
Ravi Theja • 2023-10-05
使用 LlamaIndex 评估 RAG 系统的理想分块大小
引言
检索增强生成(RAG)引入了一种创新方法,将搜索系统的强大检索能力与大型语言模型(LLM)融合。在实现 RAG 系统时,影响系统效率和性能的一个关键参数是 chunk_size(分块大小)。如何确定实现无缝检索的最佳分块大小?这就是 LlamaIndex 的 Response Evaluation(响应评估)派上用场的地方。在这篇博文中,我们将指导您如何使用 LlamaIndex 的 Response Evaluation 模块来确定最佳的 chunk size。如果您不熟悉 Response Evaluation 模块,建议在继续之前先查阅其文档。
为什么分块大小很重要
选择合适的 chunk_size 是一个关键决策,它可以通过多种方式影响 RAG 系统的效率和准确性
- 相关性和粒度:较小的
chunk_size(例如 128)会产生更细粒度的分块。然而,这种细粒度存在风险:关键信息可能不在检索到的靠前分块中,尤其当similarity_top_k设置限制为 2 时。相反,大小为 512 的分块更有可能包含靠前分块中的所有必要信息,确保查询的答案随时可用。为了解决这个问题,我们采用了忠实度(Faithfulness)和相关性(Relevancy)指标。这些指标分别基于查询和检索到的上下文,衡量响应中是否存在“幻觉”以及响应的“相关性”。 - 响应生成时间:随着
chunk_size的增加,输入到 LLM 中用于生成答案的信息量也随之增加。虽然这可以确保更全面的上下文,但也可能减慢系统速度。确保增加的信息深度不会影响系统的响应能力至关重要。
本质上,确定最佳的 chunk_size 是关于在捕获所有关键信息和不牺牲速度之间取得平衡。对各种大小进行彻底测试以找到适合特定用例和数据集的配置至关重要。
要实际评估如何选择正确的 chunk_size,您可以在这个 Google Colab Notebook 上访问并运行以下设置。
设置
在开始实验之前,我们需要确保所有必需的模块都已导入
import nest_asyncio
nest_asyncio.apply()
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext,
)
from llama_index.evaluation import (
DatasetGenerator,
FaithfulnessEvaluator,
RelevancyEvaluator
)
from llama_index.llms import OpenAI
import openai
import time
openai.api_key = 'OPENAI-API-KEY'下载数据
本次实验我们将使用 Uber 2021 年的 10K SEC 文件。
!mkdir -p 'data/10k/'
!wget 'https://raw.githubusercontent.com/jerryjliu/llama_index/main/docs/examples/data/10k/uber_2021.pdf' -O 'data/10k/uber_2021.pdf'加载数据
加载我们的文档。
documents = SimpleDirectoryReader("./data/10k/").load_data()问题生成
为了选择合适的 chunk_size,我们将计算不同 chunk_size 的平均响应时间、忠实度(Faithfulness)和相关性(Relevancy)等指标。DatasetGenerator 将帮助我们从文档中生成问题。
data_generator = DatasetGenerator.from_documents(documents)
eval_questions = data_generator.generate_questions_from_nodes()设置评估器
我们正在设置 GPT-4 模型,作为评估实验期间生成响应的核心。使用 service_context 初始化了两个评估器:FaithfulnessEvaluator(忠实度评估器)和 RelevancyEvaluator(相关性评估器)。
- 忠实度评估器(Faithfulness Evaluator) — 它用于衡量响应是否出现了“幻觉”,并衡量查询引擎的响应是否与任何源节点匹配。
- 相关性评估器(Relevancy Evaluator) — 它用于衡量查询是否确实得到了响应的回答,并衡量响应 + 源节点是否与查询匹配。
# We will use GPT-4 for evaluating the responses
gpt4 = OpenAI(temperature=0, model="gpt-4")
# Define service context for GPT-4 for evaluation
service_context_gpt4 = ServiceContext.from_defaults(llm=gpt4)
# Define Faithfulness and Relevancy Evaluators which are based on GPT-4
faithfulness_gpt4 = FaithfulnessEvaluator(service_context=service_context_gpt4)
relevancy_gpt4 = RelevancyEvaluator(service_context=service_context_gpt4)针对某个分块大小的响应评估
我们基于 3 个指标评估每个 chunk_size。
- 平均响应时间。
- 平均忠实度。
- 平均相关性。
这里有一个函数 evaluate_response_time_and_accuracy,它正好执行此操作,包含以下内容:
- 向量索引创建。
- 构建查询引擎。
- 指标计算。
# Define function to calculate average response time, average faithfulness and average relevancy metrics for given chunk size
# We use GPT-3.5-Turbo to generate response and GPT-4 to evaluate it.
def evaluate_response_time_and_accuracy(chunk_size, eval_questions):
"""
Evaluate the average response time, faithfulness, and relevancy of responses generated by GPT-3.5-turbo for a given chunk size.
Parameters:
chunk_size (int): The size of data chunks being processed.
Returns:
tuple: A tuple containing the average response time, faithfulness, and relevancy metrics.
"""
total_response_time = 0
total_faithfulness = 0
total_relevancy = 0
# create vector index
llm = OpenAI(model="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=llm, chunk_size=chunk_size)
vector_index = VectorStoreIndex.from_documents(
eval_documents, service_context=service_context
)
# build query engine
query_engine = vector_index.as_query_engine()
num_questions = len(eval_questions)
# Iterate over each question in eval_questions to compute metrics.
# While BatchEvalRunner can be used for faster evaluations (see: https://docs.llamaindex.org.cn/en/latest/examples/evaluation/batch_eval.html),
# we're using a loop here to specifically measure response time for different chunk sizes.
for question in eval_questions:
start_time = time.time()
response_vector = query_engine.query(question)
elapsed_time = time.time() - start_time
faithfulness_result = faithfulness_gpt4.evaluate_response(
response=response_vector
).passing
relevancy_result = relevancy_gpt4.evaluate_response(
query=question, response=response_vector
).passing
total_response_time += elapsed_time
total_faithfulness += faithfulness_result
total_relevancy += relevancy_result
average_response_time = total_response_time / num_questions
average_faithfulness = total_faithfulness / num_questions
average_relevancy = total_relevancy / num_questions
return average_response_time, average_faithfulness, average_relevancy测试不同的分块大小
我们将评估一系列分块大小,以确定哪个能提供最有希望的指标。
chunk_sizes = [128, 256, 512, 1024, 2048]
for chunk_size in chunk_sizes:
avg_response_time, avg_faithfulness, avg_relevancy = evaluate_response_time_and_accuracy(chunk_size, eval_questions)
print(f"Chunk size {chunk_size} - Average Response time: {avg_response_time:.2f}s, Average Faithfulness: {avg_faithfulness:.2f}, Average Relevancy: {avg_relevancy:.2f}")整合所有内容
我们将这些流程整合起来
import nest_asyncio
nest_asyncio.apply()
from llama_index import (
SimpleDirectoryReader,
VectorStoreIndex,
ServiceContext,
)
from llama_index.evaluation import (
DatasetGenerator,
FaithfulnessEvaluator,
RelevancyEvaluator
)
from llama_index.llms import OpenAI
import openai
import time
openai.api_key = 'OPENAI-API-KEY'
# Download Data
!mkdir -p 'data/10k/'
!wget 'https://raw.githubusercontent.com/jerryjliu/llama_index/main/docs/examples/data/10k/uber_2021.pdf' -O 'data/10k/uber_2021.pdf'
# Load Data
reader = SimpleDirectoryReader("./data/10k/")
documents = reader.load_data()
# To evaluate for each chunk size, we will first generate a set of 40 questions from first 20 pages.
eval_documents = documents[:20]
data_generator = DatasetGenerator.from_documents()
eval_questions = data_generator.generate_questions_from_nodes(num = 20)
# We will use GPT-4 for evaluating the responses
gpt4 = OpenAI(temperature=0, model="gpt-4")
# Define service context for GPT-4 for evaluation
service_context_gpt4 = ServiceContext.from_defaults(llm=gpt4)
# Define Faithfulness and Relevancy Evaluators which are based on GPT-4
faithfulness_gpt4 = FaithfulnessEvaluator(service_context=service_context_gpt4)
relevancy_gpt4 = RelevancyEvaluator(service_context=service_context_gpt4)
# Define function to calculate average response time, average faithfulness and average relevancy metrics for given chunk size
def evaluate_response_time_and_accuracy(chunk_size):
total_response_time = 0
total_faithfulness = 0
total_relevancy = 0
# create vector index
llm = OpenAI(model="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=llm, chunk_size=chunk_size)
vector_index = VectorStoreIndex.from_documents(
eval_documents, service_context=service_context
)
query_engine = vector_index.as_query_engine()
num_questions = len(eval_questions)
for question in eval_questions:
start_time = time.time()
response_vector = query_engine.query(question)
elapsed_time = time.time() - start_time
faithfulness_result = faithfulness_gpt4.evaluate_response(
response=response_vector
).passing
relevancy_result = relevancy_gpt4.evaluate_response(
query=question, response=response_vector
).passing
total_response_time += elapsed_time
total_faithfulness += faithfulness_result
total_relevancy += relevancy_result
average_response_time = total_response_time / num_questions
average_faithfulness = total_faithfulness / num_questions
average_relevancy = total_relevancy / num_questions
return average_response_time, average_faithfulness, average_relevancy
# Iterate over different chunk sizes to evaluate the metrics to help fix the chunk size.
for chunk_size in [128, 256, 512, 1024, 2048]
avg_time, avg_faithfulness, avg_relevancy = evaluate_response_time_and_accuracy(chunk_size)
print(f"Chunk size {chunk_size} - Average Response time: {avg_time:.2f}s, Average Faithfulness: {avg_faithfulness:.2f}, Average Relevancy: {avg_relevancy:.2f}")结果
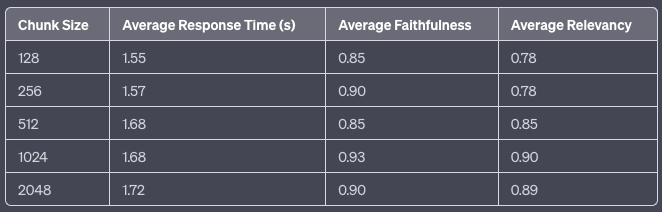
上表表明,随着分块大小的增加,平均响应时间略有上升。有趣的是,平均忠实度似乎在 chunk_size 为 1024 时达到顶峰,而平均相关性随着分块大小的增加持续改善,同样在 1024 时达到最高。这表明 1024 的分块大小可能在响应时间和响应质量(以忠实度和相关性衡量)之间达到最佳平衡。
结论
确定 RAG 系统的最佳分块大小既需要直觉,也需要经验证据。借助 LlamaIndex 的 Response Evaluation 模块,您可以尝试各种大小,并根据具体数据做出决策。构建 RAG 系统时,请务必记住 chunk_size 是一个关键参数。投入时间仔细评估和调整您的分块大小,以获得卓越的结果。



