
Jerry Liu • 2024-01-08
介绍查询管道
今天,我们正式推出 查询管道 (Query Pipelines),这是一个 LlamaIndex 中的全新声明式 API,让您能够针对不同用例 (RAG、结构化数据提取等) 简洁地协调处理您数据上的简单到高级查询工作流程。
这背后的核心是我们的QueryPipeline 抽象。它可以接受许多 LlamaIndex 模块(LLM、提示、查询引擎、检索器,以及它自身)。它可以在这些模块上创建一个计算图(例如顺序链或 DAG)。它支持回调,并与我们的 可观测性合作伙伴 进行原生集成。
最终目标是让您更容易地在您的数据上构建 LLM 工作流程。请查看我们全面的 介绍指南,以及我们的 文档页面,了解更多详细信息。
背景
过去一年中,AI 工程师开发了定制的复杂协调流程,结合 LLM 以解决各种不同的用例。随着时间的推移,出现了一些常见模式。在顶层,出现了查询用户数据的范式——这包括狭义上的 RAG 用于查询非结构化数据,以及 text-to-SQL 用于查询结构化数据。其他范式围绕结构化数据提取(例如提示 LLM 输出 JSON 并解析)、提示链(例如思维链 Chain-of-Thought)以及能够与外部服务交互的智能体(结合提示链
RAG 中有很多查询协调工作。 即使在 RAG 内部,构建一个针对性能优化的先进 RAG 管道也需要大量工作。从用户查询开始,我们可能需要进行查询理解/转换(重写、路由)。我们可能还需要运行多阶段检索算法——例如 top-k 查找 + 重排序。我们还可能需要使用提示 + LLM 以不同方式进行响应合成。这是一篇关于高级 RAG 组件 的优秀博客。
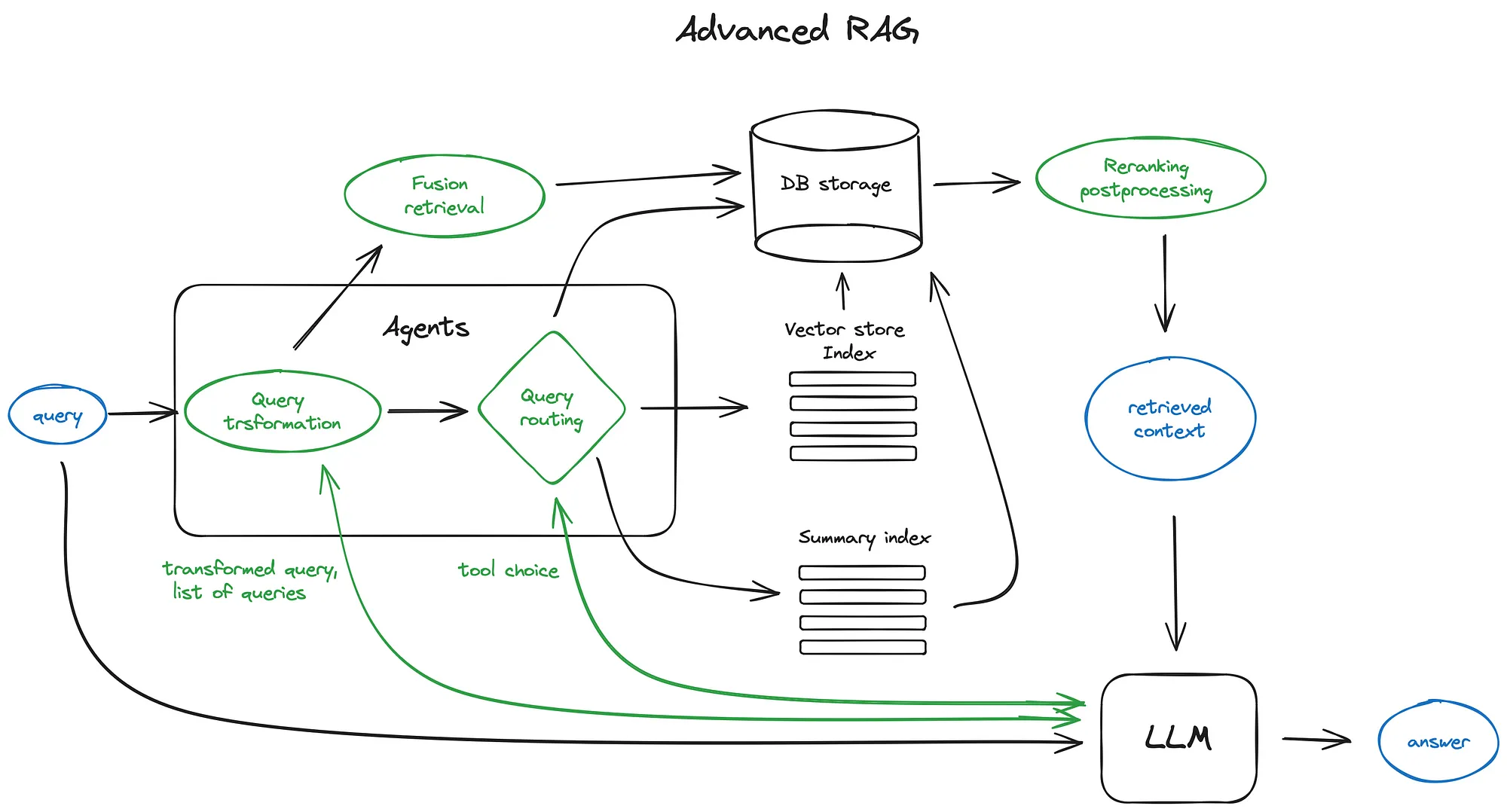
RAG 已变得更加模块化: 开发者不再拘泥于单一的检索/RAG 方法,而是被鼓励根据自己的用例选择最佳模块。这一观点在 高等人发表的 RAG 综述论文 中也得到了印证。
这带来了一些富有创造性的新模式,例如 DSP、重写-检索-阅读 (Rewrite-Retrieve-Read),或 多次交错进行检索+生成。
LlamaIndex 的先前状态
LlamaIndex 自身提供了数百份 RAG 指南和 16+ 个 Llama Pack 示例,让用户可以设置不同的 RAG 管道,并一直处于建立高级 RAG 模式的最前沿。
我们还暴露了低级模块,例如 LLM、提示 (prompts)、嵌入 (embeddings)、后处理器 (postprocessors) 以及核心组件(如 检索器 (retrievers) 和 查询引擎 (query engines))的轻松子类化,以便用户可以定义自己的工作流程。
但到目前为止,我们还没有一个明确的协调抽象层。用户需要通过阅读每个模块的 API 指南、将输出转换为正确的输入以及命令式地使用模块来摸索自己的工作流程。
查询管道
因此,我们的 QueryPipeline 提供了一个声明式查询协调抽象层。您可以使用它来组合任意复杂度的顺序链和有向无环图 (DAG)。
您已经可以使用 LlamaIndex 模块以命令式方式组合这些工作流程,但 QueryPipeline 让您可以用更少的代码行高效地完成。
它具有以下优势
- 用更少的代码/模板表达常见查询工作流程:停止编写输出/输入之间的转换逻辑,也不必费心弄清楚每个模块参数的确切类型!
- 更高的可读性:减少的模板代码带来更高的可读性。
- 端到端可观测性:在整个管道(即使是任意嵌套的 DAG)中获得回调集成,让您不必再纠结于我们的可观测性集成。
- [未来特性] 易于序列化:声明式接口使得核心组件更容易在其他系统上序列化/重新部署。
- [未来特性] 缓存:此接口还允许我们在底层构建缓存层,从而允许输入重用。
用法
QueryPipeline 允许您使用 LlamaIndex 模块构建基于 DAG 的查询工作流程。主要有两种使用方法
- 作为顺序链(最简单/最简洁)
- 作为完整 DAG(更具表达力)
请参阅我们的 使用模式指南,了解更多详细信息。
顺序链
一些简单的管道本质上是纯线性的——前一个模块的输出直接作为下一个模块的输入。
一些示例
- 提示 → LLM → 输出解析
- 检索器 → 响应合成器
这是最基本的示例,将提示与 LLM 串联起来。只需使用 chain 参数初始化 QueryPipeline 即可。
# try chaining basic prompts
prompt_str = "Please generate related movies to {movie_name}"
prompt_tmpl = PromptTemplate(prompt_str)
llm = OpenAI(model="gpt-3.5-turbo")
p = QueryPipeline(chain=[prompt_tmpl, llm], verbose=True)为高级 RAG 工作流程设置 DAG
通常,设置查询工作流程需要使用我们的低级函数来构建 DAG。
例如,要构建一个包含查询重写/检索/重排序/合成的“高级 RAG”,您可以执行如下操作。
from llama_index.postprocessor import CohereRerank
from llama_index.response_synthesizers import TreeSummarize
from llama_index import ServiceContext
# define modules
prompt_str = "Please generate a question about Paul Graham's life regarding the following topic {topic}"
prompt_tmpl = PromptTemplate(prompt_str)
llm = OpenAI(model="gpt-3.5-turbo")
retriever = index.as_retriever(similarity_top_k=3)
reranker = CohereRerank()
summarizer = TreeSummarize(
service_context=ServiceContext.from_defaults(llm=llm)
)
# define query pipeline
p = QueryPipeline(verbose=True)
p.add_modules(
{
"llm": llm,
"prompt_tmpl": prompt_tmpl,
"retriever": retriever,
"summarizer": summarizer,
"reranker": reranker,
}
)
# add edges
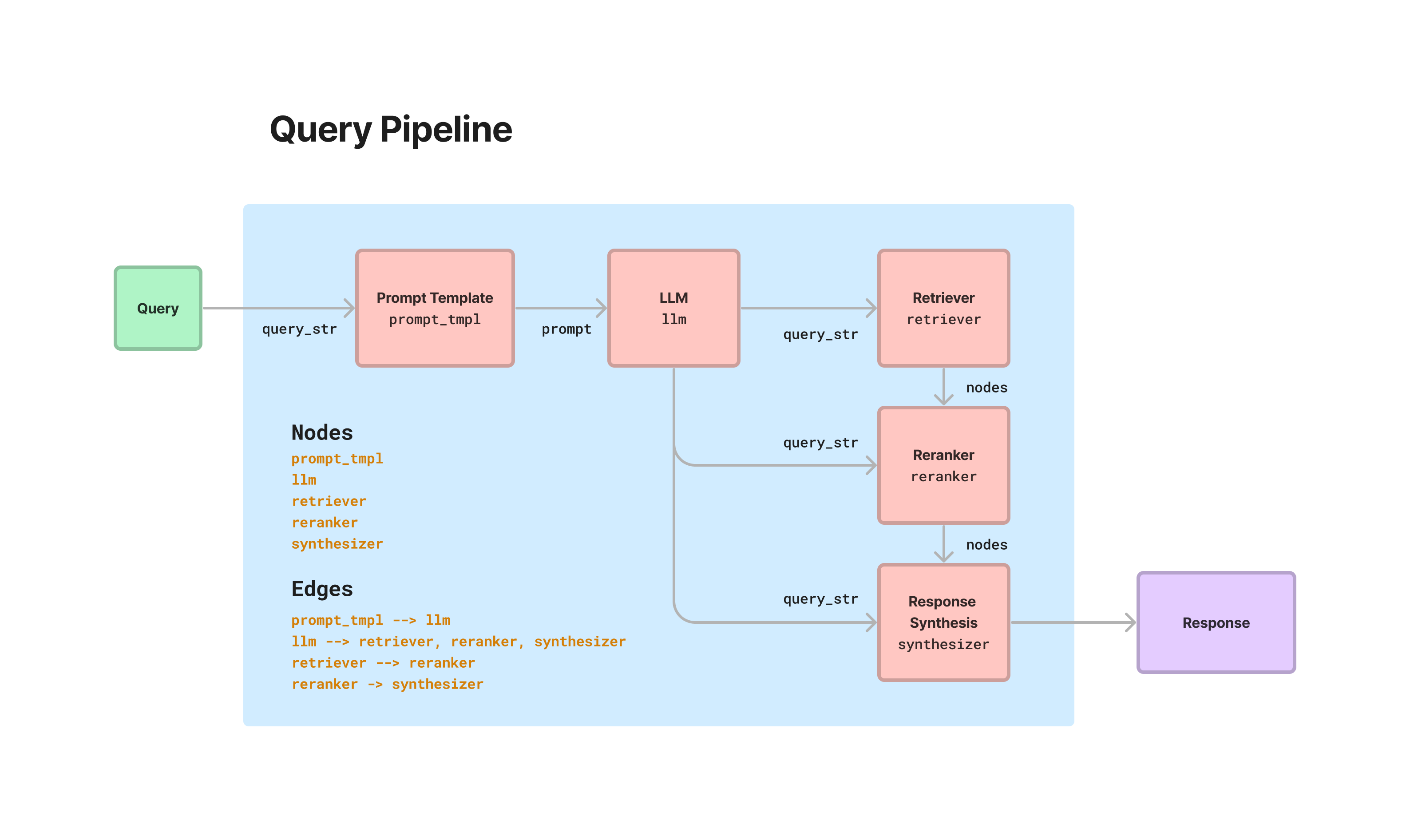
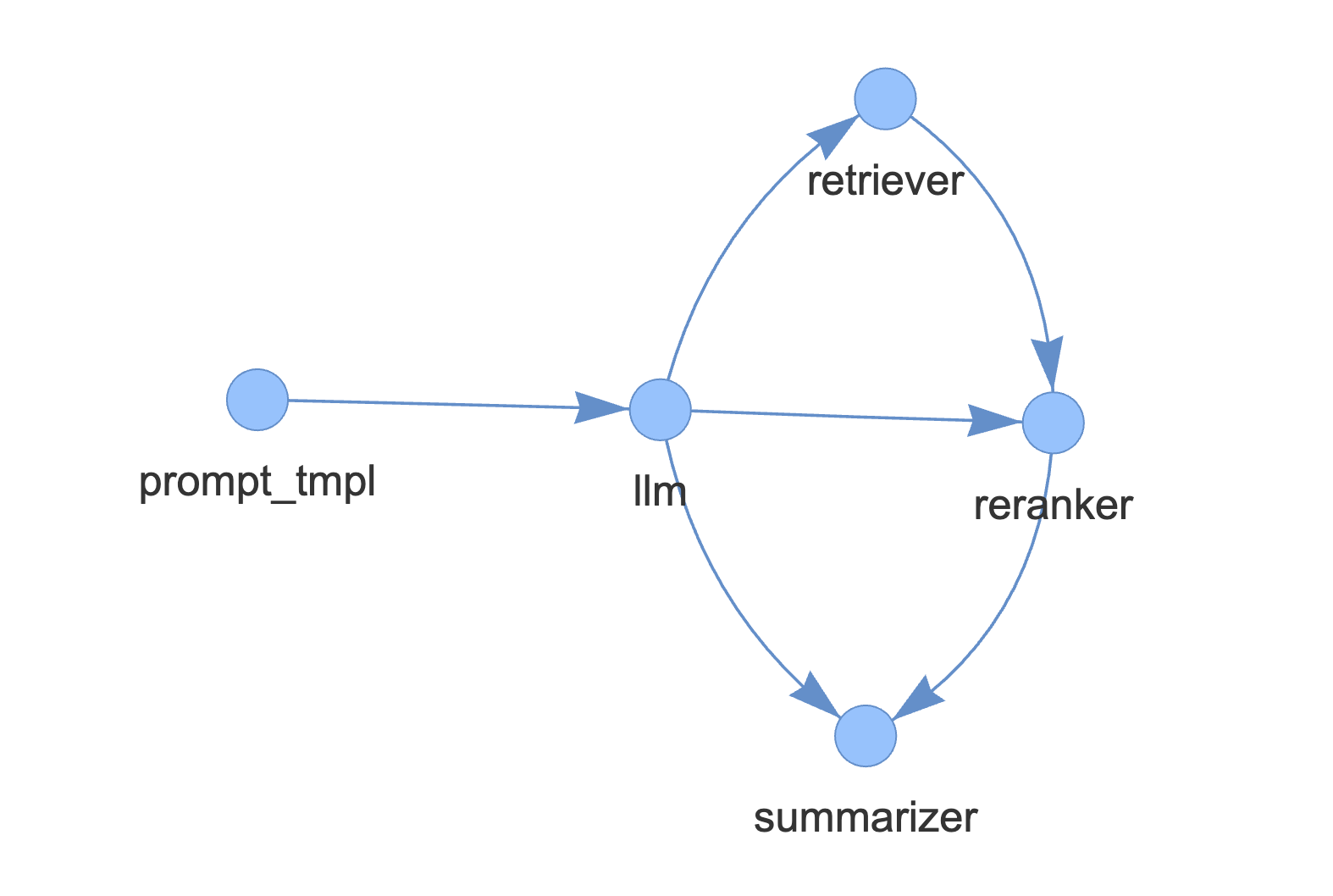
p.add_link("prompt_tmpl", "llm")
p.add_link("llm", "retriever")
p.add_link("retriever", "reranker", dest_key="nodes")
p.add_link("llm", "reranker", dest_key="query_str")
p.add_link("reranker", "summarizer", dest_key="nodes")
p.add_link("llm", "summarizer", dest_key="query_str")在此代码块中,我们 1) 添加模块,然后 2) 定义模块之间的关系。请注意,source_key 和 dest_key 是可选的,仅在前一个模块有多个输出或后一个模块有多个输入时才需要分别指定。
运行管道
如果管道有一个“根”节点和一个输出节点,请使用 run。以前面示例为例,
output = p.run(topic="YC")
# output type is Response
type(output)如果管道有多个根节点和/或多个输出节点,请使用 run_multi。
output_dict = p.run_multi({"llm": {"topic": "YC"}})
print(output_dict)定义自定义查询组件
子类化 CustomQueryComponent 非常容易,这样您就可以将其插入到 QueryPipeline 中。
查看 我们的演练,了解更多详细信息。
支持的模块
目前,QueryPipeline 中支持以下 LlamaIndex 模块。请记住,您可以定义自己的模块!
- LLM(包括补全和聊天)(
LLM) - 提示 (
PromptTemplate) - 查询引擎 (
BaseQueryEngine) - 查询转换 (
BaseQueryTransform) - 检索器 (
BaseRetriever) - 输出解析器 (
BaseOutputParser) - 后处理器/重排序器 (
BaseNodePostprocessor) - 响应合成器 (
BaseSynthesizer) - 其他
QueryPipeline对象 - 自定义组件 (
CustomQueryComponent)
查看 模块使用指南,了解更多详细信息。
演练示例
请务必查看我们的 查询管道介绍指南,了解完整详细信息。我们在其中提供了具体示例,涵盖了上述所有步骤!
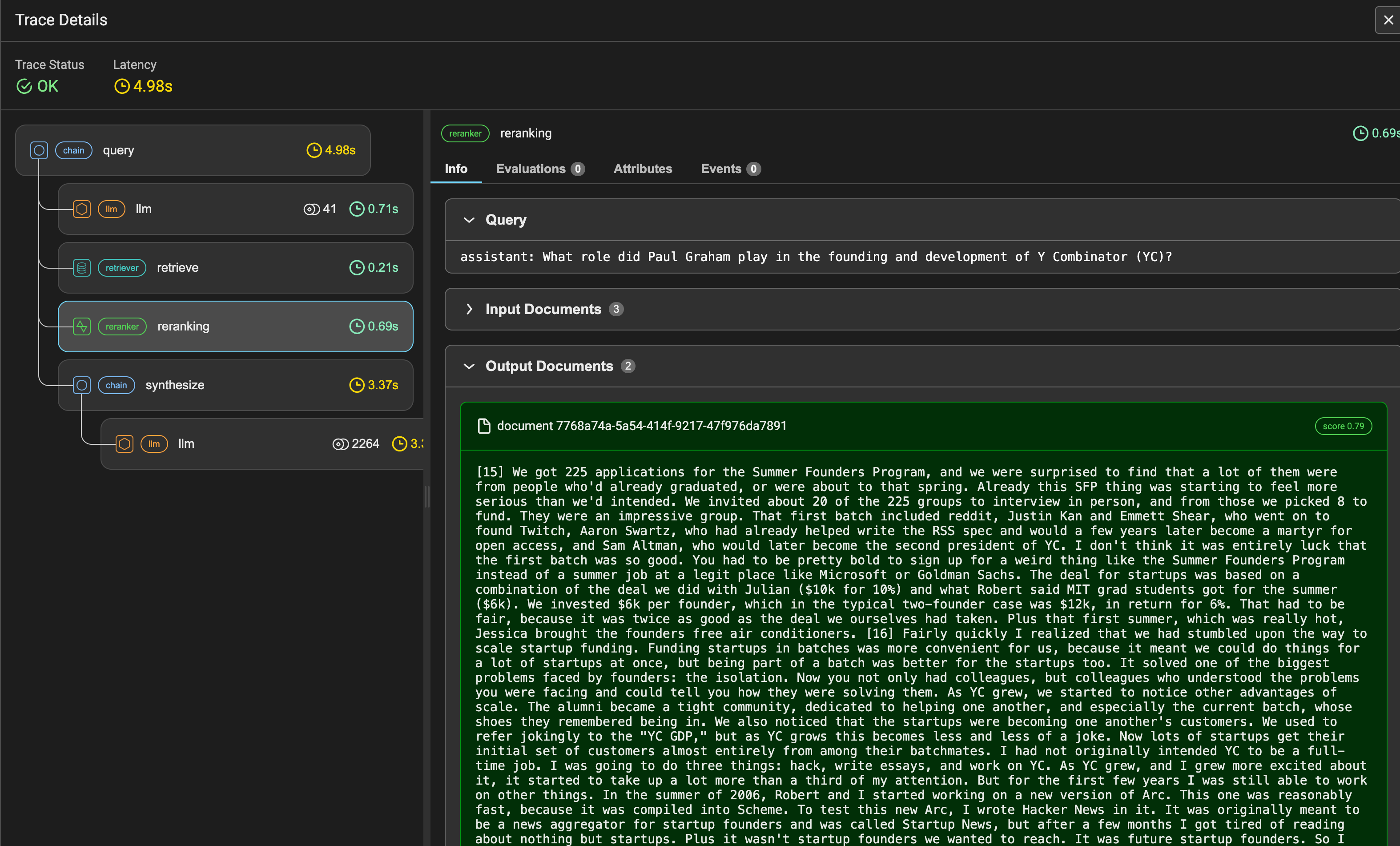
该 Notebook 指南还通过 Arize Phoenix 记录追踪。您可以在 Phoenix 控制面板中查看每个 QueryPipeline 的完整运行情况。我们在 QueryComponent 中的每个组件都提供完整的回调支持,让您能够轻松与任何可观测性提供商集成。
相关工作
使用声明式语法构建 LLM 驱动管道的想法并非新鲜事物。相关工作包括 Haystack 以及 LangChain 表达式语言 (LangChain Expression Language)。其他相关工作包括在无代码/低代码环境中设置的管道,例如 Langflow / Flowise。
我们此处的主要目标已在上面强调过:提供便捷的开发用户体验 (dev UX),以便在您的数据上定义常见查询工作流程。这里还有很多优化/指南需要完成!
常见问题
QueryPipeline 和 IngestionPipeline 有什么区别?
这个问题很好。目前,IngestionPipeline 在数据摄取阶段运行,而 QueryPipeline 在查询阶段运行。也就是说,我们未来可能会为两者开发一些共享的抽象层!
结论 + 资源
就这些了!如上所述,我们很快会添加更多资源和指南。在此期间,请查阅我们目前的指南



