
Jerry Liu • 2023-06-27
使用 LlamaIndex 和 Ray 构建并扩展强大的查询引擎
合著者:Jerry Liu(LlamaIndex CEO),Amog Kamsetty(Anyscale 软件工程师)
(注意:本文转载自 Anyscale 网站上的原博客文章,点击此处查看!)
在这篇博客中,我们将展示如何使用 LlamaIndex 和 Ray 构建一个查询引擎,以便根据 Ray 本身的文档和博客文章回答问题并生成见解。
我们将简要介绍 LlamaIndex + Ray,然后逐步指导您如何构建和部署这个查询引擎。我们将使用 Ray Datasets 来并行构建索引,并使用 Ray Serve 来构建部署。
引言
大型语言模型 (LLMs) 有潜力使用户从其非结构化文本数据中提取复杂的见解。检索增强生成管线已成为开发 LLM 应用的常见模式,使用户能够有效地对文档集合执行语义搜索。
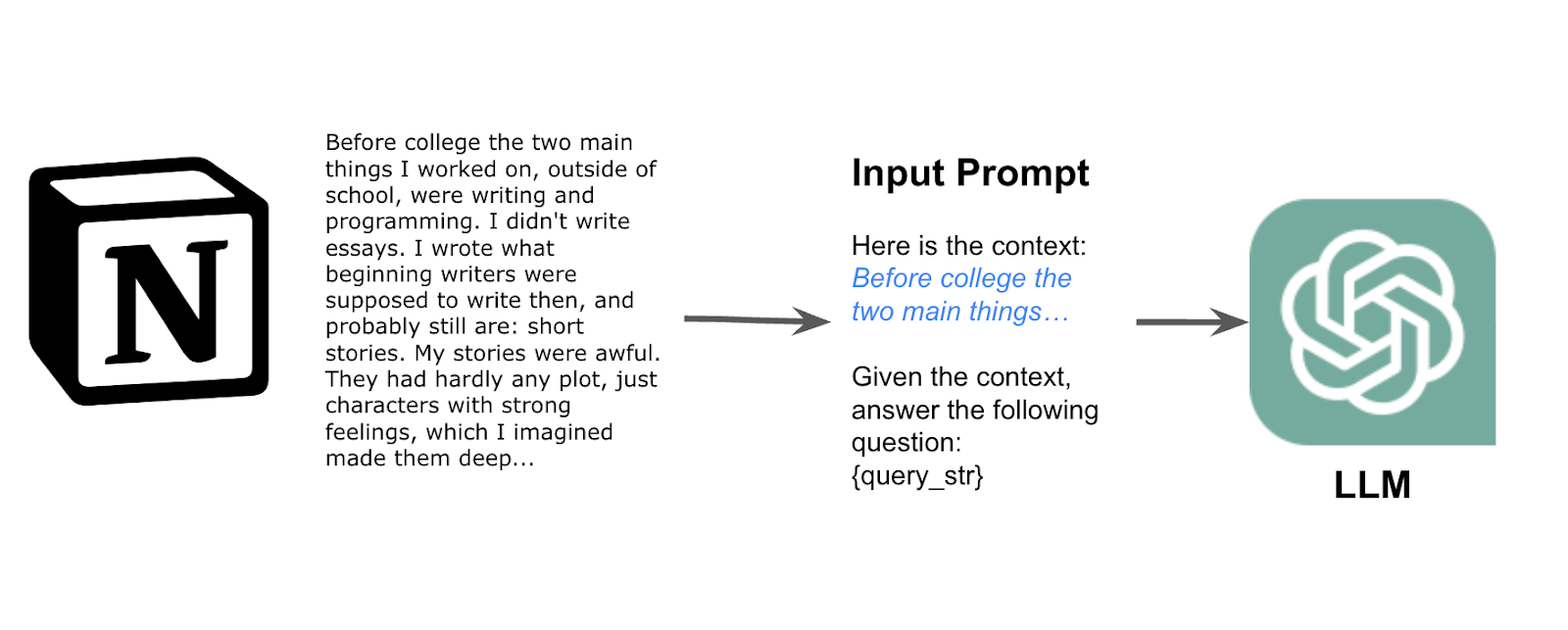
然而,当在许多不同数据源上进行这些应用的生产化时,存在一些挑战:
- 从许多不同数据源中索引数据的工具
- 处理跨不同数据源的复杂查询
- 将索引扩展到数千或数百万文档
- 将可扩展的 LLM 应用部署到生产环境
在此,我们展示了 LlamaIndex 和 Ray 是完成此任务的完美组合。
LlamaIndex 是一个用于构建 LLM 应用的数据框架,解决了挑战 #1 和 #2。它还提供了一整套工具,允许用户将其私有数据与语言模型连接。它提供了各种工具,帮助用户首先摄取和索引其数据 — 将不同格式的非结构化和结构化数据转换为语言模型可以使用的格式,以及查询其私有数据。
Ray 是一个强大的可扩展 AI 框架,解决了挑战 #3 和 #4。我们可以使用它显著加速摄取、推理、预训练,还可以轻松地在云端部署和扩展 LlamaIndex 的查询能力。
更具体地说,我们将展示一个非常相关的用例 — 重点介绍文档和 Ray 博客文章中都存在的 Ray 特性!
数据摄取和嵌入管线
我们使用 LlamaIndex + Ray 以并行方式摄取、解析、嵌入和存储 Ray 的文档和博客文章。这些步骤在两个数据源之间基本相同,因此我们只展示文档的处理步骤如下。
此博客部分的代码可在此处获取。
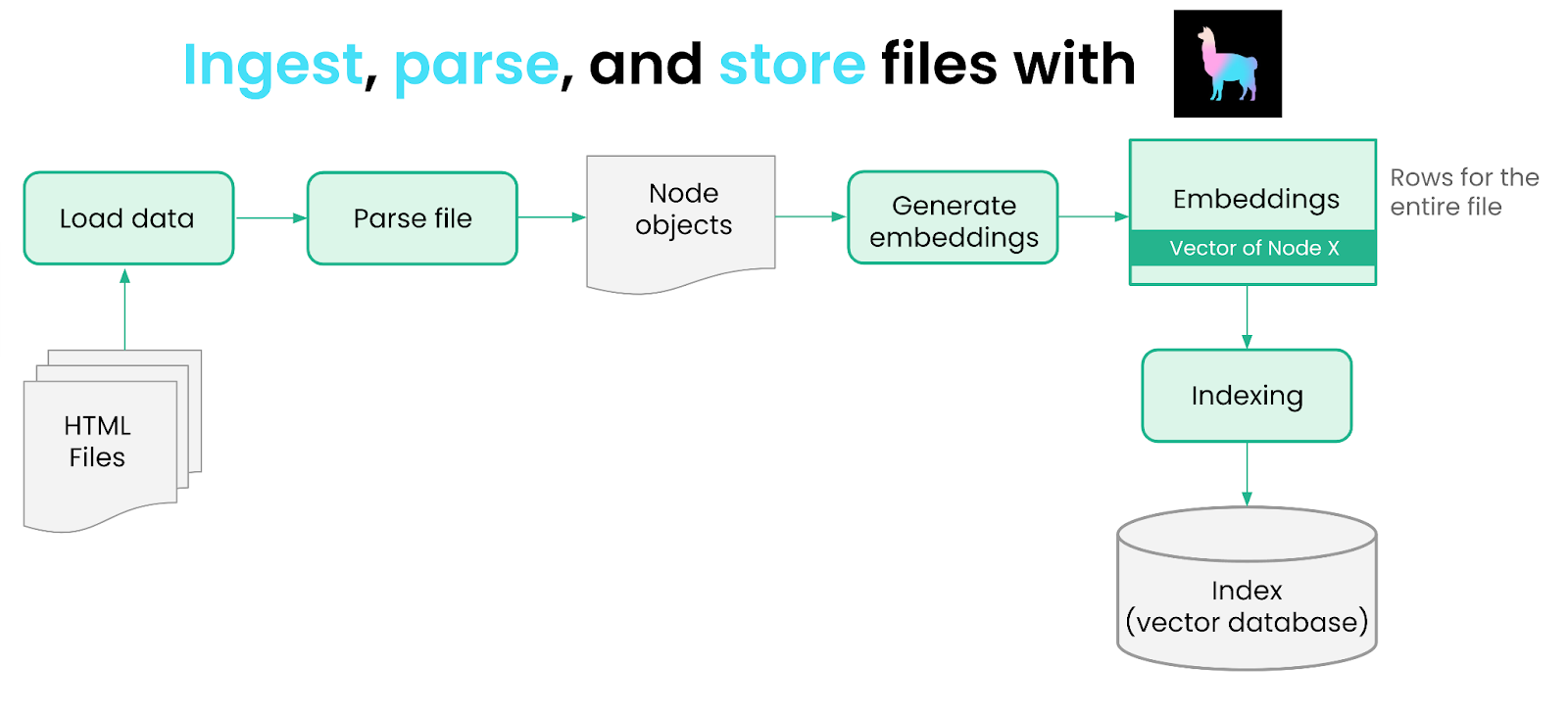
加载数据
我们首先摄取这两个数据源。我们首先获取两个数据源并下载 HTML 文件。
然后我们需要加载和解析这些文件。我们可以借助 LlamaHub 来完成,LlamaHub 是一个社区驱动的仓库,包含来自各种 API、文件格式(.pdf、.html、.docx)和数据库的 100 多种数据加载器。我们使用 Unstructured 提供的 HTML 数据加载器。
from typing import Dict, List
from pathlib import Path
from llama_index import download_loader
from llama_index import Document
# Step 1: Logic for loading and parsing the files into llama_index documents.
UnstructuredReader = download_loader("UnstructuredReader")
loader = UnstructuredReader()
def load_and_parse_files(file_row: Dict[str, Path]) -> Dict[str, Document]:
documents = []
file = file_row["path"]
if file.is_dir():
return []
# Skip all non-html files like png, jpg, etc.
if file.suffix.lower() == ".html":
loaded_doc = loader.load_data(file=file, split_documents=False)
loaded_doc[0].extra_info = {"path": str(file)}
documents.extend(loaded_doc)
return [{"doc": doc} for doc in documents]Unstructured 在各种文件之上提供了一套强大的解析工具。它能够通过去除标签等信息并相应地格式化文本来帮助清理 HTML 文档。
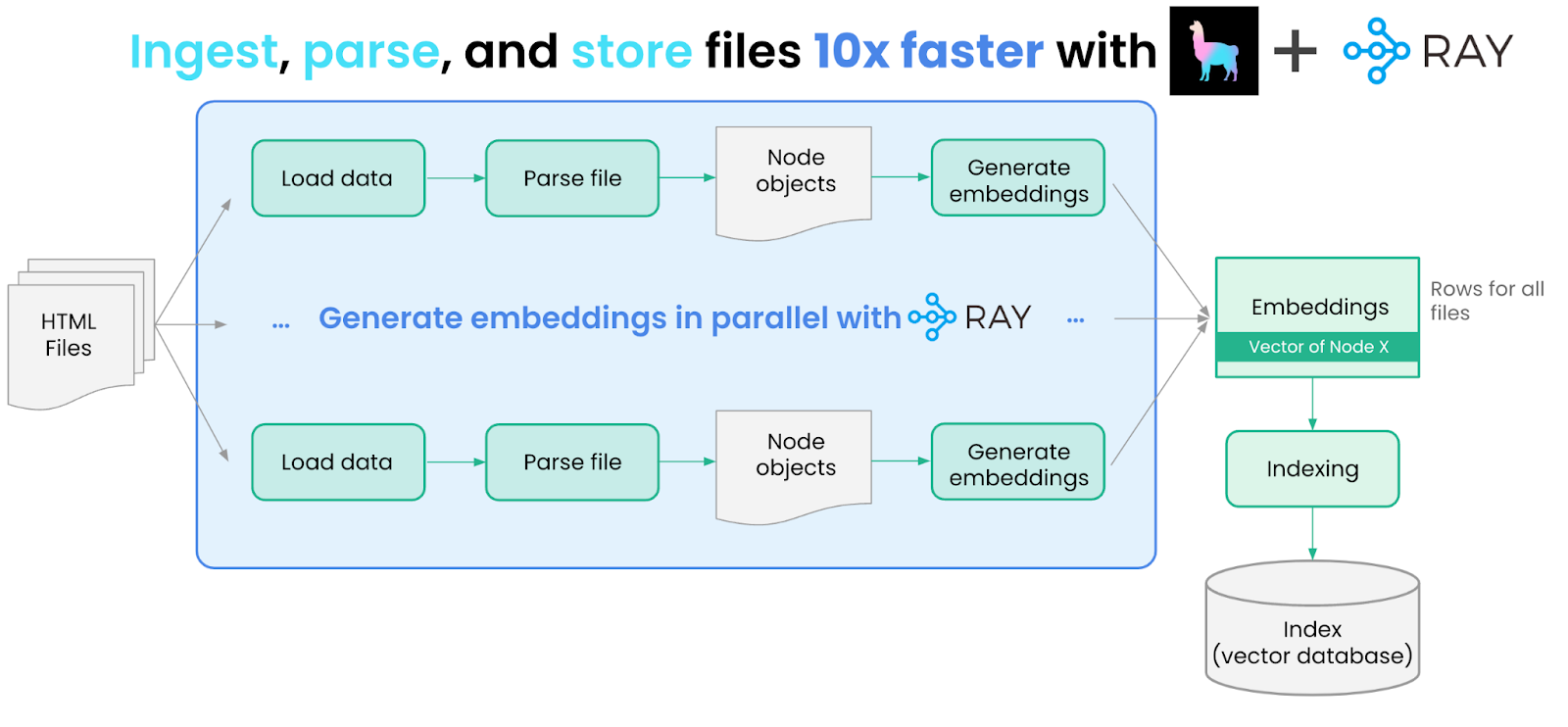
扩展数据摄取
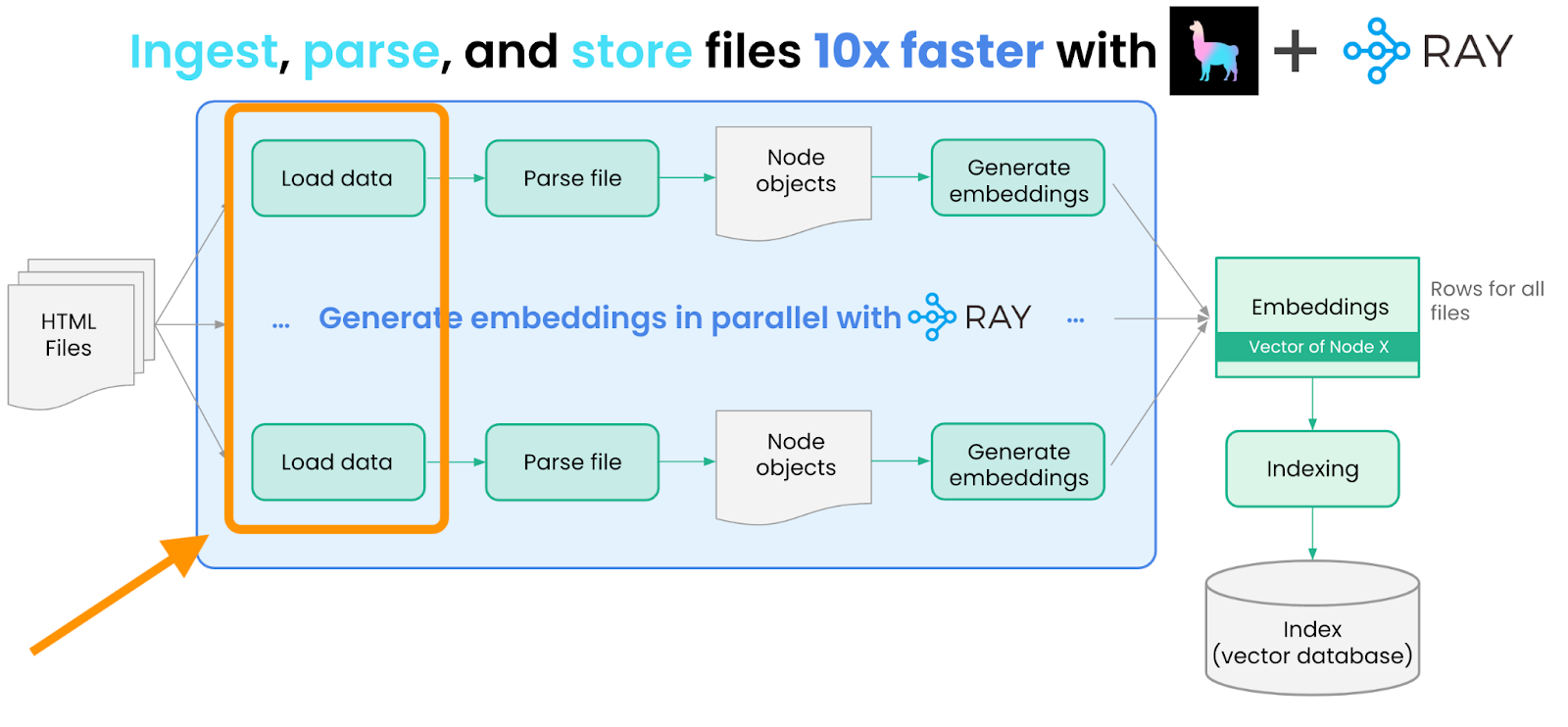
由于我们需要处理大量 HTML 文档,串行加载/处理每个文档效率低下且速度慢。这是一个使用 Ray 并将 `load_and_parse_files` 方法的执行分发到多个 CPU 或 GPU 的机会。
import ray
# Get the paths for the locally downloaded documentation.
all_docs_gen = Path("./docs.ray.io/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
# Create the Ray Dataset pipeline
ds = ray.data.from_items(all_docs)
# Use `flat_map` since there is a 1:N relationship.
# Each filepath returns multiple documents.
loaded_docs = ds.flat_map(load_and_parse_files)解析文件
加载文档后,下一步是将它们解析为 Node 对象 — “Node”对象表示从源文档派生出的更细粒度的文本块。Node 对象可用作输入提示中的上下文;通过设置足够小的块大小,我们可以确保插入 Node 对象不会超出上下文限制。
我们定义一个名为 `convert_documents_into_nodes` 的函数,该函数使用简单的文本分割策略将文档转换为节点。
# Step 2: Convert the loaded documents into llama_index Nodes. This will split the documents into chunks.
from llama_index.node_parser import SimpleNodeParser
from llama_index.data_structs import Node
def convert_documents_into_nodes(documents: Dict[str, Document]) -> Dict[str, Node]:
parser = SimpleNodeParser()
document = documents["doc"]
nodes = parser.get_nodes_from_documents([document])
return [{"node": node} for node in nodes]并行运行解析
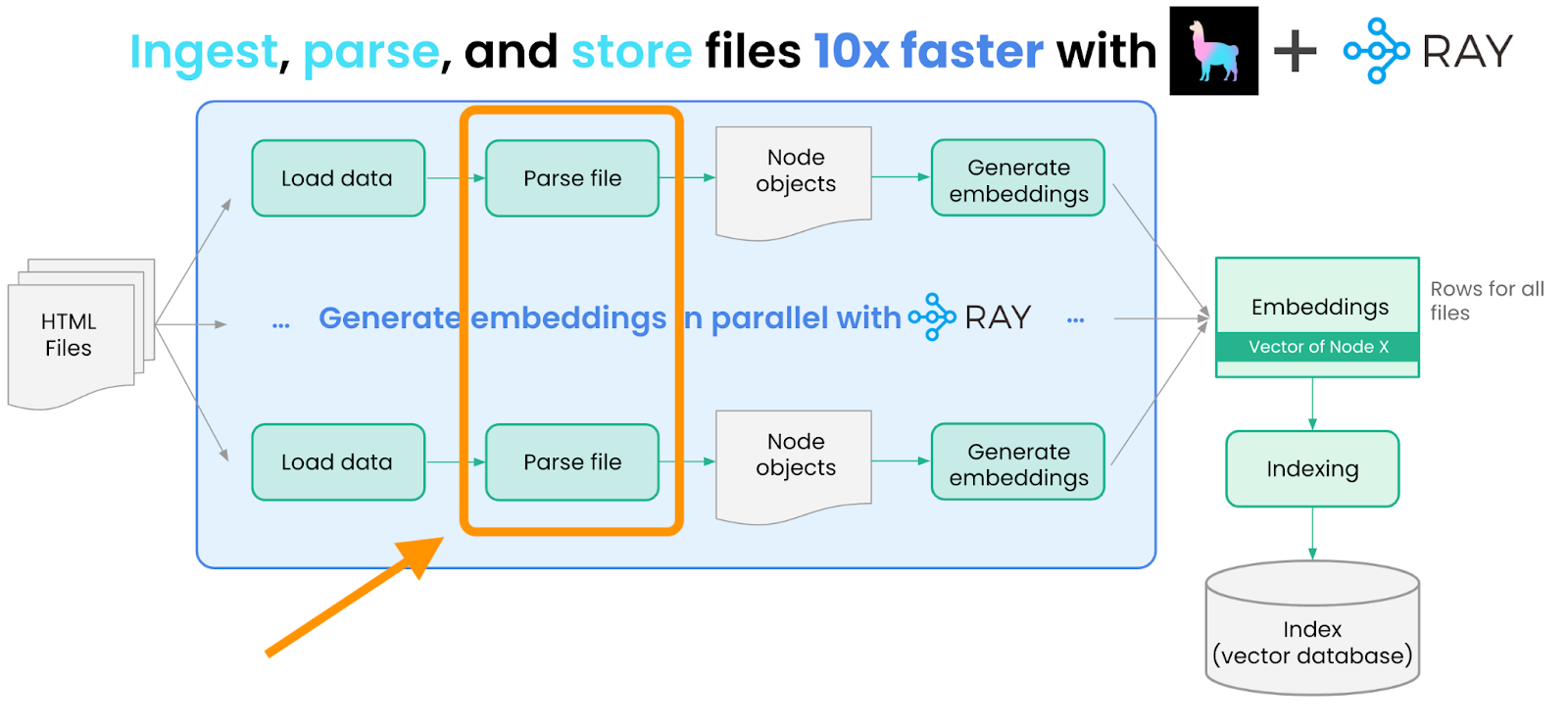
由于我们有很多文档,串行处理每个文档并将其转换为节点效率低下且速度慢。我们使用 Ray 的 `flat_map` 方法并行处理文档并将其转换为节点
# Use `flat_map` since there is a 1:N relationship. Each document returns multiple nodes.
nodes = loaded_docs.flat_map(convert_documents_into_nodes)生成嵌入
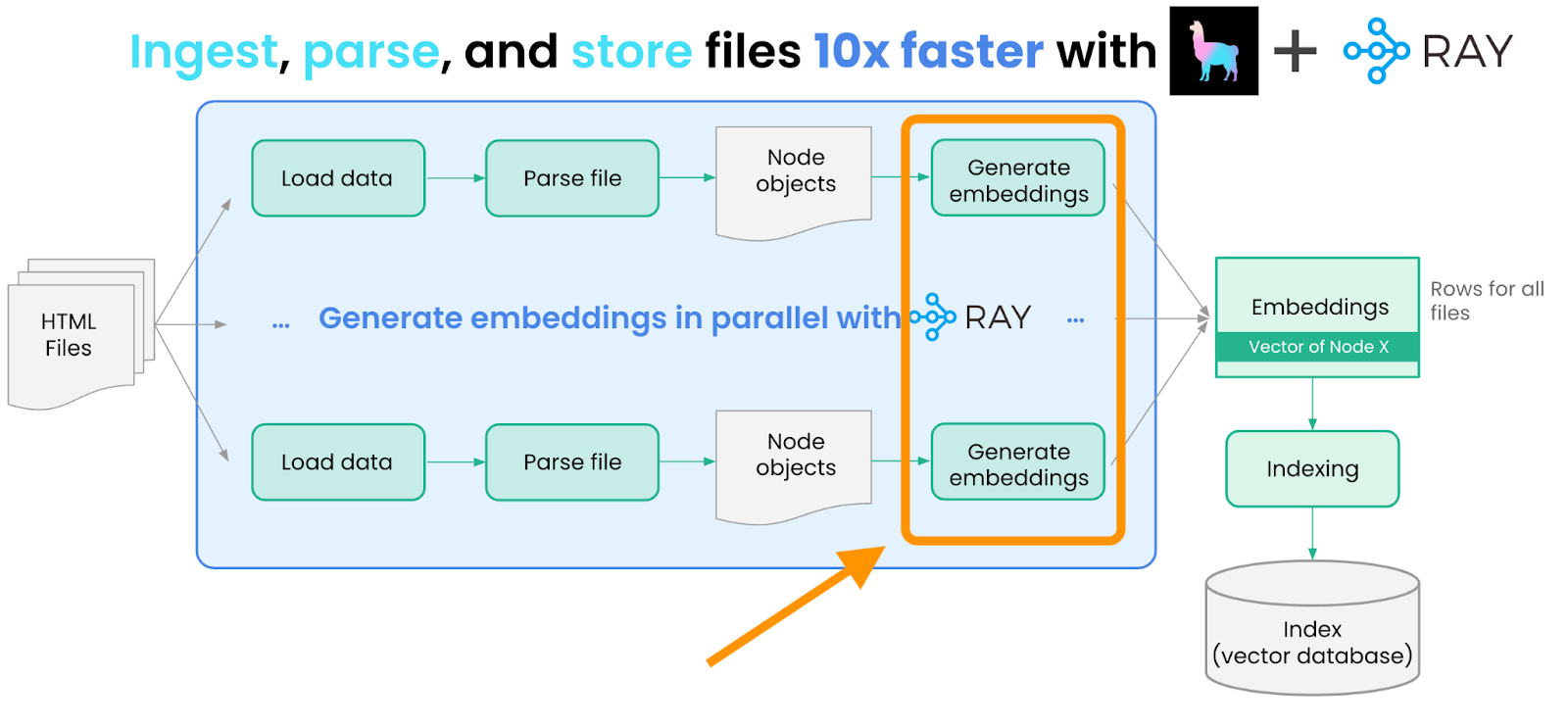
然后我们使用 Hugging Face Sentence Transformers 模型为每个 Node 生成嵌入。我们可以借助 LangChain 的嵌入抽象来完成此操作。
与文档加载/解析类似,嵌入生成也可以通过 Ray 并行化。我们将这些嵌入操作封装到名为 `EmbedNodes` 的辅助类中,以利用 Ray 抽象。
# Step 3: Embed each node using a local embedding model.
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
class EmbedNodes:
def __init__(self):
self.embedding_model = HuggingFaceEmbeddings(
# Use all-mpnet-base-v2 Sentence_transformer.
# This is the default embedding model for LlamaIndex/Langchain.
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={"device": "cuda"},
# Use GPU for embedding and specify a large enough batch size to maximize GPU utilization.
# Remove the "device": "cuda" to use CPU instead.
encode_kwargs={"device": "cuda", "batch_size": 100}
)
def __call__(self, node_batch: Dict[str, List[Node]]) -> Dict[str, List[Node]]:
nodes = node_batch["node"]
text = [node.text for node in nodes]
embeddings = self.embedding_model.embed_documents(text)
assert len(nodes) == len(embeddings)
for node, embedding in zip(nodes, embeddings):
node.embedding = embedding
return {"embedded_nodes": nodes}之后,为每个节点生成嵌入就像在 Ray 中调用以下操作一样简单:
# Use `map_batches` to specify a batch size to maximize GPU utilization.
# We define `EmbedNodes` as a class instead of a function so we only initialize the embedding model once.
# This state can be reused for multiple batches.
embedded_nodes = nodes.map_batches(
EmbedNodes,
batch_size=100,
# Use 1 GPU per actor.
num_gpus=1,
# There are 4 GPUs in the cluster. Each actor uses 1 GPU. So we want 4 total actors.
compute=ActorPoolStrategy(size=4))
# Step 5: Trigger execution and collect all the embedded nodes.
ray_docs_nodes = []
for row in embedded_nodes.iter_rows():
node = row["embedded_nodes"]
assert node.embedding is not None
ray_docs_nodes.append(node)数据索引
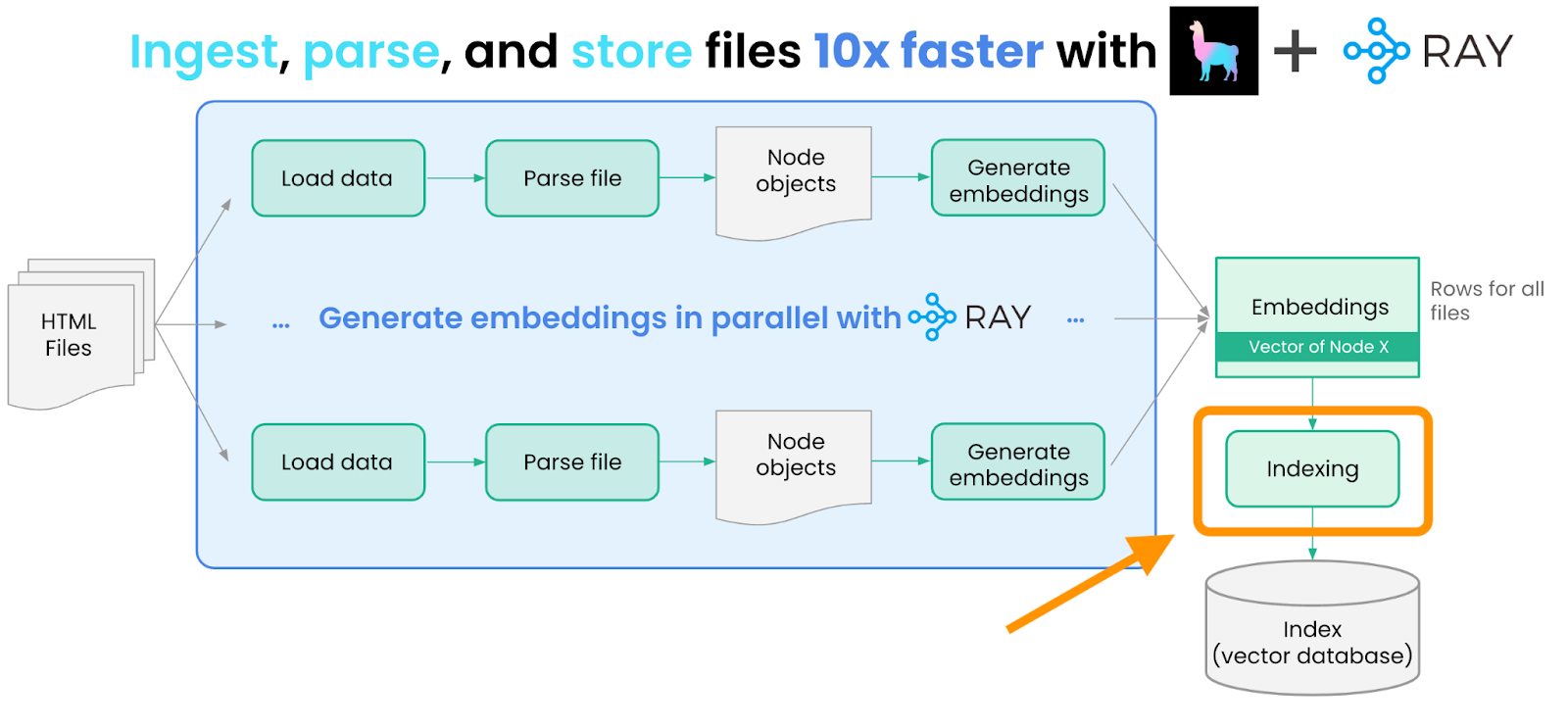
下一步是将这些节点存储在 LlamaIndex 中的“索引”中。索引是 LlamaIndex 中“构建”数据结构的 一个核心抽象 — 这种结构可用于下游的 LLM 检索+查询。索引可以与存储或向量存储抽象交互。
LlamaIndex 中最常用的索引抽象是我们的向量索引,其中每个节点都与一个嵌入一起存储。在此示例中,我们使用简单的内存向量存储,但您也可以选择将 LlamaIndex 的 10 多种向量存储集成中的任何一个指定为存储提供者(例如 Pinecone、Weaviate、Chroma)。
我们构建了两个向量索引:一个用于文档节点,另一个用于博客文章节点,并将它们持久化到磁盘。代码可在此处获取。
from llama_index import GPTVectorStoreIndex
# Store Ray Documentation embeddings
ray_docs_index = GPTVectorStoreIndex(nodes=ray_docs_nodes)
ray_docs_index.storage_context.persist(persist_dir="/tmp/ray_docs_index")
# Store Anyscale blog post embeddings
ray_blogs_index = GPTVectorStoreIndex(nodes=ray_blogs_nodes)
ray_blogs_index.storage_context.persist(persist_dir="/tmp/ray_blogs_index")使用 LlamaIndex + Ray Data 构建数据管线就到这里了!
您的数据现在已准备好在您的 LLM 应用中使用。查看我们下一节,了解如何在数据之上使用高级 LlamaIndex 查询功能。
数据查询
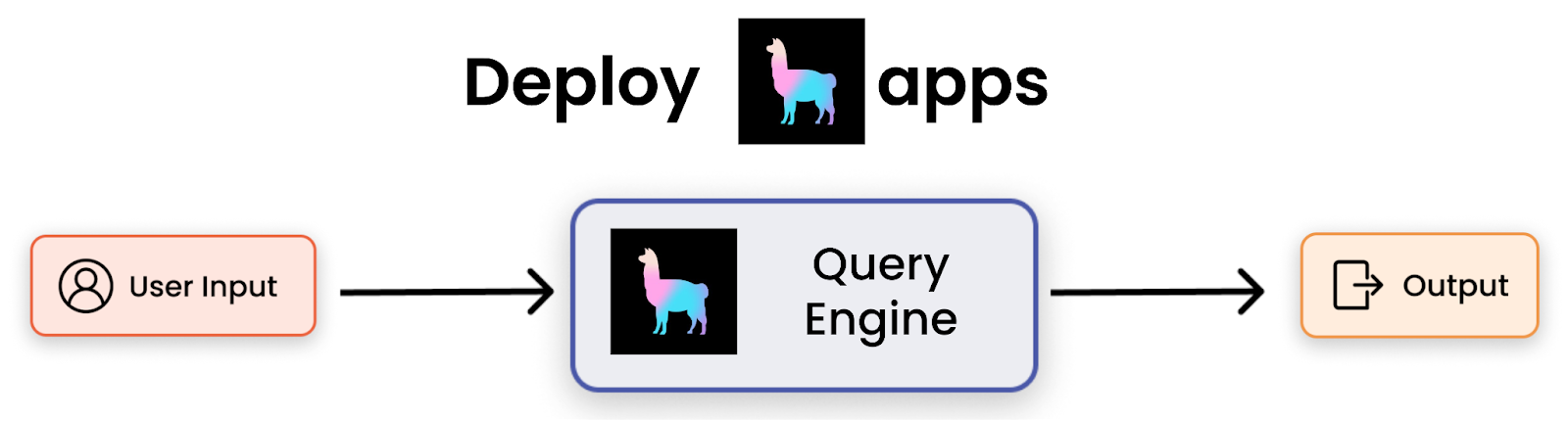
LlamaIndex 在您的数据 + 索引之上提供简单和高级的查询功能。LlamaIndex 中的核心抽象称为“查询引擎”。查询引擎接受自然语言查询输入并返回自然语言“输出”。每个索引都有一个“默认”对应的查询引擎。例如,向量索引的默认查询引擎首先在向量存储上执行 top-k 检索以获取最相关的文档。
这些查询引擎可以轻松地从每个索引派生出来
ray_docs_engine = ray_docs_index.as_query_engine(similarity_top_k=5, service_context=service_context)
ray_blogs_engine = ray_blogs_index.as_query_engine(similarity_top_k=5, service_context=service_context)LlamaIndex 还为多文档用例提供了更高级的查询引擎 — 例如,我们可能想询问 Ray 中的某个特定功能如何在文档和博客中都有体现。`SubQuestionQueryEngine` 可以接受其他查询引擎作为输入。给定一个现有问题,它可以决定将问题分解为任何查询引擎子集上的更简单问题;它将执行这些更简单的问题并在顶层合并结果。
这种抽象非常强大;它可以对单个文档执行语义搜索,或合并多个文档的结果。
例如,给定以下问题“Ray 是什么?”,我们可以将其分解为子问题“文档中关于 Ray 的描述是什么?”和“博客文章中关于 Ray 的描述是什么?”,分别对应文档查询引擎和博客查询引擎。
# Define a sub-question query engine, that can use the individual query engines as tools.
query_engine_tools = [
QueryEngineTool(
query_engine=self.ray_docs_engine,
metadata=ToolMetadata(name="ray_docs_engine", description="Provides information about the Ray documentation")
),
QueryEngineTool(
query_engine=self.ray_blogs_engine,
metadata=ToolMetadata(name="ray_blogs_engine", description="Provides information about Ray blog posts")
),
]
sub_query_engine = SubQuestionQueryEngine.from_defaults(query_engine_tools=query_engine_tools, service_context=service_context, use_async=False)请查看 deploy_app.py 文件以查看完整实现。
使用 Ray Serve 进行部署
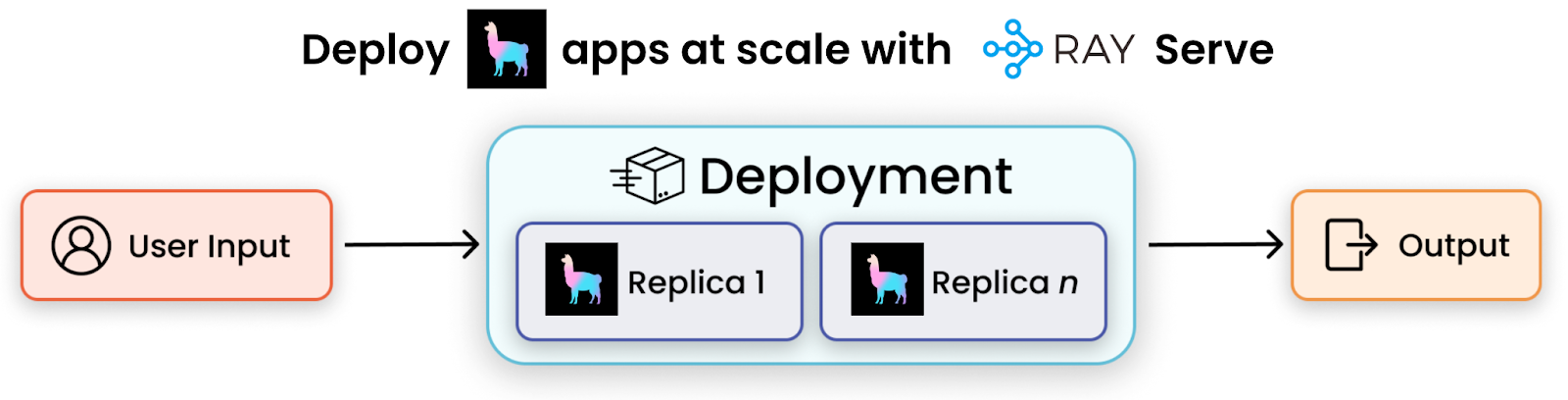
我们现在已经在您的数据之上创建了一个极其强大的查询模块。下一步,如果我们能无缝地将这个功能部署到生产环境并为用户提供服务,那会怎样呢?Ray Serve 让这变得非常容易。Ray Serve 是一个可扩展的计算层,用于服务 ML 模型和 LLMs,它支持服务单个模型或创建复合模型管线,您可以在其中独立地部署、更新和扩展各个组件。
要做到这一点,您只需执行以下步骤:
- 定义一个外部类,它可以“包装”一个查询引擎,并暴露一个“query”端点
- 在此类上添加 `@ray.serve.deployment` 装饰器
- 部署 Ray Serve 应用
它看起来会像这样:
from ray import serve
@serve.deployment
class QADeployment:
def __init__(self):
self.query_engine = ...
def query(self, query: str):
response = self.query_engine.query(query)
source_nodes = response.source_nodes
source_str = ""
for i in range(len(source_nodes)):
node = source_nodes[i]
source_str += f"Sub-question {i+1}:\n"
source_str += node.node.text
source_str += "\n\n"
return f"Response: {str(response)} \n\n\n {source_str}\n"
async def __call__(self, request: Request):
query = request.query_params["query"]
return str(self.query(query))
# Deploy the Ray Serve application.
deployment = QADeployment.bind()请查看 deploy_app.py 获取完整实现。
示例查询
部署应用程序后,我们可以通过关于 Ray 的问题来查询它。
我们可以只查询其中一个数据源
Q: "What is Ray Serve?"
Ray Serve is a system for deploying and managing applications on a Ray
cluster. It provides APIs for deploying applications, managing replicas, and
making requests to applications. It also provides a command line interface
(CLI) for managing applications and a dashboard for monitoring applications.但是,我们也可以提供需要综合文档和博客文章的复杂查询。这些复杂查询很容易通过我们定义的子问题查询引擎处理。
Q: "Compare and contrast how the Ray docs and the Ray blogs present Ray Serve"
Response:
The Ray docs and the Ray blogs both present Ray Serve as a web interface
that provides metrics, charts, and other features to help Ray users
understand and debug Ray applications. However, the Ray docs provide more
detailed information, such as a Quick Start guide, user guide, production
guide, performance tuning guide, development workflow guide, API reference,
experimental Java API, and experimental gRPC support. Additionally, the Ray
docs provide a guide for migrating from 1.x to 2.x. On the other hand, the
Ray blogs provide a Quick Start guide, a User Guide, and Advanced Guides to
help users get started and understand the features of Ray Serve.
Additionally, the Ray blogs provide examples and use cases to help users
understand how to use Ray Serve in their own projects.
---
Sub-question 1
Sub question: How does the Ray docs present Ray Serve
Response:
The Ray docs present Ray Serve as a web interface that provides metrics,
charts, and other features to help Ray users understand and debug Ray
applications. It provides a Quick Start guide, user guide, production guide,
performance tuning guide, and development workflow guide. It also provides
an API reference, experimental Java API, and experimental gRPC support.
Finally, it provides a guide for migrating from 1.x to 2.x.
---
Sub-question 2
Sub question: How does the Ray blogs present Ray Serve
Response:
The Ray blog presents Ray Serve as a framework for distributed applications
that enables users to handle HTTP requests, scale and allocate resources,
compose models, and more. It provides a Quick Start guide, a User Guide, and
Advanced Guides to help users get started and understand the features of Ray
Serve. Additionally, it provides examples and use cases to help users
understand how to use Ray Serve in their own projects.结论
在此示例中,我们展示了如何使用 LlamaIndex + Ray 构建可扩展的数据管线和强大的查询引擎。我们还演示了如何使用 Ray Serve 部署 LlamaIndex 应用。这使您可以轻松地跨不同数据源询问问题并综合关于 Ray 的见解!
我们使用了 LlamaIndex — 一个用于构建 LLM 应用的数据框架 — 来加载、解析、嵌入和索引数据。我们使用 Ray 确保了高效快速的并行执行。然后,我们使用 LlamaIndex 的查询功能对单个文档执行语义搜索,或合并多个文档的结果。最后,我们使用 Ray Serve 将应用打包用于生产环境。
开源实现代码可在 GitHub 上获取:LlamaIndex-Ray-app
下一步?
访问 LlamaIndex 网站和文档,了解更多关于这个用于构建 LLM 应用的数据框架。
访问 Ray 文档,了解如何构建和部署可扩展的 LLM 应用。
加入我们的社区!
- 在 Slack 上加入 Ray 社区和 Ray #LLM 频道。
- 您也可以在 discord 上加入 LlamaIndex 社区。
我们的 Ray Summit 2023 早鸟注册开放至 6 月 30 日。锁定您的位置,节省一些费用,并在峰会上享受社区情谊。



