
Huiqiang Jiang • 2023-11-06
LongLLMLingua:告别中间损失,通过提示压缩节省您的 RAG 成本
在 RAG 中,在检索阶段之后,需要执行重排序 + 细粒度提示压缩 + 子序列恢复 以增强 LLM 对关键信息的感知,这就是 LongLLMLingua。
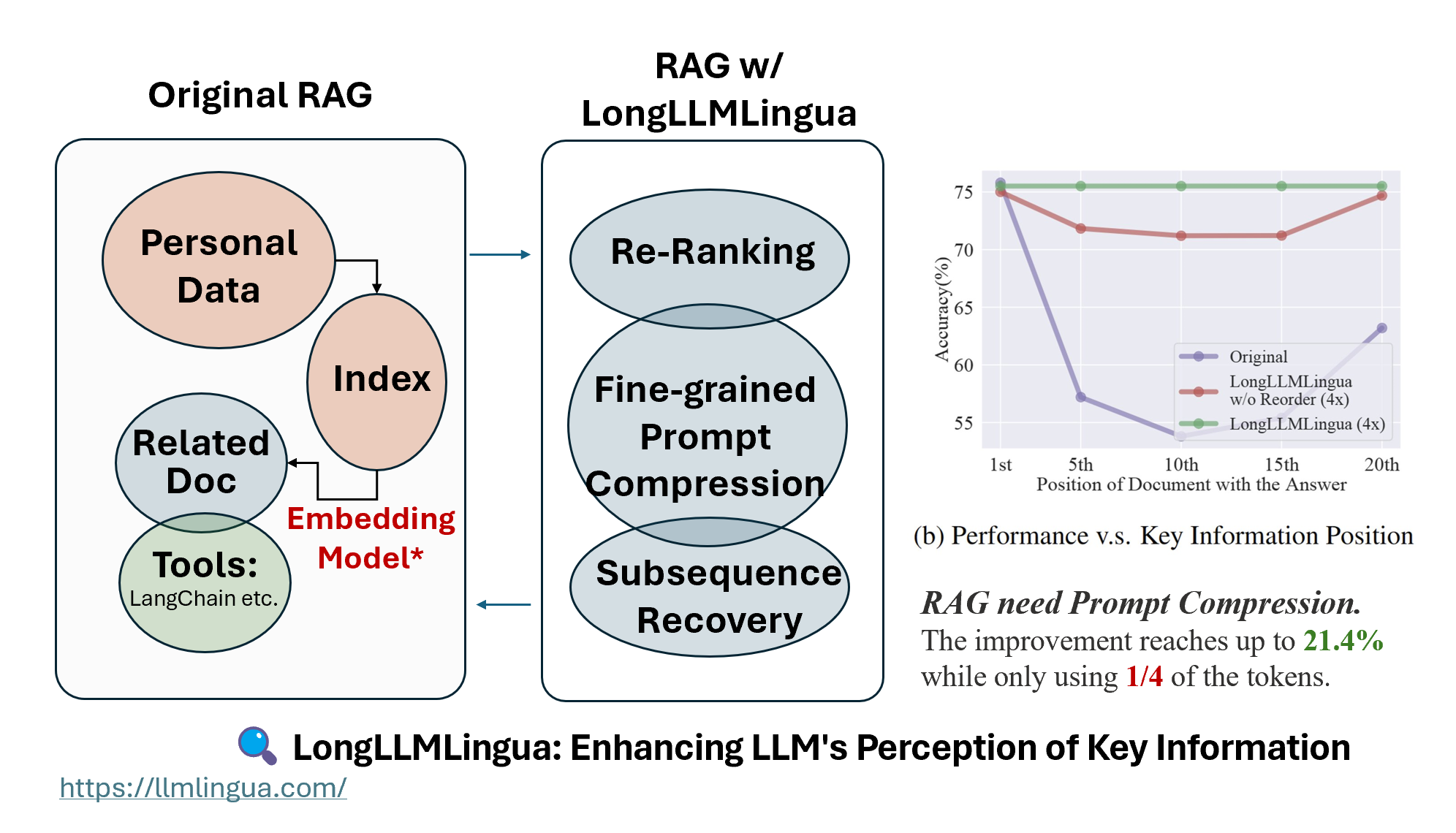
太长不看:虽然检索增强生成 (RAG) 在各种场景中非常有效,但它仍然存在一些缺点,例如:1) 性能下降,例如“中间遗忘”问题,2) 高成本,包括财务成本和延迟,以及 3) 上下文窗口限制。LongLLMLingua 通过提示压缩为 RAG 或长上下文场景中的这些问题提供解决方案。它可以在仅使用四分之一 token 的情况下,将准确率提高多达 21.4%。在长上下文场景中,每 1000 个示例可以节省 28 美元。
在 项目页面 上查看真实案例。
我们之前写了一篇博客文章,介绍了 LLMLingua 的设计,其出发点是为 LLM 设计一种特殊语言。这次,我们的重点将放在涉及 RAG 的场景上。
检索增强生成是目前创建基于特定文本集合的 AI 代理最可靠且经过验证的技术。像 LlamaIndex 这样的框架提供了全面的 RAG 解决方案,帮助用户更方便地在 LLM 中利用专业数据。
一个常见的误解是,在 RAG 过程中检索尽可能多的相关文档,并将它们拼接在一起形成一个长的检索提示是有益的,尤其随着越来越多的 LLM 支持更长的上下文窗口。然而,这种方法会为提示引入更多噪音,并削弱 LLM 对关键信息的感知,导致诸如“中间遗忘”[1] 之类的问题。
这些问题在涉及 RAG 的真实场景中变得更加明显。更好的检索机制可能会引入高质量的噪音文档,这更容易导致性能下降。
重排序是一个直观的概念。
一个直观的想法是通过重排序将最相关的信息重新放置到提示的两侧。重排序的概念已在 LlamaIndex 和 LangChain 等框架中实现。
然而,根据我们的实验,嵌入模型很难充当一个“好的”重排序器。根本原因是查询和文档之间缺乏交互过程。嵌入的双塔结构不适合一般场景下的重排序,尽管在微调后可能有效。
直接使用 LLM 作为重排序器也可能因为幻觉导致误判。最近,一些重排序模型已从嵌入模型扩展而来,例如 bge-rerank。然而,这类重排序模型通常存在上下文窗口限制。
为了解决上述问题,我们提出了一种问题感知的粗粒度提示压缩方法。该方法基于与问题对应的困惑度来评估上下文与问题之间的相关性。
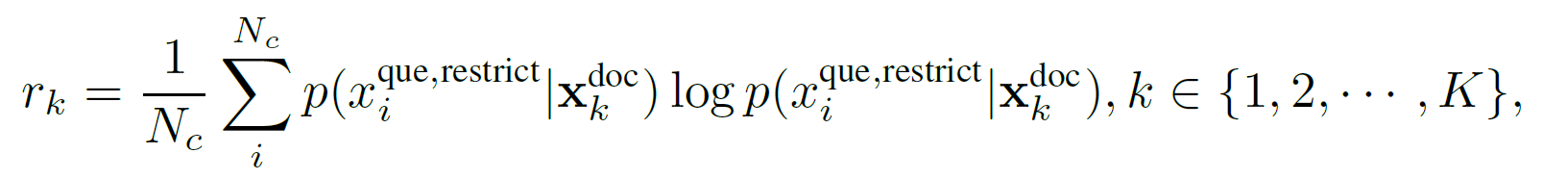
为了减轻较小 LLM 中的幻觉问题,我们在问题后附加了一个限制性语句,具体来说是“在给定的文档中可以找到这个问题的答案”,以限制相关幻觉引起的潜在空间。
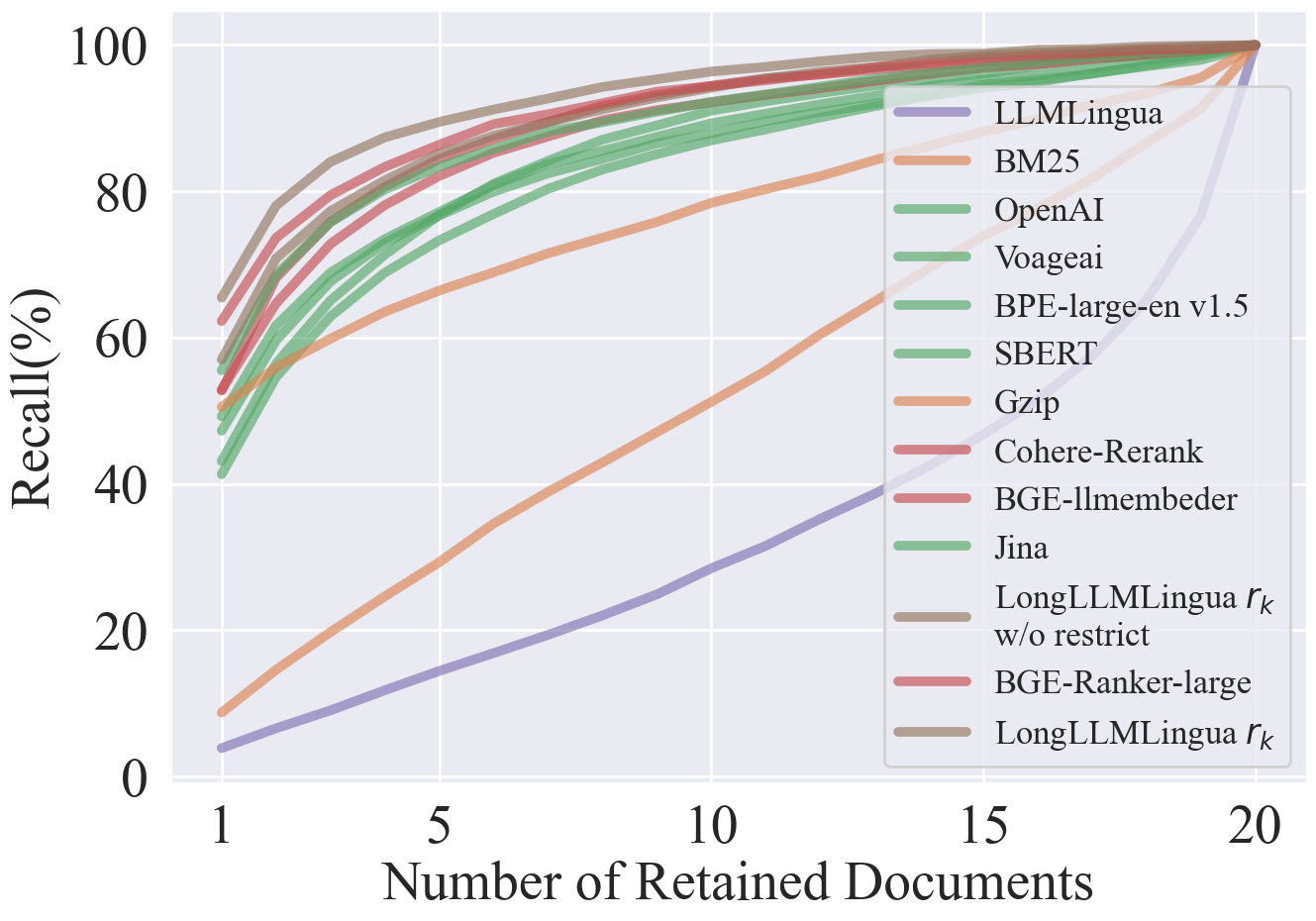
结果表明,这种方法显著优于嵌入模型和重排序模型。我们增加了一些最近发布的嵌入模型和重排序模型。如您所见,bge-rerank-large 的性能非常接近 LongLLMLingua。重排序模型通常比嵌入模型表现更好。目前,Jina 是嵌入模型中表现最好的方法。
压缩不相关和不重要的信息
除了召回尽可能多的相关文档之外,另一种方法是尽可能地压缩不相关或不重要的上下文。
之前关于长上下文的研究侧重于如何扩展 LLM 以支持更长的上下文窗口。然而,几乎没有研究探讨这是否能真正提高下游任务的性能。一些先前的研究表明,提示中存在更多噪音以及关键信息在提示中的位置,都可能影响 LLM 的性能。
从提示压缩的角度来看,Selective Context[2] 和 LLMLingua[3] 通过使用小型语言模型计算提示的互信息或困惑度来估计元素的重性。然而,在 RAG 或长上下文场景中,这种方法由于无法感知问题信息,很容易丢失关键信息。
在最近提交给 ICLR’24 的论文中,出现了一些类似的做法。例如,Recomp[4] 通过联合训练两种不同粒度的压缩器来减少 RAG 场景中 token 的使用。长上下文中的 RAG[5] 将长上下文分解为一系列块,并使用检索方法进行压缩,这实际上是 LongLLMLingua 论文中实现的基于检索的方法。此外,Walking Down the Memory Maze[6] 还设计了一种分层摘要树,以增强 LLM 对关键信息的感知。
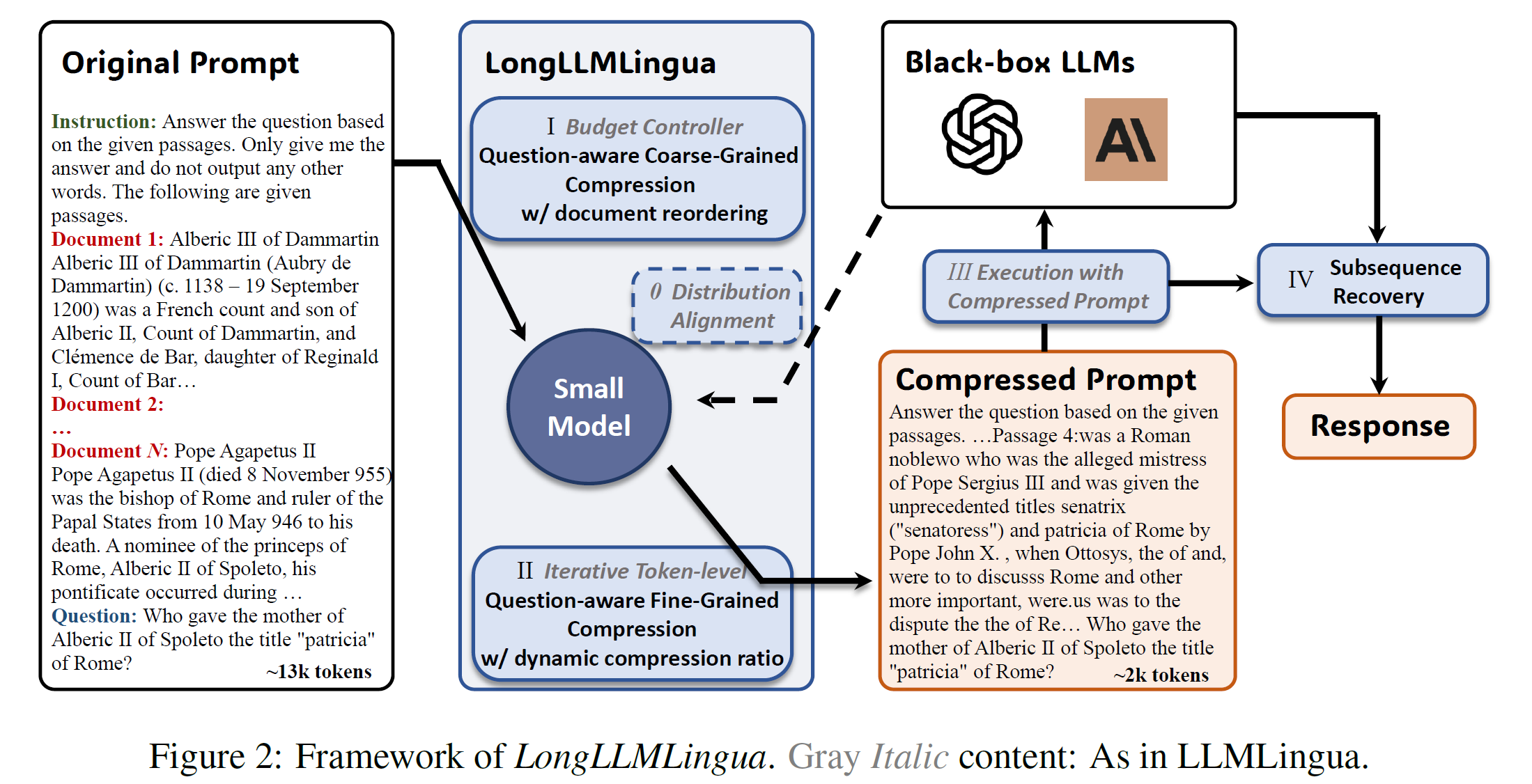
问题感知细粒度提示压缩
为了使 token 级别的提示压缩也能感知问题信息,我们提出了一种对比困惑度,它比较了文档对应的困惑度分布与文档加问题对应的困惑度分布之间的差异。
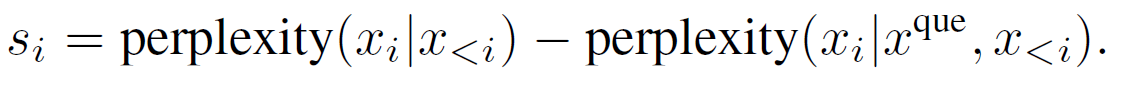
一个直观的感觉是,当问题作为上下文时,文档中相关 token 对应的困惑度会降低。这种降低的幅度代表了文档中 token 相对于问题的重要性。
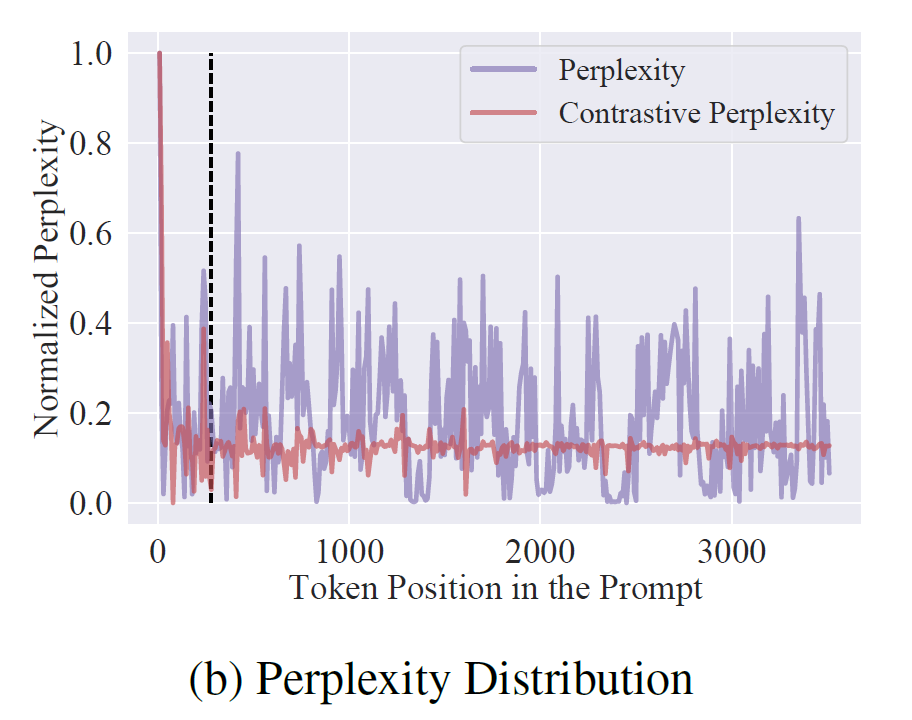
图 3 显示了在提取关键 token 方面,困惑度与对比困惑度之间的分布差异。
如何减少中间损失
既然粗粒度提示压缩在准确率方面远超其他检索方法,那么利用这种排序信息将与问题更相关的文档重新排列到提示的开头和结尾,这是一个非常自然的念头。然而,通过我们的测试发现,重新排列到提示的开头比均匀分布在两端更有效。因此,我们选择将最相关的文档重新排序到提示的开头。
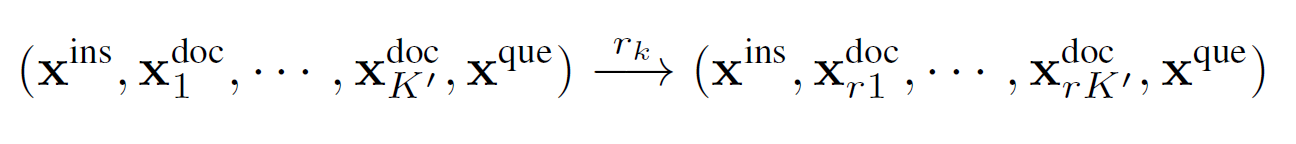
如何在压缩过程中实现自适应粒度控制?
为了更好地利用两种粒度压缩的信息,在细粒度提示压缩中,我们根据从粗粒度压缩获得的排序信息,动态分配不同的压缩比给不同的文档,从而保留重要文档中更重要的信息。
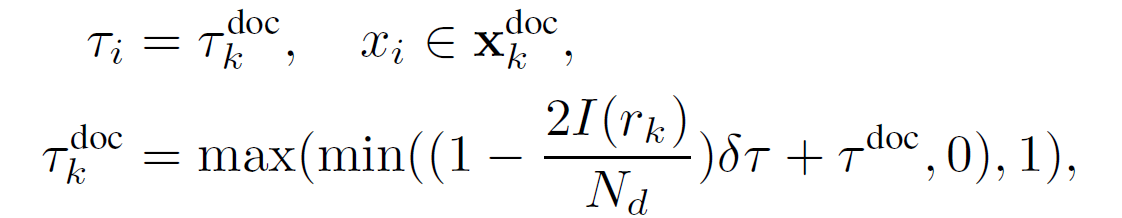
如何提高关键信息的完整性?
由于 LongLLMLingua 是 token 级别的提示压缩,它不可避免地会删除单词的一些 token,这可能导致某些检索相关任务无法获得完整结果。但这实际上可以通过简单的子序列匹配方法来恢复。具体来说,原始提示、压缩提示和响应之间存在子序列关系。通过建立压缩提示中出现的响应子序列与原始提示子序列之间的映射关系,可以有效地恢复原始提示内容。

实验
为了评估 LongLLMLingua 的有效性,我们在多文档问答 (RAG) 和两个长上下文基准测试中进行了详细测试。特别是,为多文档问答选择的数据集非常接近实际的 RAG 场景(例如 Bing Chat),其中使用了 Contriever(一种最先进的检索系统)来召回 20 篇相关文档,包括一篇真实答案文档。原始文档与问题具有高度语义相关性。

可以看出,与基于检索的方法和基于压缩的方法相比,LongLLMLingua 在 RAG 场景中更显著地提高了性能,在 4 倍压缩率下可提高多达 21.4 个百分点,避免了原有的“中间遗忘”情况。
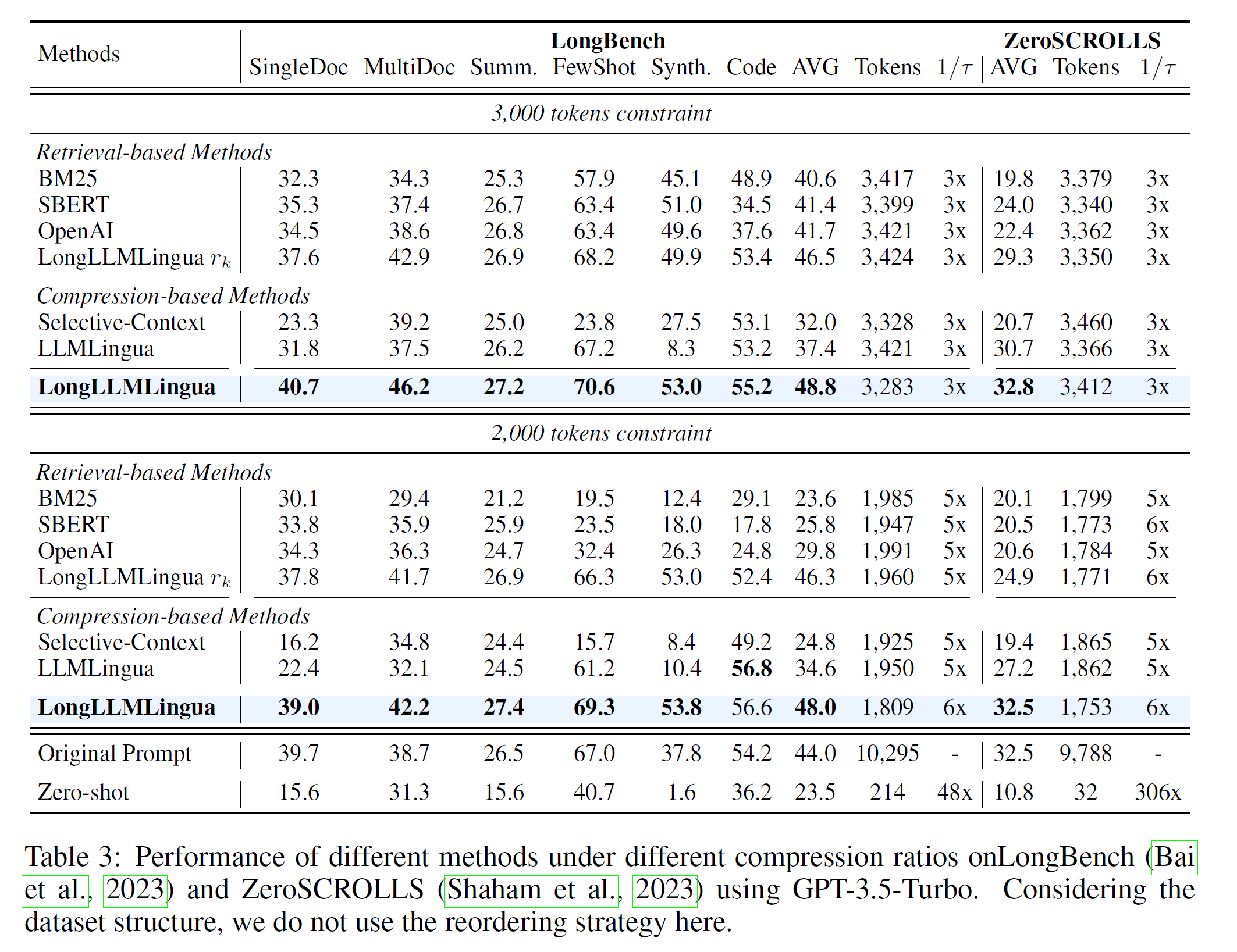
LongBench 和 ZeroScrolls 这两个基准测试的结果也得出了相似的结论。在长上下文场景中,LongLLMLingua 更善于保留与问题相关的关键信息。
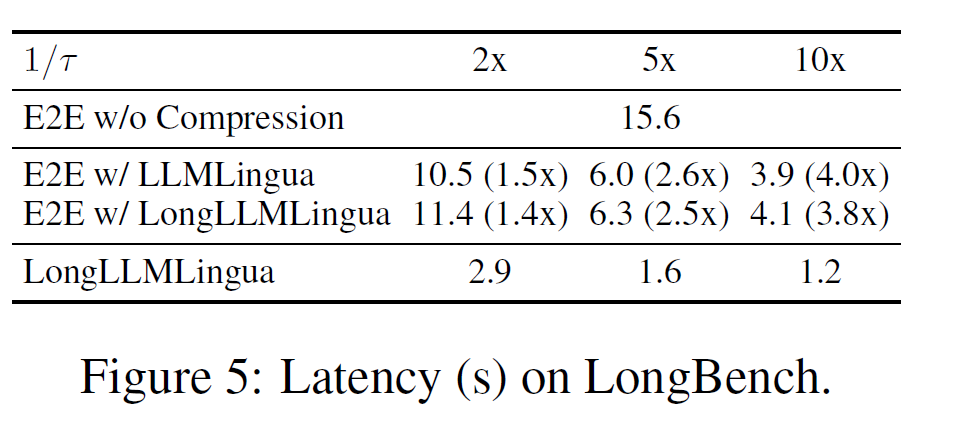
此外,LongLLMLingua 非常高效,可以加快端到端推理过程。
在 LlamaIndex 中使用
感谢 Jerry Liu 在 LongLLMLingua 项目上的帮助。现在您可以在这个广泛使用的 RAG 框架中将 LongLLMLingua 用作 NodePostprocessor。关于具体用法,您可以参考示例 1、示例 2 和以下代码。
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.response_synthesizers import CompactAndRefine
from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder
"dynamic_context_compression_ratio": 0.4, # enable dynamic compression ratio
},
)参考文献
[1] Lost in the Middle: How Language Models Use Long Contexts. Nelson F. Liu etc. [2] Compressing Context to Enhance Inference Efficiency of Large Language Models. Yucheng Li etc. [3] LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models. Huiqiang Jiang, Qianhui Wu etc. [4] RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation. Fangyuan Xu etc. [5] Retrieval meets Long Context Large Language Models. Peng Xu etc. [6] Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading. Howard Chen etc.



