。
RAG 架构
该架构通常包括用于检索的密集向量搜索引擎和用于生成的 Transformer 模型。该过程:
- 执行语义搜索以获取相关文档。
- 使用查询处理这些文档以创建全面的上下文。
- 然后,生成模型根据这个丰富的上下文精心制作详细的响应。
扩展到多模态
多模态 RAG 在检索和生成阶段整合了各种数据类型(文本、图像、音频、视频),从而实现更丰富的信息来源。例如,回答关于“气候变化对北极熊的影响”的查询可能涉及检索科学文本、图像和视频,以生成一个丰富、多格式的响应。
让我们回到我们的用例,深入了解这一切是如何实现的。接下来,您可以在 Google Colab 上访问完整的代码。
该解决方案分为以下几个部分。点击主题可跳转到特定部分。
1. 视频下载
首先,我们需要从公开来源本地下载多模态内容,我使用 pytube 下载了 3Blue1Brown 关于高斯函数的一个 YouTube 视频。
# SET CONFIG
video_url = "https://www.youtube.com/watch?v=d_qvLDhkg00"
output_video_path = "./video_data/"
output_folder = "./mixed_data/"
output_audio_path = "./mixed_data/output_audio.wav"
filepath = output_video_path + "input_vid.mp4"
Path(output_folder).mkdir(parents=True, exist_ok=True)def download_video(url, output_path):
"""
Download a video from a given url and save it to the output path.
Parameters:
url (str): The url of the video to download.
output_path (str): The path to save the video to.
Returns:
dict: A dictionary containing the metadata of the video.
"""
from pytube import YouTube
yt = YouTube(url)
metadata = {"Author": yt.author, "Title": yt.title, "Views": yt.views}
yt.streams.get_highest_resolution().download(
output_path=output_path, filename="input_vid.mp4"
)
return metadata
运行 metadata_vid = download_video(video_url, output_video_path) 以调用该函数并将视频存储在本地。
2. 视频处理
现在我们需要提取多模态内容——图像、文本(通过音频)。我使用 moviepy 每 5 秒提取视频的一帧(约 160 帧)。
def video_to_images(video_path, output_folder):
"""
Convert a video to a sequence of images and save them to the output folder.
Parameters:
video_path (str): The path to the video file.
output_folder (str): The path to the folder to save the images to.
"""
clip = VideoFileClip(video_path)
clip.write_images_sequence(
os.path.join(output_folder, "frame%04d.png"), fps=0.2 #configure this for controlling frame rate.
)接着,我们提取音频组件。
def video_to_audio(video_path, output_audio_path):
"""
Convert a video to audio and save it to the output path.
Parameters:
video_path (str): The path to the video file.
output_audio_path (str): The path to save the audio to.
"""
clip = VideoFileClip(video_path)
audio = clip.audio
audio.write_audiofile(output_audio_path)接下来,我们使用 SpeechRecognition 库从音频中提取文本。
def audio_to_text(audio_path):
"""
Convert an audio file to text.
Parameters:
audio_path (str): The path to the audio file.
Returns:
test (str): The text recognized from the audio.
"""
recognizer = sr.Recognizer()
audio = sr.AudioFile(audio_path)
with audio as source:
# Record the audio data
audio_data = recognizer.record(source)
try:
# Recognize the speech
text = recognizer.recognize_whisper(audio_data)
except sr.UnknownValueError:
print("Speech recognition could not understand the audio.")
except sr.RequestError as e:
print(f"Could not request results from service; {e}")
return text运行下方代码块以完成提取和存储过程。
video_to_images(filepath, output_folder)
video_to_audio(filepath, output_audio_path)
text_data = audio_to_text(output_audio_path)
with open(output_folder + "output_text.txt", "w") as file:
file.write(text_data)
print("Text data saved to file")
file.close()
os.remove(output_audio_path)
print("Audio file removed")3. 构建多模态索引和向量存储
处理完视频后,我们开始构建多模态索引和向量存储。这包括使用 OpenAI 的 CLIP 模型为文本和视觉数据生成嵌入,然后通过 LanceDBVectorStore 类将这些嵌入存储并管理在 LanceDB 向量存储中。
from llama_index.indices.multi_modal.base import MultiModalVectorStoreIndex
from llama_index import SimpleDirectoryReader, StorageContext
from llama_index import SimpleDirectoryReader, StorageContext
from llama_index.vector_stores import LanceDBVectorStore
from llama_index import (
SimpleDirectoryReader,
)
text_store = LanceDBVectorStore(uri="lancedb", table_name="text_collection")
image_store = LanceDBVectorStore(uri="lancedb", table_name="image_collection")
storage_context = StorageContext.from_defaults(
vector_store=text_store, image_store=image_store
)
# Create the MultiModal index
documents = SimpleDirectoryReader(output_folder).load_data()
index = MultiModalVectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
)4. 检索相关图像和上下文
索引就绪后,系统便可根据输入查询检索相关的图像和上下文信息。这使用精确且相关的多模态数据增强了提示,从而将分析根植于视频内容。
让我们设置检索引擎,我正在根据相似度分数从 vectordb 中获取前 5 个最相关的 Nodes。
retriever_engine = index.as_retriever(
similarity_top_k=5, image_similarity_top_k=5
)一个
Node对象是任何源文档的“块”,无论是文本、图像或其他。它包含嵌入以及该数据块的元信息。默认情况下,LanceDB 使用
l2作为评估相似度的指标类型。如有需要,您可以将指标类型指定为cosine或dot。
接下来,我们创建一个辅助函数来执行检索逻辑。
from llama_index.response.notebook_utils import display_source_node
from llama_index.schema import ImageNode
def retrieve(retriever_engine, query_str):
retrieval_results = retriever_engine.retrieve(query_str)
retrieved_image = []
retrieved_text = []
for res_node in retrieval_results:
if isinstance(res_node.node, ImageNode):
retrieved_image.append(res_node.node.metadata["file_path"])
else:
display_source_node(res_node, source_length=200)
retrieved_text.append(res_node.text)
return retrieved_image, retrieved_textdef retrieve(retriever_engine, query_str):
retrieval_results = retriever_engine.retrieve(query_str)现在输入查询,然后继续完成检索和可视化数据的过程。
query_str = """
Using examples from the video, explain all things covered regarding
the Gaussian function
"""
img, txt = retrieve(retriever_engine=retriever_engine, query_str=query_str)
image_documents = SimpleDirectoryReader(
input_dir=output_folder, input_files=img
).load_data()
context_str = "".join(txt)
plot_images(img)您应该会看到与以下示例类似的内容(请注意,输出会因您的查询而异)。
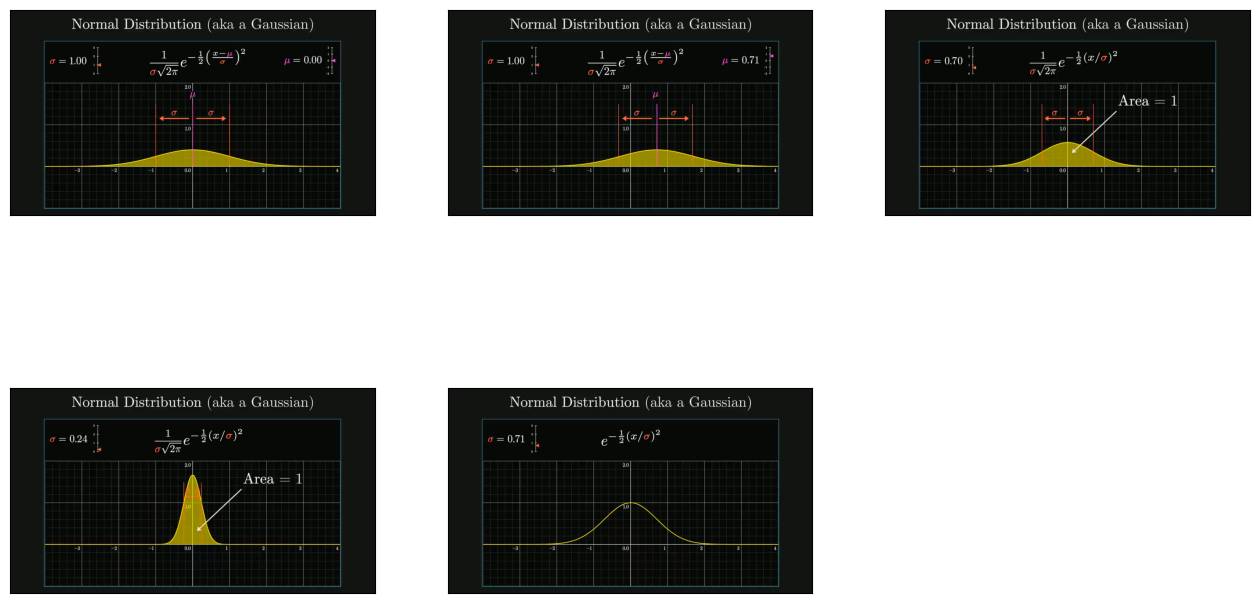
请注意,显示的 node 对象显示了数据块的 Id、其相似度分数,以及匹配到的数据块的源文本(对于图像,我们获得的是文件路径而不是文本)。
5. 推理与响应生成
最后一步利用 GPT4V 对输入查询与增强数据之间的关联进行推理。下面是提示模板:
qa_tmpl_str = (
"""
Given the provided information, including relevant images and retrieved context from the video, \
accurately and precisely answer the query without any additional prior knowledge.\n"
"Please ensure honesty and responsibility, refraining from any racist or sexist remarks.\n"
"---------------------\n"
"Context: {context_str}\n"
"Metadata for video: {metadata_str} \n"
"---------------------\n"
"Query: {query_str}\n"
"Answer: "
"""
)LlamaIndex 中的 OpenAIMultiModal 类使我们能够将图像数据直接合并到我们的提示对象中。因此,在最后一步中,我们增强了模板中的查询和上下文元素,以生成如下响应:
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
openai_mm_llm = OpenAIMultiModal(
model="gpt-4-vision-preview", api_key=OPENAI_API_TOKEN, max_new_tokens=1500
)
response_1 = openai_mm_llm.complete(
prompt=qa_tmpl_str.format(
context_str=context_str, query_str=query_str, metadata_str=metadata_str
),
image_documents=image_documents,
)
pprint(response_1.text)生成的响应很好地捕捉了上下文并正确地构建了答案:
3Blue1Brown 的视频“A pretty reason why Gaussian + Gaussian = Gaussian”(高斯函数加高斯函数为何仍是高斯函数的有趣原因)深入探讨了高斯函数或正态分布,重点介绍了几个关键方面:
中心极限定理:视频从中心极限定理开始,解释了多个随机变量副本之和如何趋向于正态分布,并且变量越多,趋近效果越好。
随机变量的卷积:解释了两个随机变量相加如何表现为其分布的卷积,重点是通过对角切片来可视化这一过程。
高斯函数:详细介绍了高斯函数,强调了有效概率分布所需的归一化因子,并用标准差 (σ) 和均值 (μ) 来描述分布的展布和中心。
两个高斯函数的卷积:讨论了两个服从正态分布的变量相加,这等同于对两个高斯函数进行卷积,并利用图的旋转对称性来可视化这一过程。
旋转对称性与切片:展示了 e^(-x²) * e^(-y²) 绕原点的旋转对称性,这是高斯函数的一个独特属性。它解释了计算对角切片下的面积,这等同于函数的卷积。
结果分布:演示了两个高斯函数的卷积会产生另一个高斯函数,这是卷积中一个显著的例外,因为卷积通常会产生不同类型的函数。
结果的标准差:得出结论,对两个均值为 0、标准差为 (σ) 的正态分布进行卷积,将产生一个标准差为 sqrt(2) * σ 的正态分布。
对中心极限定理的启示:强调了两个高斯函数卷积在中心极限定理中的作用,将高斯分布定位为分布空间中的不动点。
作者在整个视频中使用了视觉示例和解释,以阐明与高斯函数及其在概率和统计中的重要性相关的数学概念。
结论
多模态 RAG 架构为处理和分析视频内容提供了一个强大而高效的解决方案。通过利用 OpenAI 的 GPT4V 和 LanceDB 的能力,这种方法不仅简化了视频分析过程,还提高了其准确性和相关性。无论是用于内容创作、安全监控还是教育目的,这项技术的潜在应用都广泛而多样。随着我们不断探索和完善这些工具,视频分析的未来前景光明,AI驱动的解决方案正引领着对视频数据进行更具洞察力和更具行动力的解读。
敬请关注即将发布的项目!



