
Jerry Liu • 2023-11-10
多模态 RAG
(由 Haotian Zhang、Laurie Voss 和 Jerry Liu 共同撰写 @ LlamaIndex)
概述
在这篇博客中,我们很高兴地介绍一种全新的范式:多模态检索增强生成(RAG)。我们将在 LlamaIndex 中引入新的抽象,这些抽象现在可以实现以下功能
- 多模态 LLM 和嵌入
- 多模态索引和检索(与向量数据库集成)
多模态 RAG
OpenAI 开发者日最令人兴奋的公告之一是 GPT-4V API 的发布。GPT-4V 是一种 多模态 模型,可以同时输入文本和图像,并输出文本响应。它是近期多模态模型系列进展中的最新模型,包括 LLaVa 和 Fuyu-8B。
这将 LLM 的能力扩展到了令人兴奋的新方向。在过去一年里,围绕文本输入/文本输出范式涌现了完整的应用堆栈。其中最著名的例子之一是检索增强生成(RAG)—— 将 LLM 与外部文本语料库结合,以便对模型未训练过的数据进行推理。RAG 对最终用户最重大的影响之一在于它极大地加快了在非结构化文本数据上获得洞察的时间。通过处理任意文档(PDF、网页),将其加载到存储中,然后馈送到 LLM 的上下文窗口中,您可以从中提取出任何您想要的洞察。
GPT-4V API 的引入使我们能够将 RAG 概念扩展到混合图像/文本领域,并从更大规模的数据(包括图像)中释放价值。
考虑一下标准 RAG 流水线中的所有步骤,以及如何将其扩展到多模态设置。
- 输入:输入可以是文本或图像。
- 检索:检索到的上下文可以是文本或图像。
- 合成:答案可以根据文本和图像进行合成。
- 响应:返回的结果可以是文本和/或图像。
这也只是整个领域的一小部分。您可以进行链式/顺序调用,在图像和文本推理之间交替进行,例如检索增强图像字幕生成或多模态代理循环。
LlamaIndex 中的抽象
我们很高兴推出 LlamaIndex 中的新抽象,这些抽象有助于实现多模态 RAG。对于每个抽象,我们都明确说明了我们已经完成了什么以及未来会实现什么。
多模态 LLM
我们通过 OpenAIMultiModal 类直接支持 GPT-4V,并通过 ReplicateMultiModal 类支持开源多模态模型(目前处于 Beta 阶段,名称可能会更改)。我们的 SimpleDirectoryReader 长期以来一直能够摄取音频、图像和视频,但现在您可以直接将它们传递给 GPT-4V 并提问,如下所示
from llama_index.multi_modal_llms import OpenAIMultiModal
from llama_index import SimpleDirectoryReader
image_documents = SimpleDirectoryReader(local_directory).load_data()
openai_mm_llm = OpenAIMultiModal(
model="gpt-4-vision-preview", api_key=OPENAI_API_TOKEN, max_new_tokens=300
)
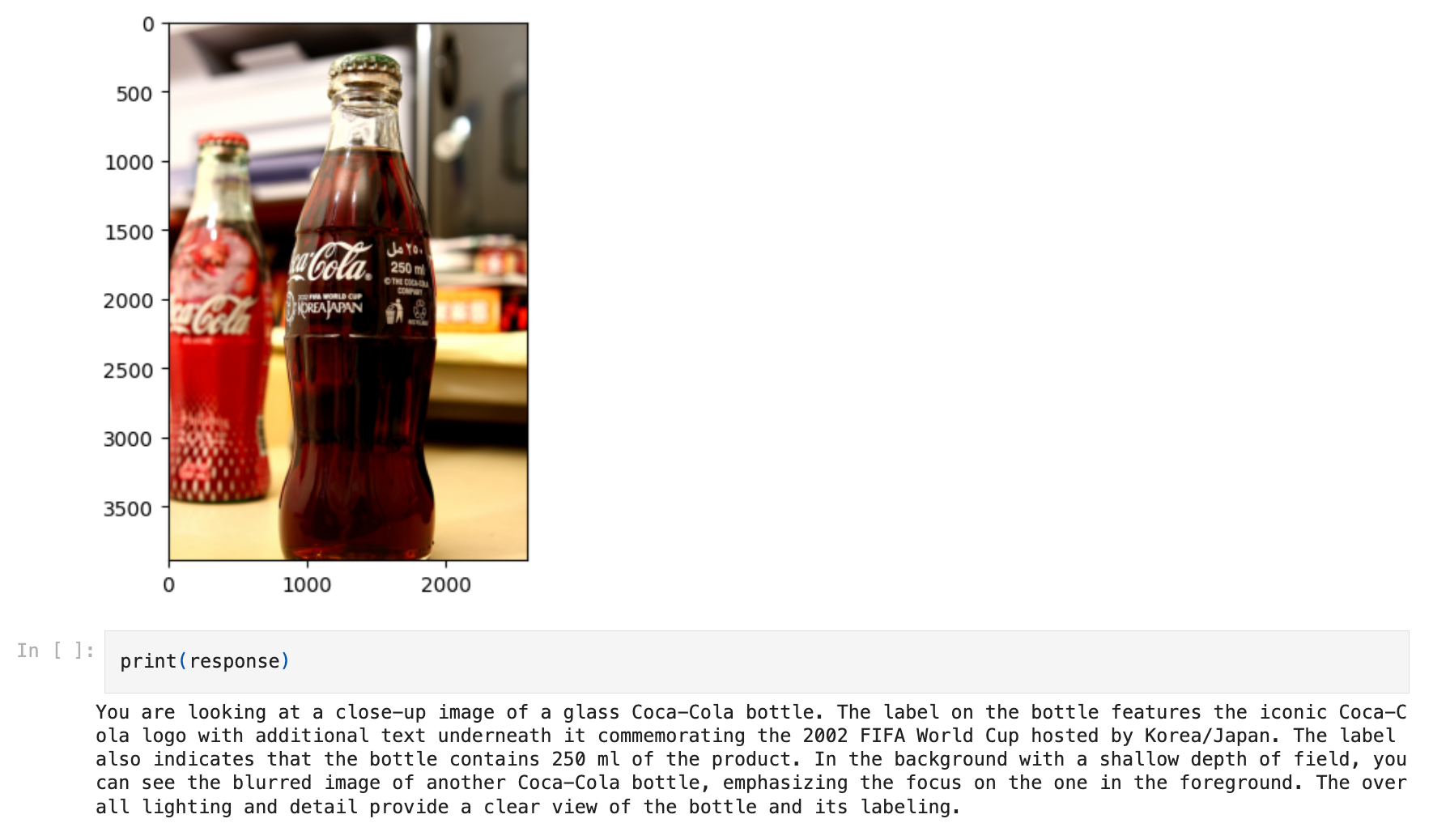
response = openai_mm_llm.complete(
prompt="what is in the image?", image_documents=image_documents
) 这是一个新的基础模型抽象。与我们默认的具有标准补全/聊天端点的 LLM 类不同,多模态模型 (MultiModalLLM) 可以同时接收图像和文本作为输入。
这也统一了 GPT-4V 和开源模型之间的接口。
资源
我们已经初步实现了对 GPT-4V 和托管在 Replicate 上的视觉模型的支持。我们还有一个关于多模态模型的文档页面
未来展望
- 更多多模态 LLM 集成
- 聊天端点
- 流式传输
多模态嵌入
我们引入了一个新的 MultiModalEmbedding 基类,它可以嵌入文本和图像。它包含我们现有嵌入模型(BaseEmbedding 的子类)的所有方法,并且还公开了 get_image_embedding 方法。
我们的主要实现是使用 CLIP 模型构建的 ClipEmbedding。请参阅下方指南了解如何使用它。
未来展望
- 更多多模态嵌入集成
多模态索引和检索
我们创建了一个新索引,即 MultiModalVectorIndex,它可以将文本和图像索引到底层存储系统——特别是向量数据库和文档存储。
与我们现有(最受欢迎的)索引 VectorStoreIndex 不同,这个新索引可以存储文本和图像文档。文本索引不变——使用文本嵌入模型嵌入并存储在向量数据库中。图像索引涉及一个单独的过程
- 使用 CLIP 嵌入图像
- 将图像节点表示为 base64 编码或路径,并将其及其嵌入一起存储在向量数据库中(与文本分开的集合)。
我们将图像和文本分开存储,因为我们可能希望对文本使用仅文本的嵌入模型,而不是 CLIP 嵌入(例如 ada 或 sbert)。
在检索时,我们执行以下操作
- 通过对文本嵌入进行向量搜索来检索文本
- 通过对图像嵌入进行向量搜索来检索图像
文本和图像都作为节点返回到结果列表中。然后我们可以根据这些结果进行合成。
未来展望
- 更原生地在向量存储中存储图像的方式(超越 base64 编码)
- 更灵活的多模态检索抽象(例如,将图像检索与任何文本检索方法相结合)
- 多模态响应合成抽象。目前处理长文本上下文的方法是进行“创建和完善”或“树状摘要”。尚不清楚跨多个图像和文本的通用响应合成是什么样的。
Notebook 演练
让我们来看一个 notebook 示例。这里我们介绍了一个用例,即给定特斯拉网站/车辆的截图、SEC 文件和维基百科页面来查询特斯拉。
我们将文档加载为文本文档和图像的混合形式
documents = SimpleDirectoryReader("./mixed_wiki/").load_data()然后我们在 Qdrant 中定义两个独立的向量数据库集合:一个用于文本文档的集合和一个用于图像的集合。然后我们定义一个 MultiModalVectorStoreIndex。
# Create a local Qdrant vector store
client = qdrant_client.QdrantClient(path="qdrant_mm_db")
text_store = QdrantVectorStore(
client=client, collection_name="text_collection"
)
image_store = QdrantVectorStore(
client=client, collection_name="image_collection"
)
storage_context = StorageContext.from_defaults(vector_store=text_store)
# Create the MultiModal index
index = MultiModalVectorStoreIndex.from_documents(
documents, storage_context=storage_context, image_vector_store=image_store
)然后我们可以对我们的多模态语料库进行提问。
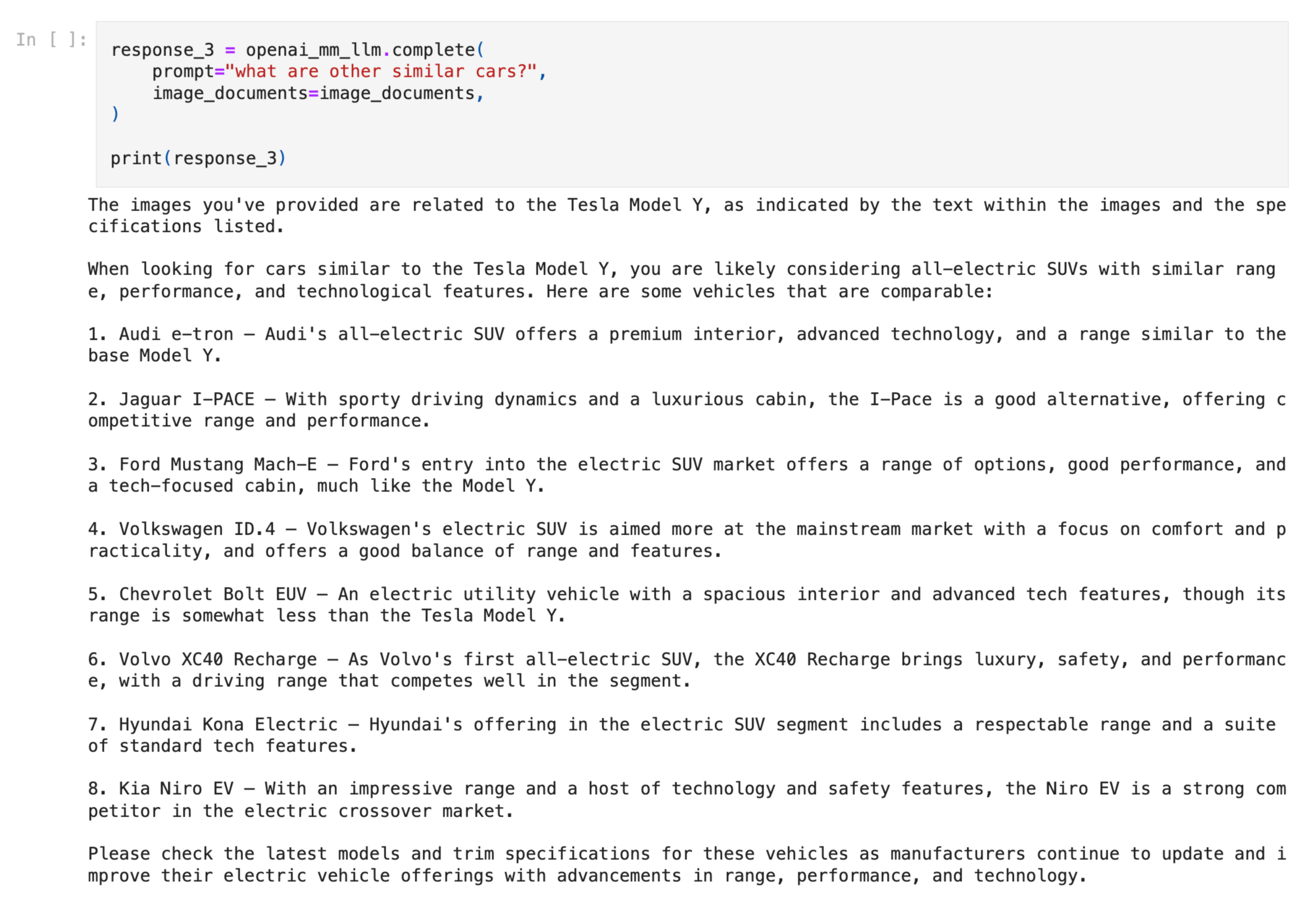
示例 1:检索增强字幕生成
这里我们将初始图像字幕复制/粘贴作为输入,以获得检索增强的输出
retriever_engine = index.as_retriever(
similarity_top_k=3, image_similarity_top_k=3
)
# retrieve more information from the GPT4V response
retrieval_results = retriever_engine.retrieve(query_str)检索到的结果包含图像和文本

我们可以将其输入给 GPT-4V,询问后续问题或合成连贯的响应
示例 2:多模态 RAG 查询
这里我们提出一个问题,并从整个多模态 RAG 流水线中获得响应。SimpleMultiModalQueryEngine 首先检索相关的图像/文本集合,然后将输入馈送给视觉模型以合成响应。
from llama_index.query_engine import SimpleMultiModalQueryEngine
query_engine = index.as_query_engine(
multi_modal_llm=openai_mm_llm,
text_qa_template=qa_tmpl
)
query_str = "Tell me more about the Porsche"
response = query_engine.query(query_str)生成的结果 + 来源如下所示
相关文章

2025-04-23


