
Jerry Liu • 2023-05-18
使用 LlamaIndex 和 MongoDB 构建一个带私有数据的 ChatGPT
合著者
- Prakul Agarwal — MongoDB 机器学习高级产品经理
- Jerry Liu — LlamaIndex 联合创始人
更新 (2023 年 6 月 22 日): 使用 LlamaIndex + MongoDB 的推荐方式现在是使用我们的 MongoDBAtlasVectorSearch 类。请参阅此处指南: https://gpt-index.readthedocs.io/en/latest/examples/vector_stores/MongoDBAtlasVectorSearch.html
摘要
大型语言模型(LLM),如 ChatGPT,彻底改变了用户获取问题答案的方式。然而,LLM 的“知识”受限于其训练数据,对于 ChatGPT 而言,这意味着直到 2021 年 9 月互联网上的公开信息。LLM 如何才能使用您的公司数据等私有知识源来回答问题,并释放其真正的变革力量?
本篇博客将讨论 LlamaIndex 和 MongoDB 如何帮助您快速实现这一目标。 附带的代码本 提供了关于如何使用英文查询任何 PDF 文档的代码演示。
背景
传统上,人工智能被用于分析数据、识别模式并基于现有数据进行预测。最近的进展使得人工智能在生成新事物(而不仅仅是分析现有事物)方面变得更强。这被称为生成式人工智能(Generative AI)。生成式人工智能主要由称为大型语言模型(LLM)的机器学习模型驱动。LLM 在大量公开可用文本上进行预训练。有来自 OpenAI、Cohere、AI21 等公司的各种专有 LLM,以及许多新兴的开源 LLM,如 Llama、Dolly 等。
LLM 的知识不足主要有 2 种情况
- 私有数据,例如您公司分散在 PDF、Google Docs、Wiki 页面以及 Salesforce 和 Slack 等应用中的内部知识库
- 比 LLM 上次训练时更新的数据。示例问题:英国现任首相是谁?
目前有两种主要范式来扩展 LLM 出色的推理和知识生成能力:模型微调(Model finetuning)和情境学习(in-context learning)。
模型微调的操作可能更复杂且昂贵。还存在一些悬而未决的问题,例如如何从微调模型中删除信息以确保遵守当地法律(例如欧洲的 GDPR),以及对于不断变化的数据,您需要持续重新微调。
情境学习需要将新数据作为输入提示的一部分插入到 LLM 中。以安全、高性能且成本效益的方式执行这种数据增强,正是 LlamaIndex 和 MongoDB Developer Data Platform 等工具能够提供帮助的地方。
LlamaIndex 简介
LlamaIndex 提供了一个简单灵活的接口,用于连接 LLM 与外部数据。
- 提供连接到各种数据源和数据格式(API、PDF、文档等)的数据连接器。
- 提供用于 LLM 的非结构化和结构化数据的索引。
- 结构化外部信息,使其可以在任何 LLM 的提示窗口限制下使用。
- 公开一个查询接口,接收输入提示并返回知识增强的输出。
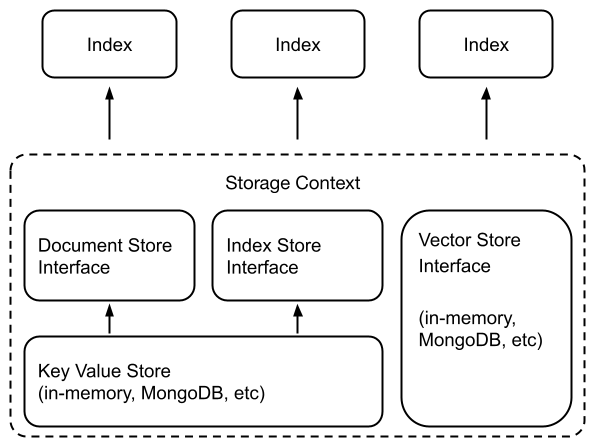
MongoDB 作为数据存储
使用 LlamaIndex 内置的抽象,将摄入的文档(即 Node 对象)、索引元数据等存储到 MongoDB 中非常容易。有一个选项可以使用 MongoDocumentStore 将“文档”作为实际集合存储在 MongoDB 中。有一个选项可以使用 MongoIndexStore 持久化“索引”。
在以下几种情况下,将 LlamaIndex 的文档和索引存储到数据库中变得必要
- 处理大型数据集的用例可能需要不止内存存储。
- 从各种来源(例如,PDF、Google Docs、Slack)摄入和处理数据。
- 需要持续维护底层数据源的更新。
能够持久化这些数据使得一次处理数据后,即可为各种下游应用进行查询。
MongoDB Atlas
MongoDB 在您选择的公共云服务中提供永久免费的 Atlas 集群。通过遵循此 教程,可以非常快速地完成此操作。或者您可以直接从 此处 开始。
LLM 的使用
LlamaIndex 使用 LangChain(另一个流行的构建生成式人工智能应用的框架)的 LLM 模块,并允许自定义使用的底层 LLM(默认为 OpenAI 的 text-davinci-003 模型)。LlamaIndex 始终使用选定的 LLM 来构建最终答案,有时也在创建索引时使用。
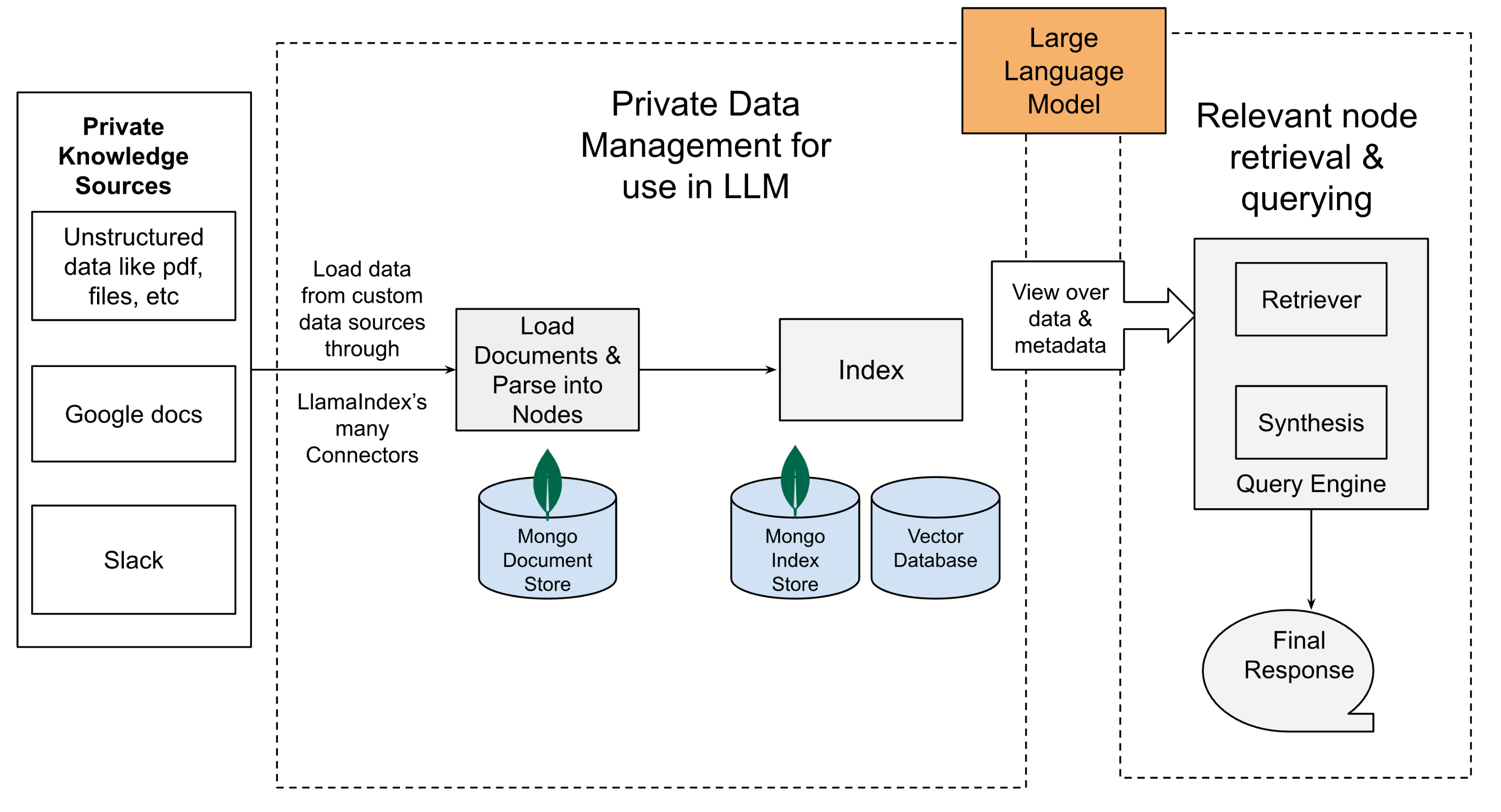
工作流程
- 使用 LlamaIndex 连接器连接私有知识源(通过 LlamaHub 提供)。
- 加载文档。文档表示围绕数据源的轻量级容器。
- 将文档对象解析为 Node 对象。节点表示源文档的“块”(例如,文本块)。这些节点对象可以持久化到 MongoDB 集合中或保存在内存中。
- 从 Node 构建索引。LlamaIndex 中有各种类型的索引,例如“列表索引”(List Index,将节点存储为顺序链)和“向量存储索引”(Vector Store Index,将每个节点及其对应的嵌入存储在向量存储中)。根据索引类型,这些索引可以持久化到 MongoDB 集合或向量数据库中。
- 最后查询索引。在此过程中,查询被解析,通过使用索引检索到相关的 Node,并将其作为输入提供给“大型语言模型”(LLM)。不同类型的查询可以使用不同的索引。
在您的私有数据上获取问题答案
我们想查询 OpenAI 于 2023 年 3 月发布的《GPT-4 技术报告》。这是一份 PDF 文档,共 100 页。这是一份最近发布的文档,因此未包含在原始 ChatGPT 训练数据中。
以下是我们对该 PDF 文档提出的各种查询的总结。
查询
“GPT4 在律师资格考试中的表现如何?”
回答
“GPT-4 在统一律师资格考试中表现出色,得分排在前 10% 的考生之列(表 1,图 4)。”
LLM token 使用量
总嵌入 token 使用量:18 tokens 总 LLM token 使用量:1889 tokens
查询
“相对于 GPT-3.5,GPT-4 在减少幻觉方面表现好多少?”
回答
“GPT-4 比最新的 GPT-3.5 模型提高了 19 个百分点,在所有主题上都有显著提升。”
查询
“使用 RHLF 微调 GPT-4 后观察到哪些问题??”
回答
“使用 RHLF 微调 GPT-4 后观察到的问题包括模型在某些方面变得过于谨慎,例如拒绝无害的请求,以及过度规避或“过度拒绝”。此外,模型仍然相当脆弱,有时会根据对标注者指示不够明确的提示表现出不期望的行为。”
查询
“RBRM 是什么?”
回答
“RBRM 代表基于规则的奖励模型(Rule-Based Reward Model)。它是一种技术,用于在对训练提示子集进行 PPO 微调期间,为 GPT-4 策略模型提供额外的奖励信号。RBRM 接收三项输入:提示(可选)、策略模型的输出,以及用于评估此输出的人工编写的评分标准(例如,一套选择题式的规则)。然后,RBRM 根据评分标准对输出进行分类。”
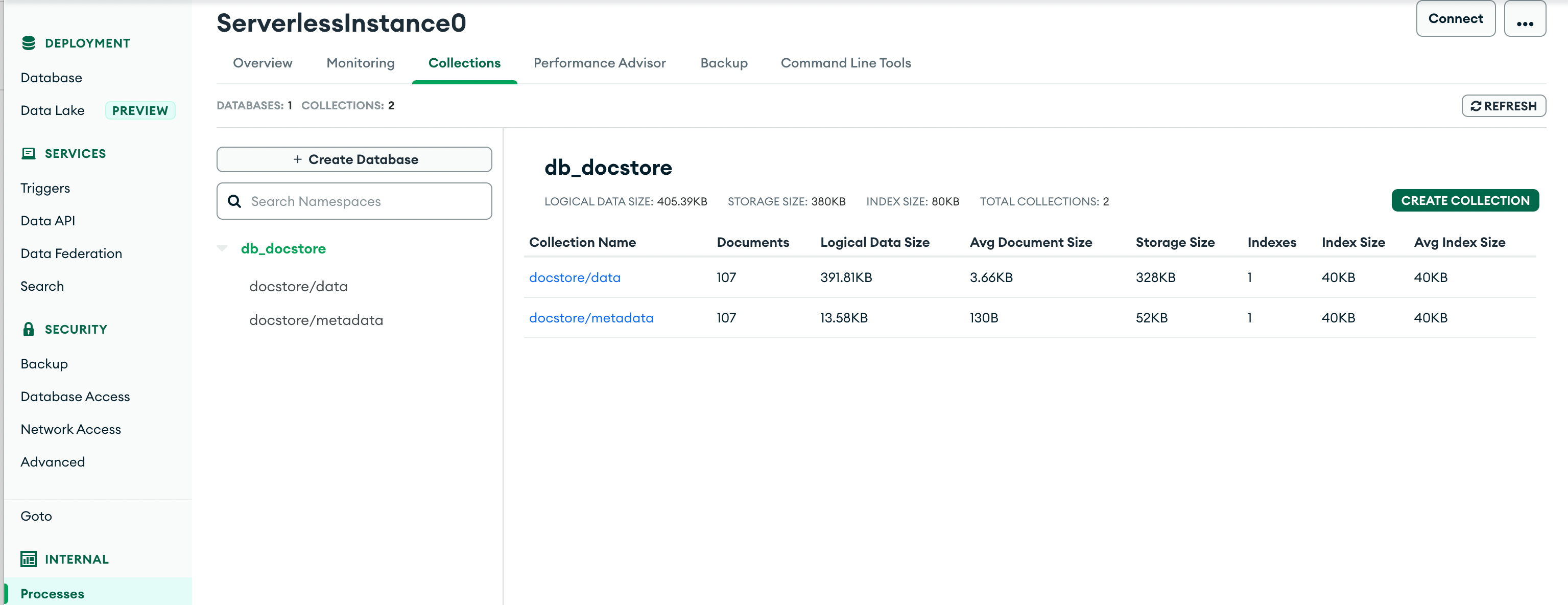
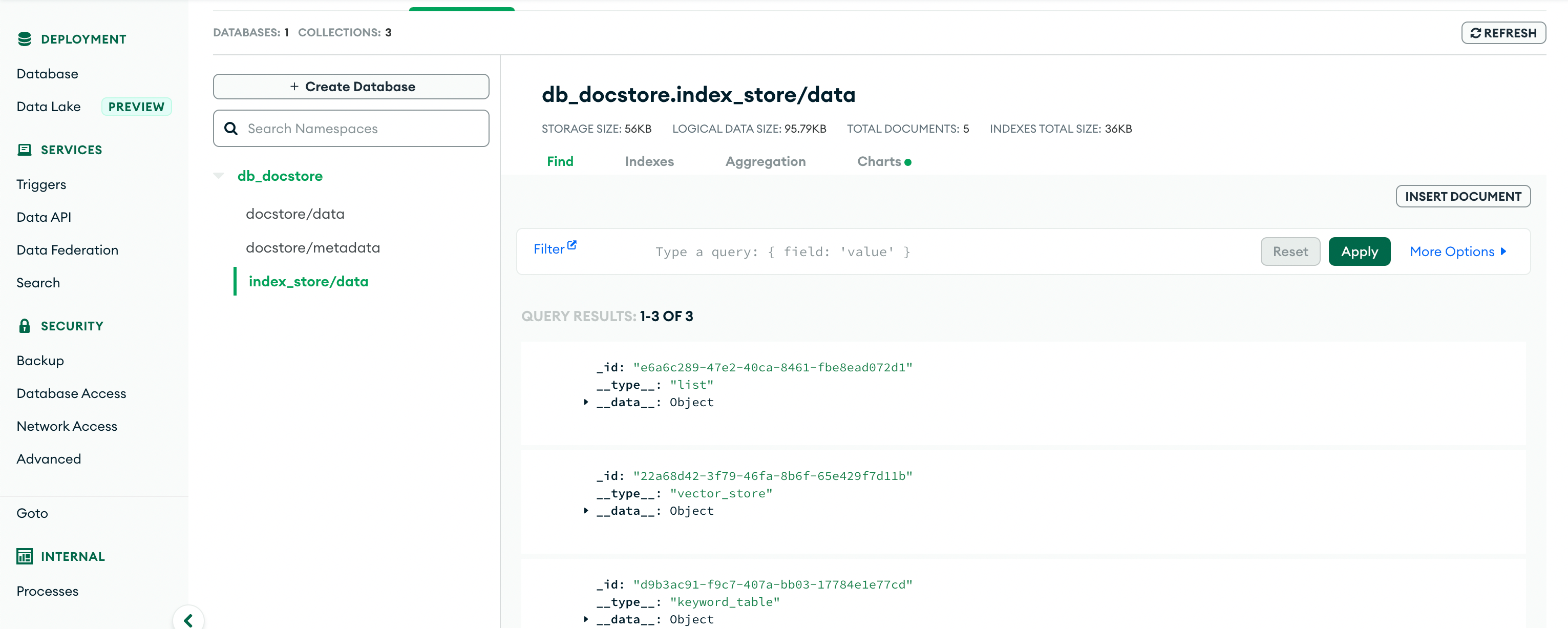
以下截图显示了如何将 PDF 文档转换为“LlamaIndex 节点”和“LlamaIndex 索引”,并持久化到 MongoDB 中。
相关资源
此处可找到更多详细信息。另请参阅下面的参考代码本!
从 MongoDB 读取数据: 链接
LlamaIndex 中的各种索引: 链接
参考代码本
https://colab.research.google.com/drive/1SNIeLW38Nvx6MtL3-_LPS2XTIzqD4gS6?usp=sharing



