Jerry Liu • 2023-06-23
使用 LlamaIndex 和 TruLens 构建和评估 LLM 应用
作者: Anupam Datta, Shayak Sen, Jerry Liu, Simon Suo
原文链接:https://truera.com/build-and-evaluate-llm-apps-with-llamaindex-and-trulens/
LlamaIndex 是一个流行的开源框架,用于构建 LLM 应用。TruLens 是一个开源库,用于评估、跟踪和迭代 LLM 应用以提高其质量。LlamaIndex 和 TruLens 团队正积极合作,使 LLM 应用开发者能够快速构建、评估和迭代他们的应用。
在 TruLens 的最新版本中,我们引入了基于 LlamaIndex 的 LLM 应用追踪功能,只需几行代码即可评估和跟踪您的实验。这使得您可以自动评估应用堆栈的多个不同组件,包括:
- 应用输入和输出
- LLM 调用
- 从索引中检索到的上下文块
- 延迟
- 成本和 Token 计数(即将推出!)
查看此notebook以开始使用,并对照阅读以获得分步视图。
我该如何实际使用它?
构建 LlamaIndex 应用
LlamaIndex 让您可以将数据连接到 LLM,并针对多种不同用例快速构建应用。
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('llama_index/data').load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()构建应用后,您可以轻松查询数据
response = query_engine.query("What did the author do growing up?")
print(response)并获得相应的回复。
Growing up, the author wrote short stories, programmed on an IBM 1401, and nagged his father to buy him a TRS-80 microcomputer. He wrote simple games, a program to predict how high his model rockets would fly, and a word processor. He also studied philosophy in college, but switched to AI after becoming bored with it. He then took art classes at Harvard and applied to art schools, eventually attending RISD.使用 TruLens 包装 LlamaIndex 应用
使用 TruLens,您可以使用 TruLlama 包装器包装 LlamaIndex 查询引擎。此包装器保留了 LlamaIndex 的所有行为,但会跟踪所有中间步骤,以便对其进行单独评估。
from trulens_eval import TruLlama
l = TruLlama(query_engine)现在可以使用完全相同的方式查询被包装的应用
response = l.query("What did the author do growing up?")
print(response)不同的是,现在查询的详细信息会被 TruLens 记录下来。
添加反馈函数
现在,为了评估模型的行为,我们可以向您的被包装应用添加反馈函数。请注意,作为开发者,您只需添加几行代码即可开始在应用中使用反馈函数。您还可以轻松添加根据您的应用需求量身定制的函数。
我们使用反馈函数的目标是以编程方式检查应用质量指标。
- 第一个反馈函数检查提示和回复之间的语言匹配。这是一个有用的检查,因为用户的一个自然期望是回复语言与提示语言相同。它是通过调用 HuggingFace API 来实现的,该 API 会以编程方式检查语言匹配。
- 下一个反馈函数通过使用一个被提示生成相关性得分的 OpenAI LLM 来检查答案与问题的相关性。
- 最后,第三个反馈函数检查从向量数据库中检索到的单个块与问题的相关性,同样以类似方式使用 OpenAI LLM。这非常有用,因为从向量数据库检索的步骤可能会产生与问题不相关的块,如果在生成最终回复之前过滤掉这些块,最终回复的质量会更好。
from trulens_eval import TruLlama, Tru, Query, Feedback, feedback
# Initialize Huggingface-based feedback function collection class:
hugs = feedback.Huggingface()
openai = feedback.OpenAI()
# Define a language match feedback function using HuggingFace.
f_lang_match = Feedback(hugs.language_match).on_input_output()
# By default this will check language match on the main app input and main app
# output.
# Question/answer relevance between overall question and answer.
f_qa_relevance = Feedback(openai.relevance).on_input_output()
# Question/statement relevance between question and each context chunk.
f_qs_relevance = Feedback(openai.qs_relevance).on_input().on(
TruLlama.select_source_nodes().node.text
).aggregate(np.min)
feedbacks = [f_lang_match, f_qa_relevance, f_qs_relevance]
l = TruLlama(app=query_engine, feedbacks=feedbacks)在仪表盘中探索
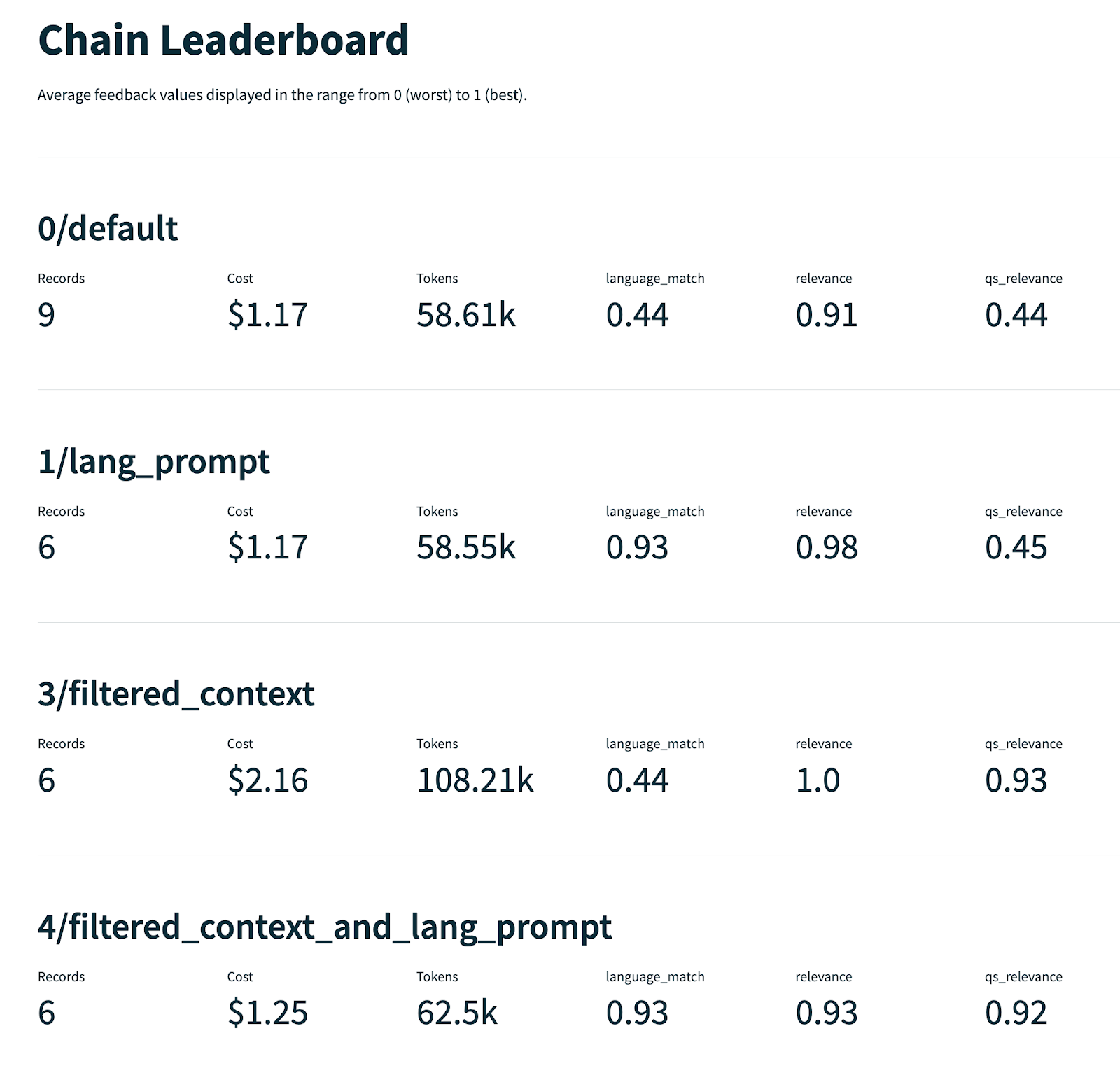
现在可以在 TruLens 仪表盘中查看每个被跟踪的查询。在对一组记录(交互)运行反馈函数后,您可以在排行榜上看到评估的汇总结果;然后深入查看特定应用版本,并检查其在单个记录上的表现。这些步骤可以帮助您了解应用版本的质量及其失效模式。
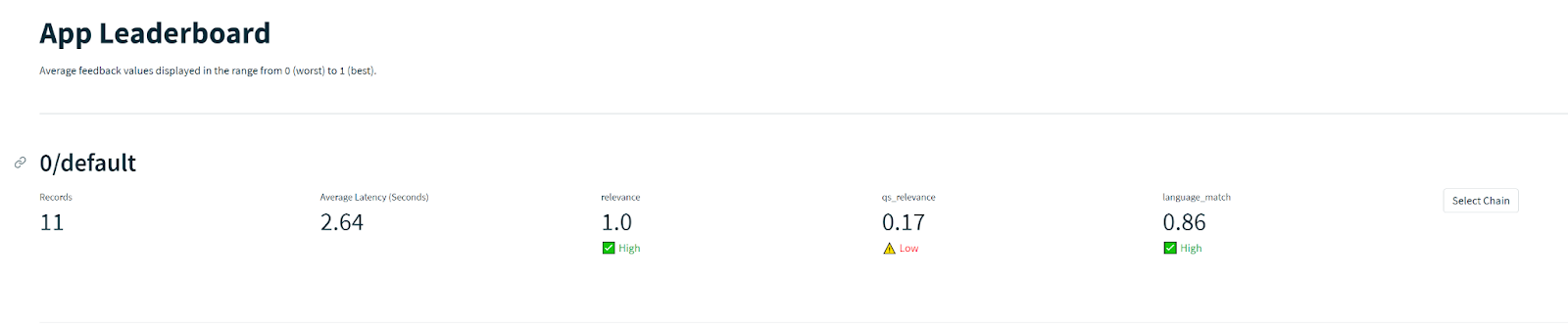
在此示例中,模型在相关性和语言匹配反馈评估方面表现相当好,但在 qs_relevance 方面表现似乎不佳。这可能表明检索到的块通常是不相关的。这可能是检索增强型生成式 AI 应用中“幻觉”的重要来源。
现在我们可以深入分析并找出可能出现此问题的具体实例

首先看一个好例子。“作者小时候做了什么?”
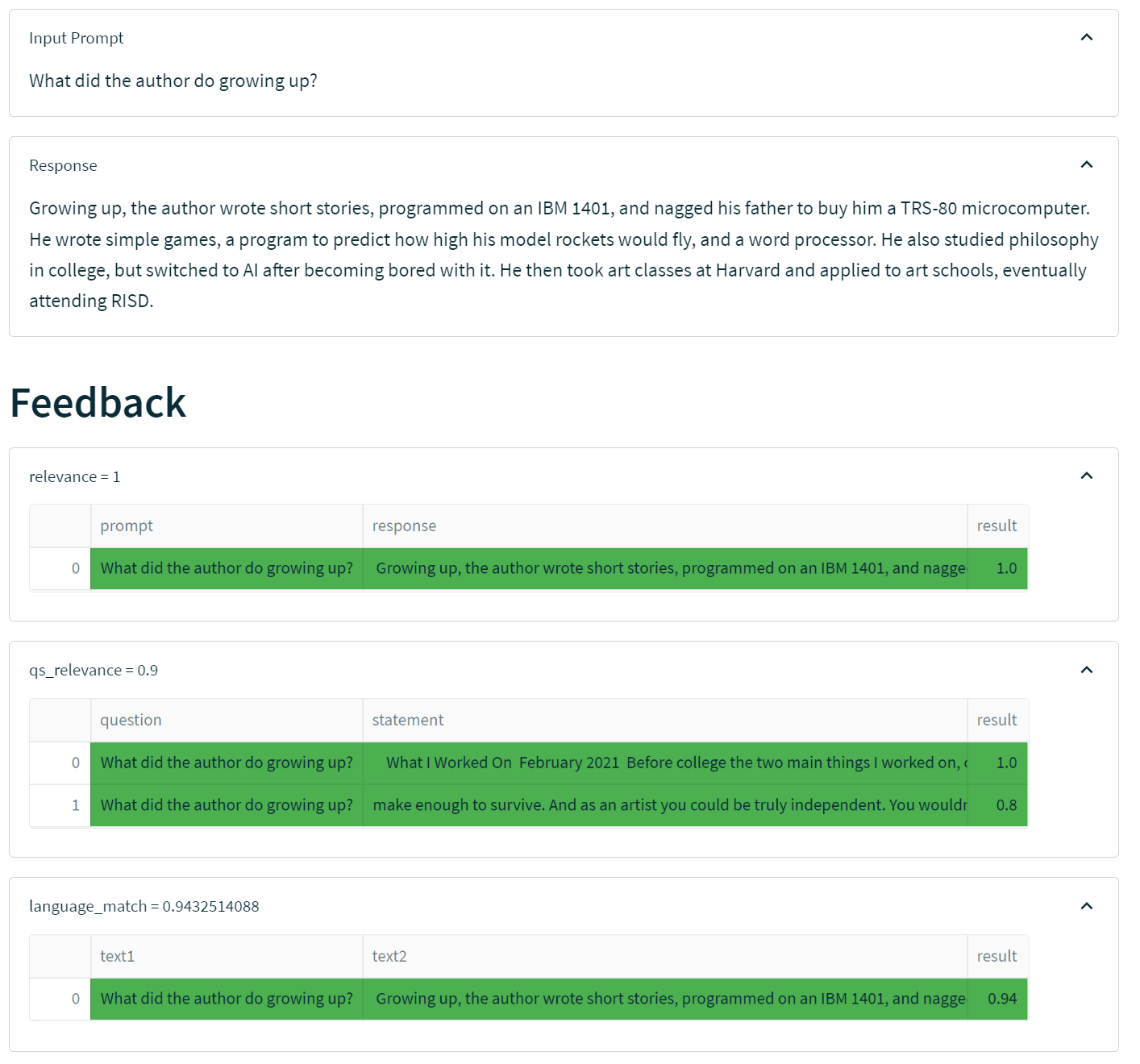
在此示例中,我们从索引中检索了两个块,这两个块都与问题相当相关,因此 LLM 将其总结为一个相关且事实正确的答案。
另一方面,我们看一个不太顺利的例子:“作者在哪里出生?”。在此示例中,应用自信地提供了一个不正确的答案。
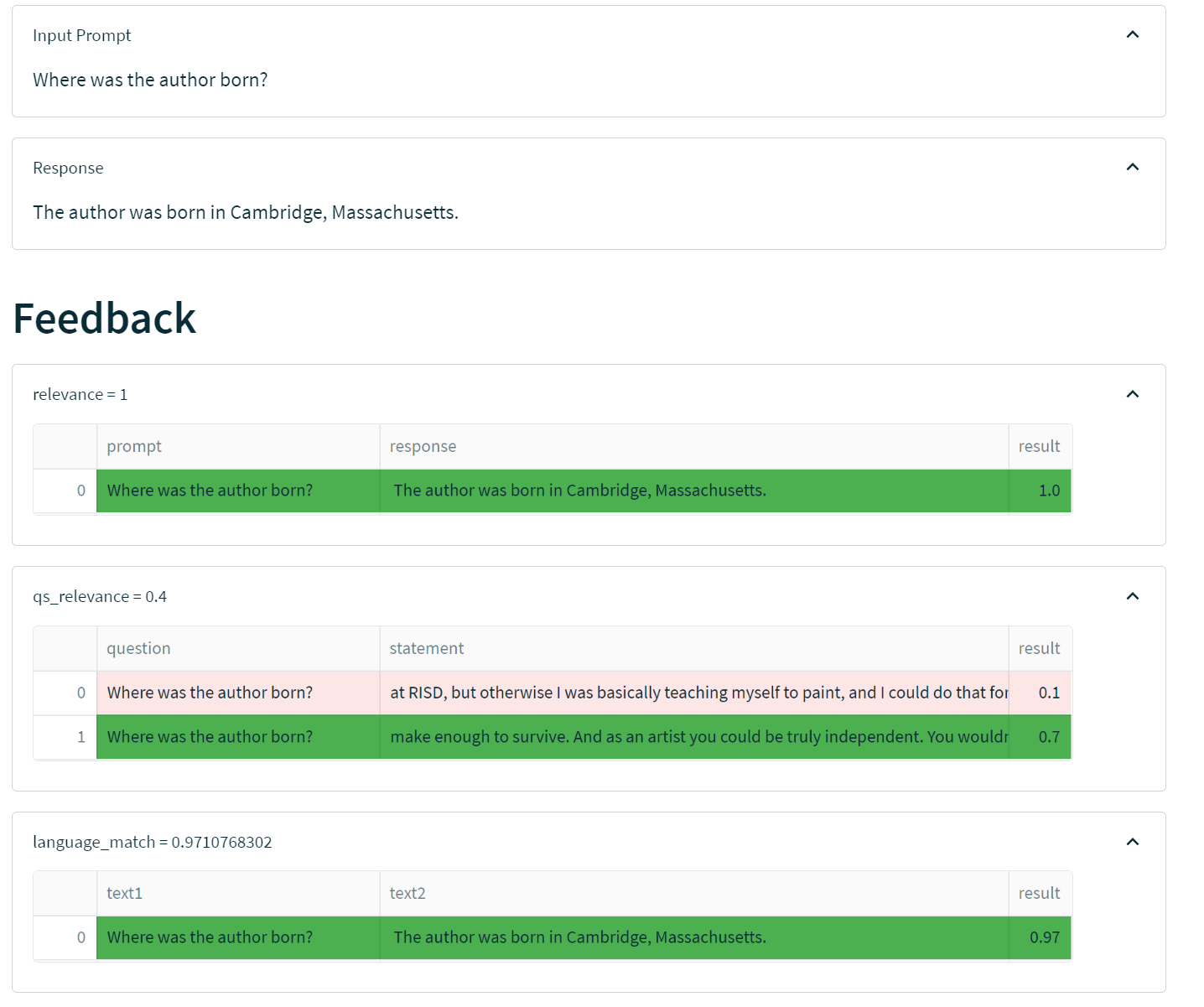
在此示例中,检索到的两个上下文片段与问题的相关性中等。此外,这两个上下文都不包含答案。尽管我们的相关性反馈函数(不检查事实正确性)没有检测到问题,但由于基础块的相关性不高,这强烈表明有问题。事实上,这是一个模型在回答一个相当容易事实核查的问题时出现“幻觉”的例子。
迭代您的应用
一旦您发现应用存在此类问题,迭代您的提示、模型和分块方法以优化应用会很有帮助。在此过程中,您可以使用 TruLens 跟踪每个版本模型的性能。这是一个仪表盘示例,显示了多个迭代相互测试的情况。