
Jerry Liu • 2023-11-21
介绍 RAGs:基于您的数据的个性化 ChatGPT 体验
今天我们推出 RAGs,一个 Streamlit 应用,它允许您创建和定制自己的 RAG 管道,然后在您自己的数据上使用它——所有操作都通过自然语言完成!这意味着您现在无需编写代码即可设置“基于您数据的 ChatGPT”。
通过三个简单步骤设置和查询 RAG 管道
- 轻松描述任务:只需描述您的任务(如“加载此网页”)并定义 RAG 系统的参数(如检索一定数量的文档)。
- 可配置设置:深入配置视图,查看和修改自动生成的参数,如 top-k 检索、摘要选项等。
- 交互式 RAG 代理:设置完成后,您可以与 RAG 代理进行交互,提问并根据您的数据获取回答。
该应用专为技术水平较低和技术用户设计:如果您的技术水平较低,仍然需要克隆仓库并使用 pip 安装它,但无需担心内部运行的细节。另一方面,如果您是技术用户,则可以检查和自定义特定的参数设置(例如 top-k、数据)。
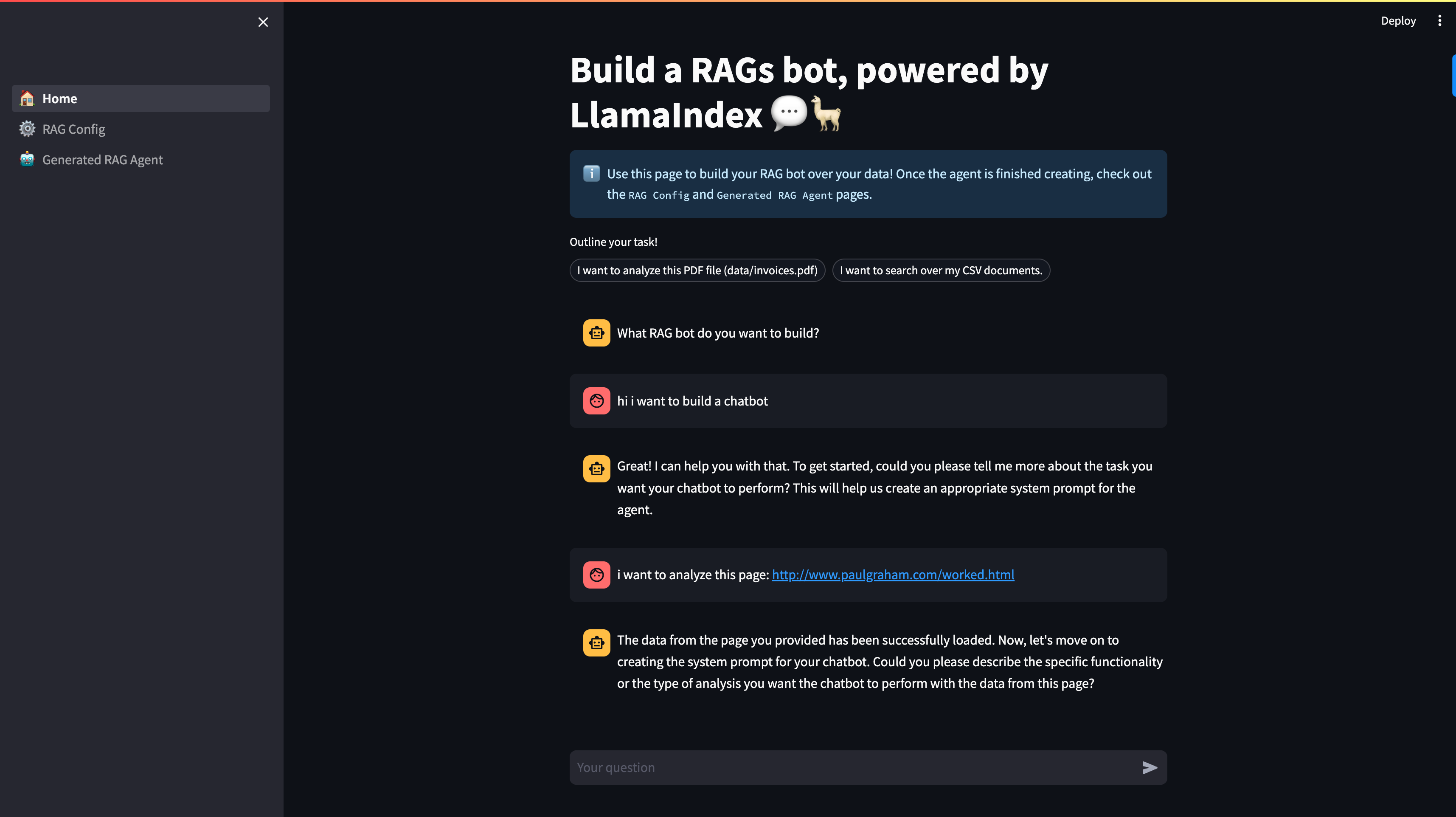
详细概览
该应用包含以下几个部分,对应于上面列出的步骤。
[1] 🏠 主页
在此部分,您可以通过指示“构建器代理”来构建 RAG 管道。通常,设置 RAG 管道需要以下组件
- 描述数据集:目前我们支持 单个本地文件 或 网页。我们对此持开放建议!
- 定义任务:您在此处的描述将初始化为支持 RAG 管道的 LLM 的“系统提示词”。
- 设置 RAG 参数:配置典型的 RAG 设置参数,如 top-k 检索、块大小和摘要选项。参数完整列表见下文。
[2] ⚙️ RAG 配置:定制您的体验
设置基本信息后,您将进入 RAG 配置部分。此应用部分提供了一个直观的用户界面,您可以在其中
- 查看生成的参数:构建器代理会根据您的初始设置建议参数。
- 编辑和自定义:您可以完全自由地调整这些设置,确保 RAG 代理按照您的需要运行。
- 更新代理:您所做的任何更改都可以通过点击“更新代理”按钮即时应用。
这是当前的参数集
- 系统提示词
- 包含摘要:是否也添加摘要工具(而不仅仅是执行 top-k 检索)。
- Top-K
- 块大小
- 嵌入模型
- LLM
[3] 🤖 生成的 RAG 代理:与您的数据交互
RAGs 体验的最后一个部分是生成的 RAG 代理部分。您可以期待以下内容
- 交互式聊天机器人界面:就像 ChatGPT 一样,与您的 RAG 代理进行对话。
- 数据驱动的回答:代理利用 top-k 向量搜索和可选的摘要工具,根据底层数据回答您的查询。
- 无缝集成:代理动态选择正确的工具来满足您的查询,确保与您的数据集进行流畅智能的交互。
架构
我们将在后续文章中更详细地介绍架构。从高层来看
- 我们有一个配备了构建器工具的构建器代理——这些工具是构建 RAG 管道所必需的。
- 构建器代理将使用这些工具来设置配置状态。在初始对话流程结束时,这些参数随后用于初始化 RAG 代理。
让我们看一个例子!
安装与设置
启动和运行 RAGs 非常简单
- 克隆 RAGs 项目并导航到
rags项目文件夹:https://github.com/run-llama/rags - 安装所需的包
pip install -r requirements.txt3. 启动应用
streamlit run 1_🏠_Home.py构建 RAG 代理
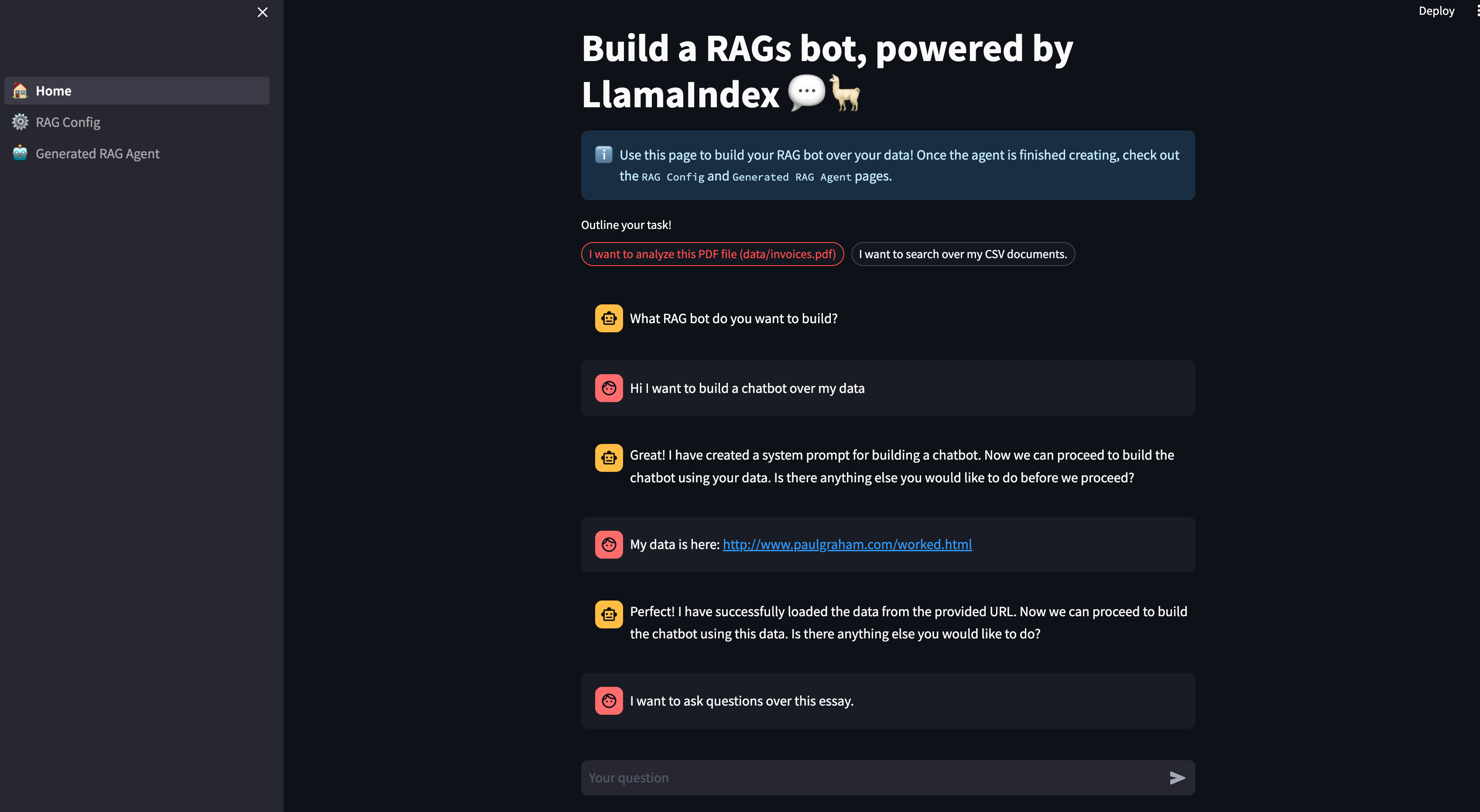
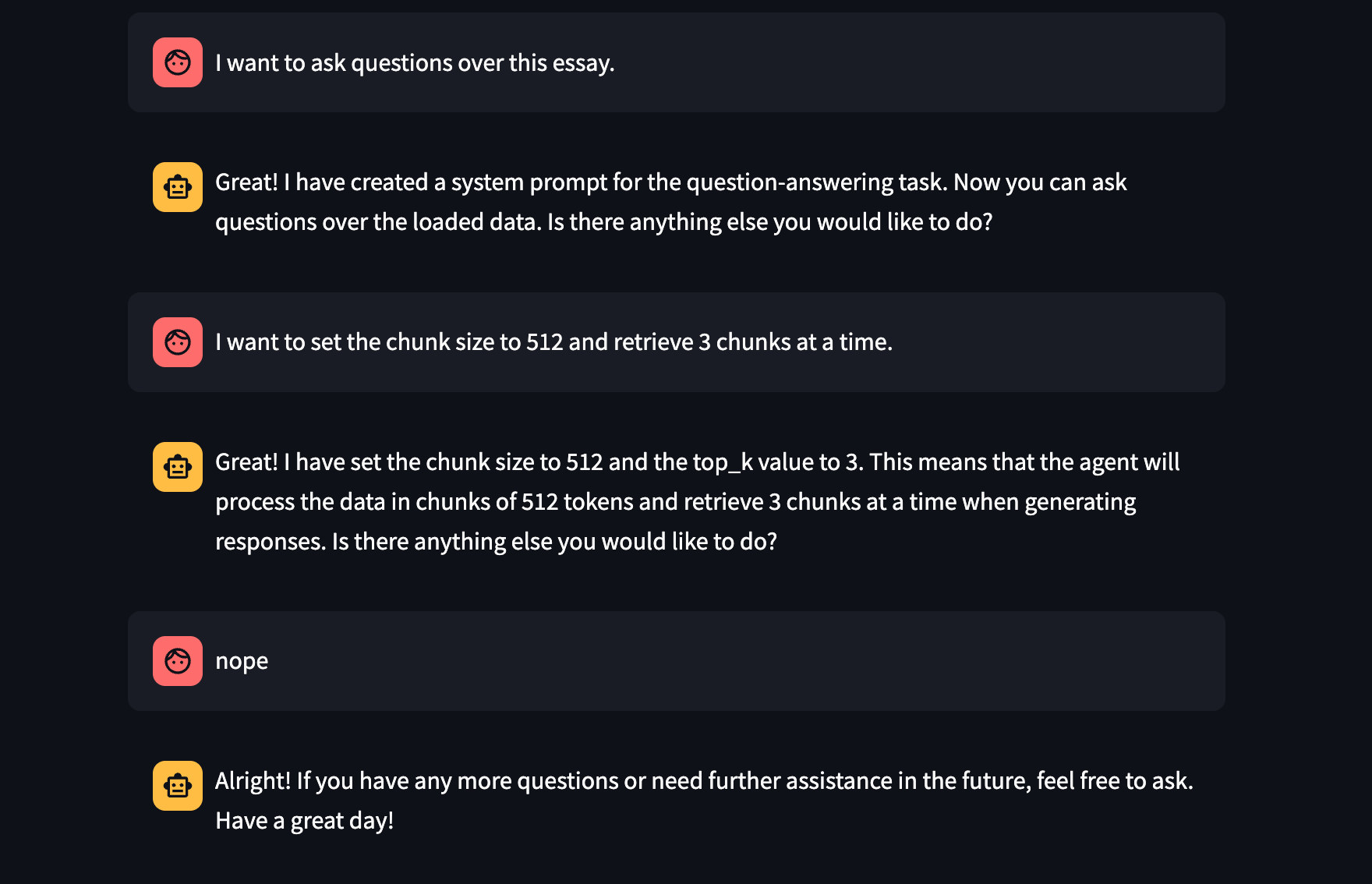
在下面的图中,我们展示了一系列“构建” RAG 管道的命令。
- 假设您想构建一个聊天机器人
- 定义数据集(这里是一个网页,也可以是本地文件)
- 定义任务
- 定义参数(块大小 512,top-k = 3)
查看配置
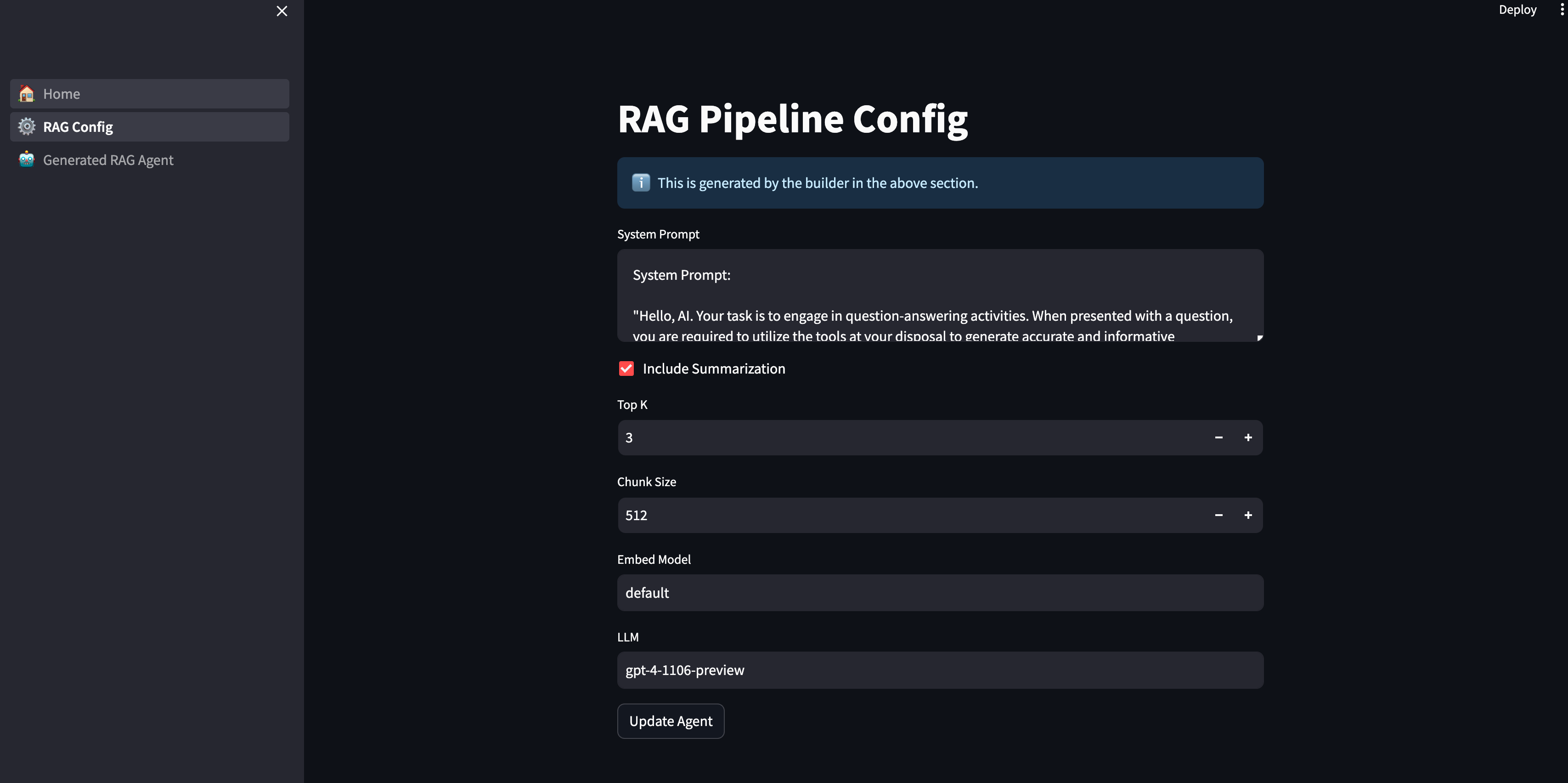
我们可以在下面的页面中看到生成的配置,并根据需要查看/编辑它们!
例如,我们可以将 include_summarization 设置为 True。
测试一下
现在我们可以提问了!我们可以问具体的问题,也可以问概括性的问题。
这使用向量搜索和摘要工具来回答所需的问题。


结论
总的来说,RAGs 是迈向一个由自然语言构建和驱动的 LLM 应用世界的初步尝试。请告诉我们您的想法和反馈!
资源
RAGs 仓库:https://github.com/run-llama/rags
贡献和支持
我们致力于改进和扩展 RAGs。如果您遇到任何问题或有建议,请随时提交 Github issue 或加入我们的 Discord 社区。



