
Tim Ho • 2023-10-27
NewsGPT(Neotice):使用 LlamaIndex 汇总新闻文章 — 黑客马拉松获奖应用
我们很高兴与您分享 NewsGPT (Neotice) — 点击诱饵终结者这款 Streamlit LLM 黑客马拉松获奖应用的思考过程和解决方案设计,该应用由 LlamaIndex、Streamlit 和 Qdrant 提供支持。在本文中,我们将定义我们试图解决的问题并讨论我们的方法。最后,我们提供了一个解决方案,以便在 Streamlit Chat Bot 上启用 LlamaIndex 流式传输,所有代码都可以在此处找到。我们希望我们的见解对您有所帮助和启发。
引言
问题陈述
显然,人们获取信息的习惯随着时间发生了变化。以前,我们阅读长篇文章内容和观看长视频,例如报纸和 YouTube 视频。然而,目前我们更喜欢阅读标题和消费短视频内容,例如 TikTok 和 YouTube Shorts。虽然这种转变使得在更短的时间内获取更多信息变得更容易,但也导致了包含错误信息的“点击诱饵”标题。
当我们开始开发 NewsGPT 时,我们的主要重点是解决上述痛点,并提供一个 1) 提供准确信息 和 2) 为用户节省时间 的解决方案。
Neotice

我们很高兴地宣布,Neotice 应用的测试版现已上线供用户试用!它是 NewsGPT 的生产版本。我们感谢 Streamlit 黑客马拉松展示了我们的原型和理念。借助这个平台,我们相信我们的应用将彻底改变人们获取新闻的方式。
NewsGPT 脱颖而出之处
NewsGPT 主要包含四个组成部分:可靠的新闻来源、量身定制的新闻推荐、高效的信息检索和时间节省器。
✅ 可靠的新闻来源:
- 我们建立了一个动态数据管道,旨在每日获取新闻,确保我们的信息及时更新且具有相关性。
- 集成了复杂的命名实体识别、使用 OpenAI API 的文本嵌入和异步文章嵌入过程。这些数据系统地存储在 Qdrant 向量数据库中,提高了准确性和效率。
✅ 量身定制的新闻推荐:
- 我们的系统不仅仅是呈现新闻,它还会向您学习。通过分析您的阅读习惯,我们利用文章嵌入来为您精心打造符合您个人兴趣的新闻推送。
- 始终提供一个多功能的搜索栏,允许用户探索任何吸引他们兴趣的新闻话题。
✅ 高效的信息检索:
- 只只需单击感兴趣的文章,NewsGPT 便会开始工作。它会整理来自多个来源(3-5 个)的相似新闻并启动一个 Streamlit 聊天机器人。
- 您的互动即刻开始:第一个查询会自动转发到我们的聊天机器人以获取简洁的新闻摘要。
- 为了方便用户体验,我们将预定义提示显示为可点击按钮。这意味着用户无需手动输入即可获取信息。
- 欢迎提问:只要答案在源文章中有详细说明,用户对新闻文章的任何问题都会得到解答。
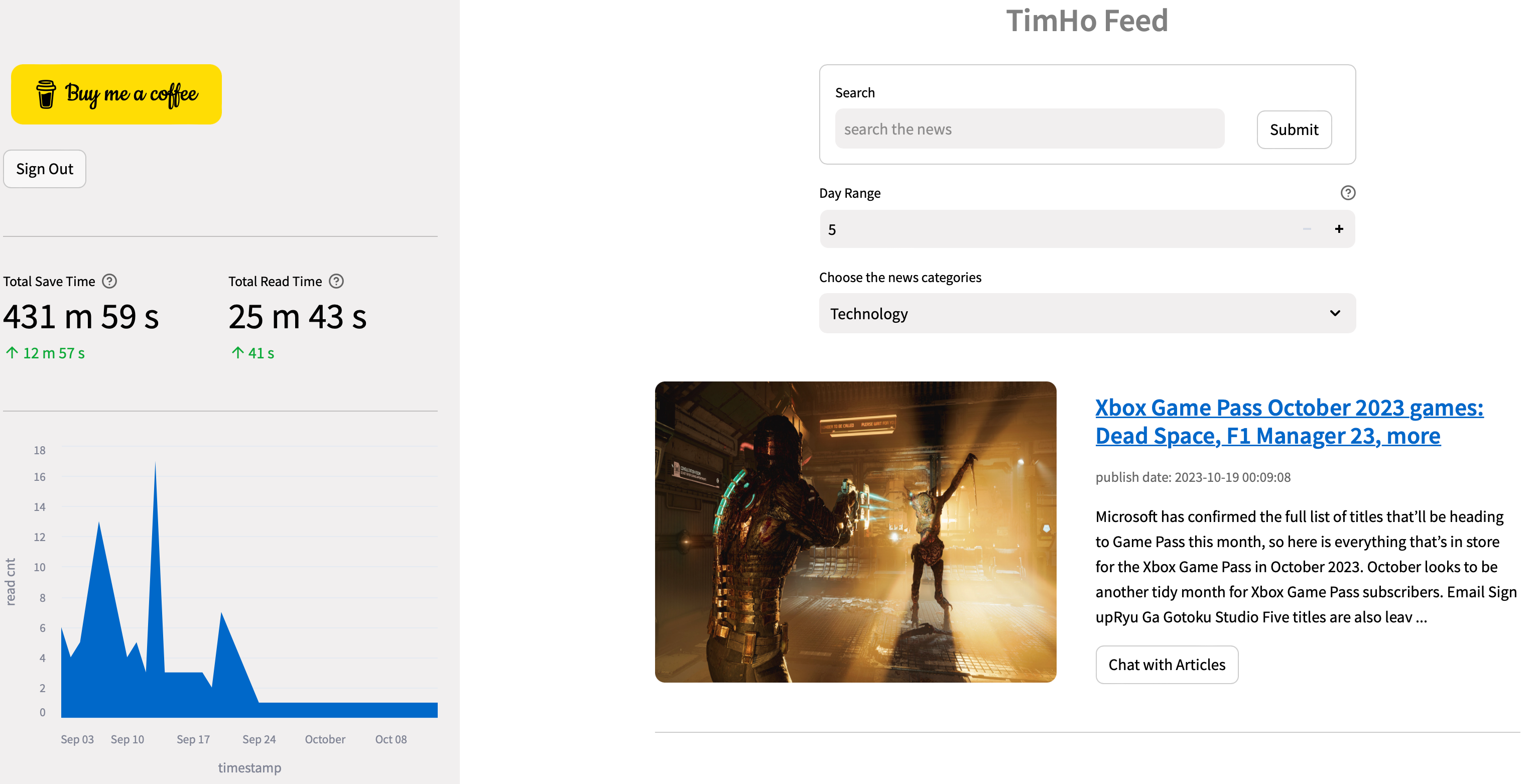
✅ 节省时间提醒与类别分布图表:
- 为了让您及时了解信息,我们的侧边栏会显示使用 NewsGPT 节省的时间,并直观地展示新闻类别分布。

深入探讨架构
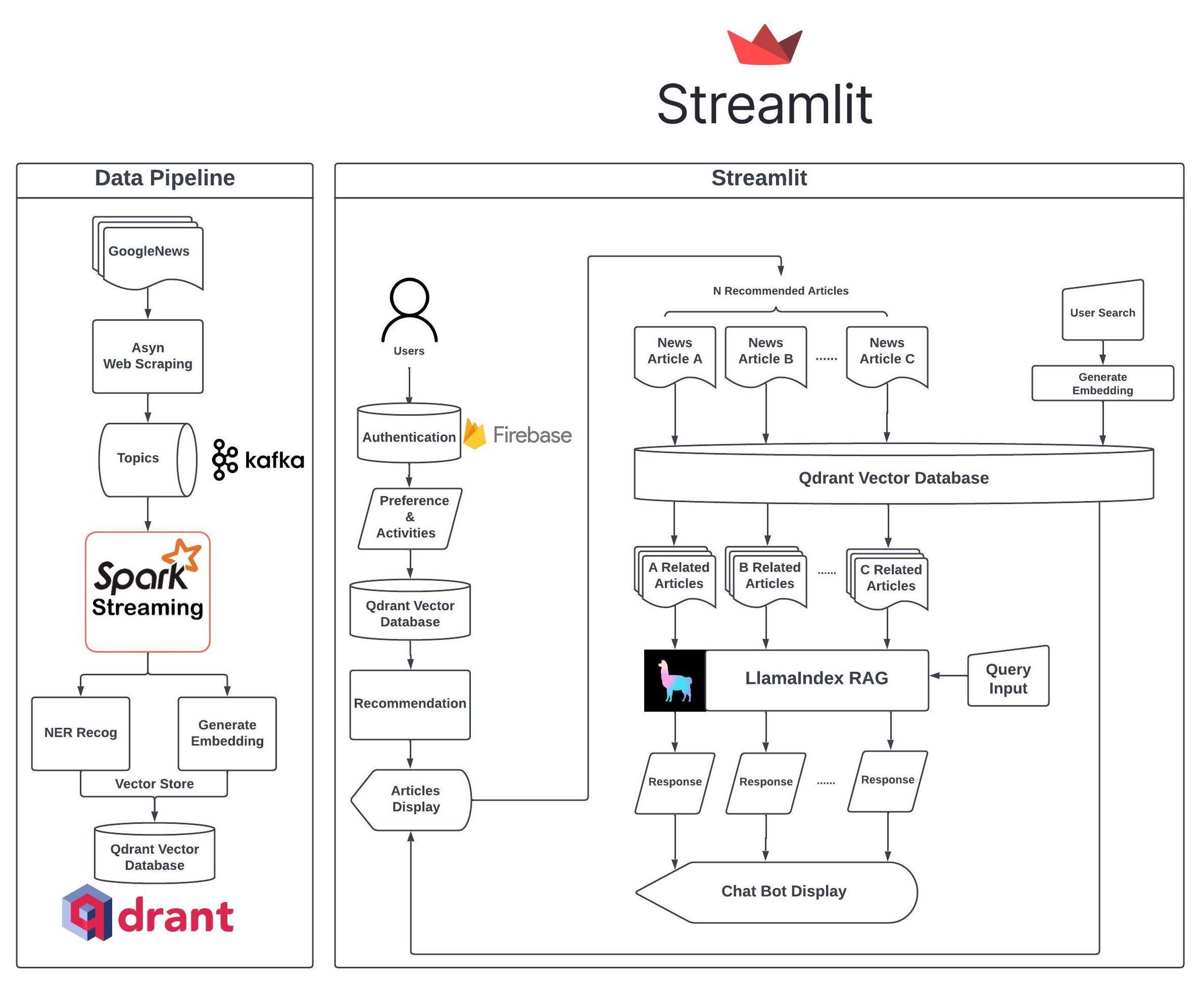
数据管道
我们从一个可靠且可持续的数据管道开始,使用两个强大的库——pygooglenews 和 newspaper3k 来帮助用户获取最新新闻。
pip install pygooglenews --upgrade
pip install newspaper3k通过利用 Spark 批处理,我们高效地处理数据,进行 NER(命名实体识别),并通过 OpenAI API(Ada 模型)创建嵌入。数据预处理后,我们将元数据(包括关键词、NER 结果、摘要、正文、标题、作者等)收集到负载中,并将带有嵌入的负载推送到 Qdrant 向量数据库。
我们将跳过如何使用 OpenAI Ada 模型创建嵌入的部分,因为有许多现有的教程可用。为了执行命名实体识别,我们使用了 HuggingFace 的 dslim/bert-base-NER 模型。
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
nlp = pipeline("ner", model=model, tokenizer=tokenizer, batch_size=batch_size)
ner_results = nlp(texts)个性化
访问 NewsGPT 时,我们有两种选择:可以创建新账户或使用访客登录来测试服务。但需要注意的是,使用访客登录将不会提供个性化服务。如果选择注册,系统会询问您偏好的新闻类别,这有助于服务在冷启动期间提供初步推荐。
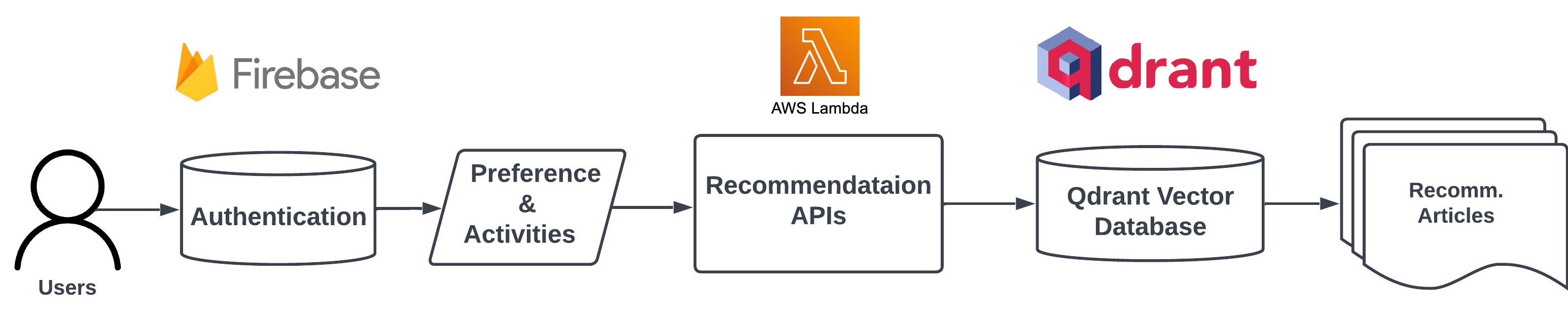
用户注册并登录后,我们会从 Google Firebase 查询偏好和活动(如果有);否则,使用喜欢的类别进行推荐冷启动。如果活动和偏好可用,我们将调用托管在 AWS Lambda 上的推荐 API,为用户生成个性化文章。活动与用户的阅读历史相关。用户可以通过点击文章页面上的点赞或点踩按钮来表明他们对文章的偏好。部分推荐逻辑可在此处的代码中找到。
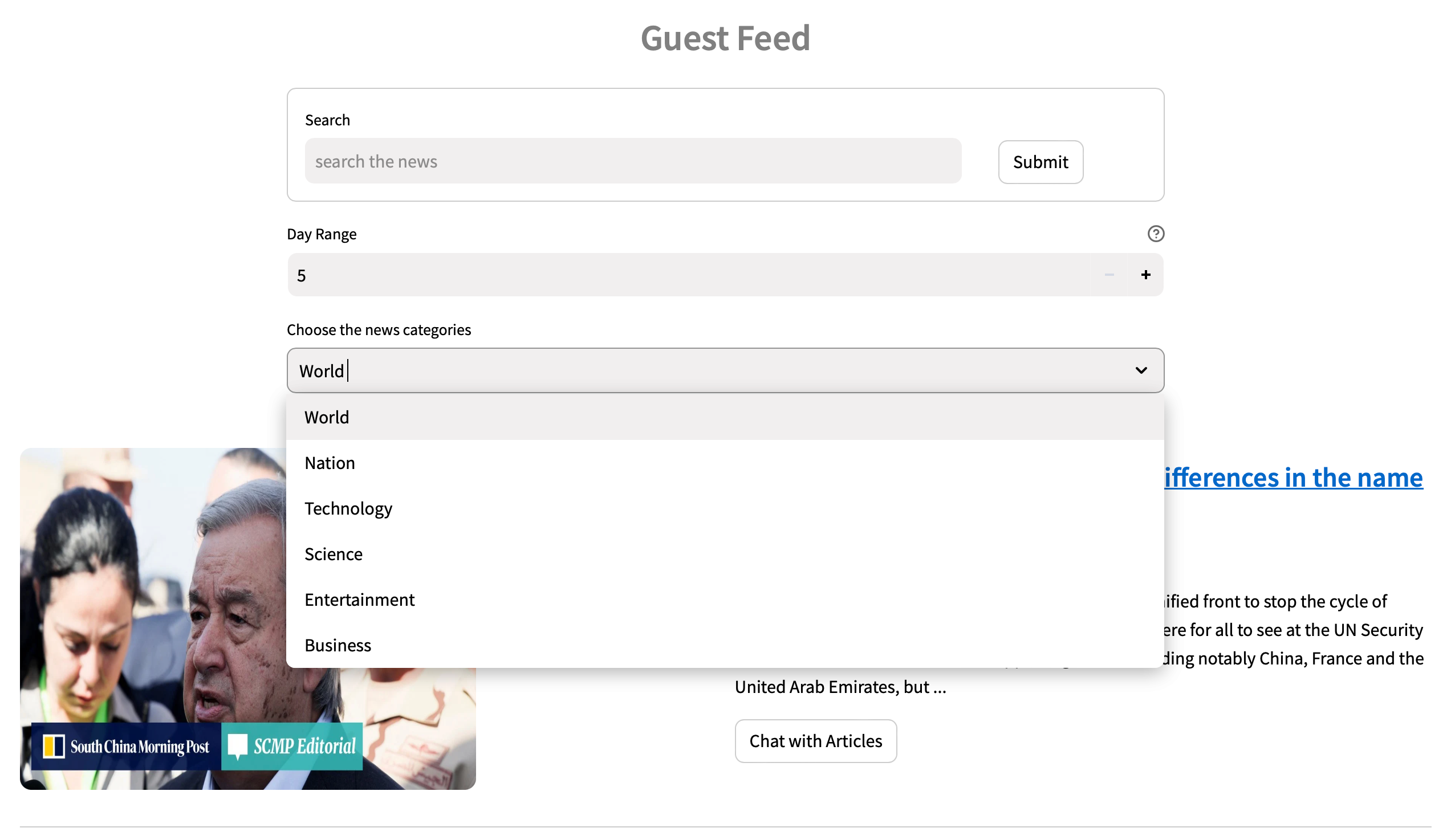
除了个性化推送外,用户还可以选择不同的类别或使用搜索栏搜索特定主题。
由 LlamaIndex 提供支持的文章聊天功能
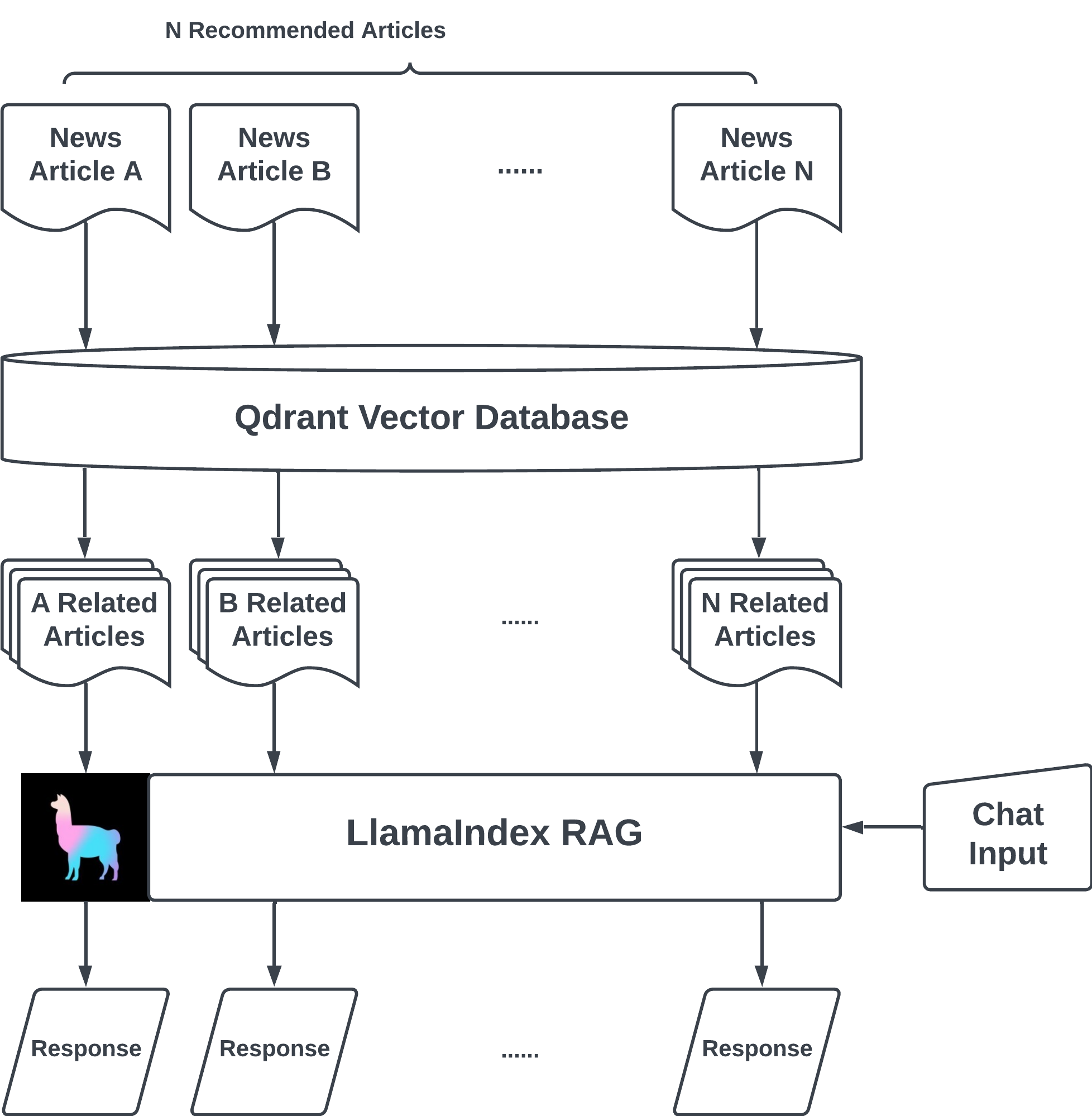
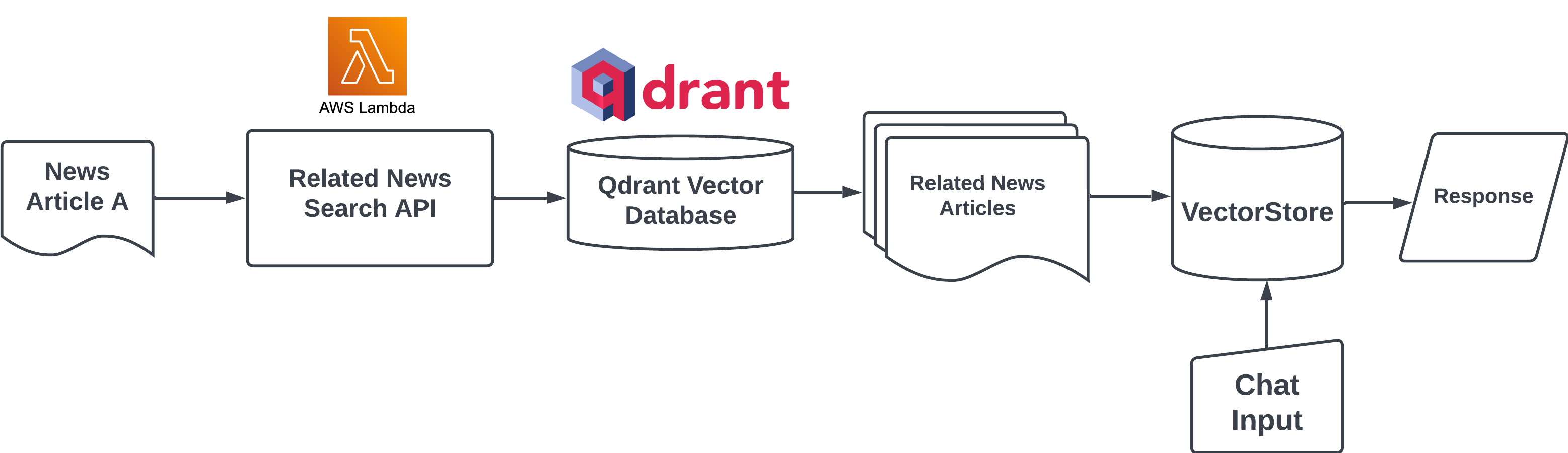
与其他新闻聚合应用不同,NewsGPT 提供了一项独特服务,即为用户提供来自各种新闻来源的关于某一主题的摘要和差异关键信息。此功能不仅通过无需阅读多篇文章为用户节省时间,而且通过比较差异帮助识别哪些信息值得信赖。其幕后原理是,当用户点击“与文章聊天”按钮时,系统首先使用托管在 AWS Lambda 上的搜索 API 查找来自各种来源的相关文章。然后,系统利用 LlamaIndex 库创建向量存储和查询引擎,该引擎可以与 Streamlit 聊天组件集成,以构建一个用于信息检索的 RAG(检索增强生成)应用。
使用 LlamaIndex 和 Streamlit 实现流式输出
感谢强大的库 Streamlit-Extras,它提供了官方不支持的额外功能。为了增强用户体验,使其更像与 ChatGPT 聊天,我们使用了 Streamlit-Extras 库中的 streaming_write 函数。此外,我们将 query_engine 的 streaming 参数设置为 True,以确保更流畅的体验。让我们看看代码。
pip install streamlit-extras首先,我们设置了 service_context。
from llama_index import ServiceContext
st.session_state["service_context"] = ServiceContext.from_defaults(
llm=OpenAI(
model="gpt-3.5-turbo",
temperature=0.2,
chunk_size=1024,
chunk_overlap=100,
system_prompt="As an expert current affairs commentator and analyst,\
your task is to summarize the articles and answer the questions from the user related to the news articles",
),
chunk_size=256,
chunk_overlap=20
)接下来,我们使用 TokenTextSplitter 创建一个文本分割器,并使用 SimpleNodeParser 创建一个节点解析器来解析多篇文章。
from llama_index.text_splitter import TokenTextSplitter
from llama_index.node_parser import SimpleNodeParser
text_splitter = TokenTextSplitter(separator=" ", chunk_size=256, chunk_overlap=20)
#create node parser to parse nodes from document
node_parser = SimpleNodeParser(text_splitter=text_splitter)
nodes = node_parser.get_nodes_from_documents(documents)第三步,我们使用 VectorStoreIndex 创建索引。要启用流式传输功能,请确保在设置 query_engine 时将 streaming 设置为 True。
from llama_index import VectorStoreIndex
index = VectorStoreIndex(
nodes=nodes,
service_context=st.session_state["service_context"]
)
st.session_state["chat_engine"] = index.as_query_engine(streaming=True)为了将流式传输功能添加到 Streamlit 聊天组件中,我们借鉴了这段代码的思路。我们没有使用常规聊天实现中的 st.write(),而是将其替换为 streaming_write 中的 write 函数。
response = st.session_state["chat_engine"].query(prompt)
def stream_example():
for word in response.response_gen:
yield word
write(stream_example)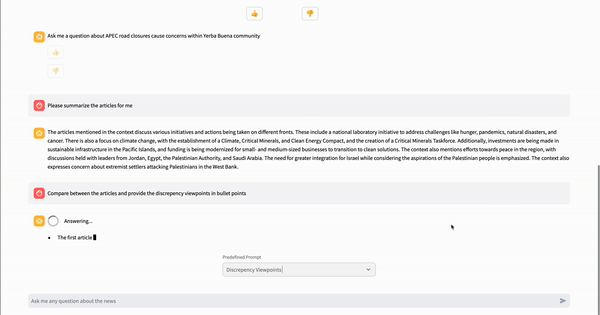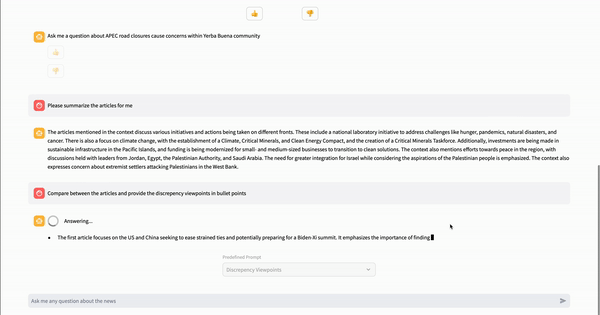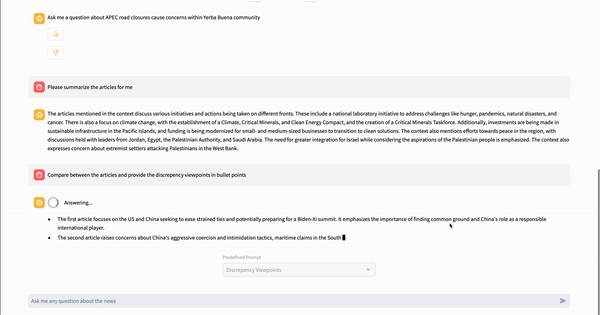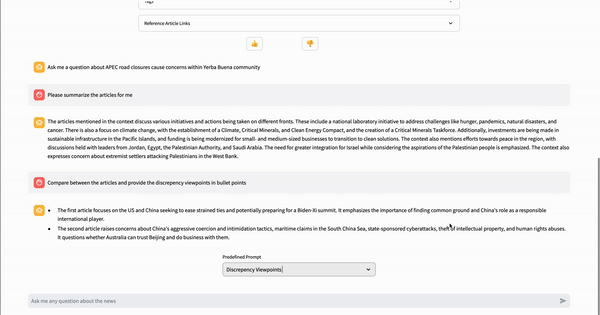
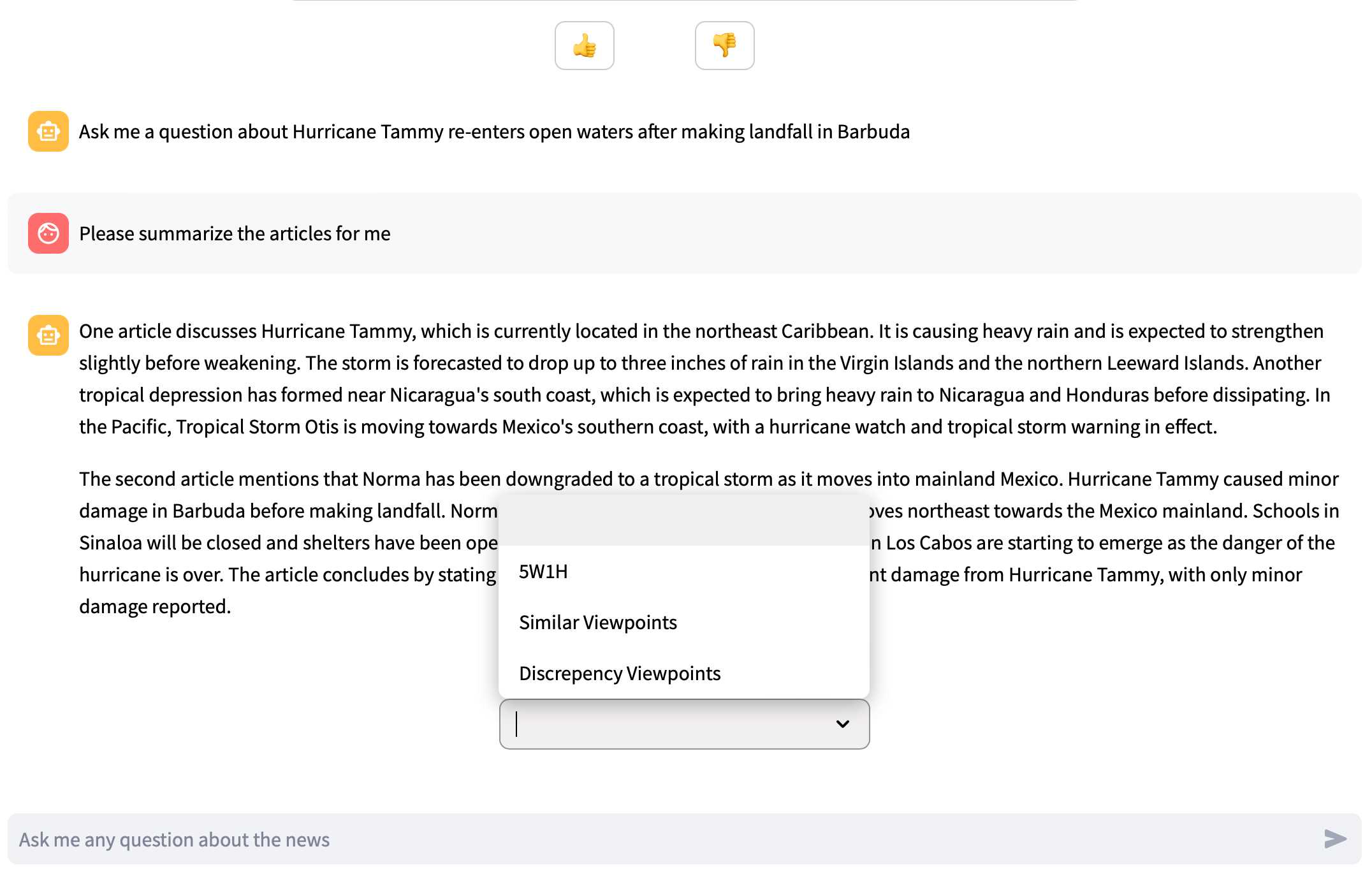
预定义提示
文章聊天页面预定义了三种不同的提示,允许用户从下拉菜单中选择问题而无需输入。这些提示是 5W1H、相似观点和差异观点。
prompt_content = {
"5W1H": 'Summarize the content details in the "5W1H" approach (Who, What, When, Where, Why, and How) in bullet points',
"Similar Viewpoints": "Compare between the articles and provide the similar viewpoints in bullet points",
"Discrepency Viewpoints": "Compare between the articles and provide the discrepency viewpoints in bullet points"
}
未来展望
非常感谢 LlamaIndex 和 Streamlit 慷慨地提供了巨大的平台,让更多人了解有机新闻摘要,并通过 NewsGPT 节省宝贵时间。如果您喜欢阅读本文并认同我们的理念,请不要犹豫,为文章点赞,并加入 Neotice(NewsGPT 的生产应用)来支持我们。我们对我们的使命充满信心,期待您与我们携手前行。谢谢!
您也可以在 LinkedIn 上联系我们: Kang-Chi Ho, Jian-An Wang
🎉 点击此处加入 Neotice 👉 Neotice