
LlamaIndex • 2023-11-16
评估多模态检索增强生成
几天前,我们发布了一篇关于多模态 RAG(检索增强生成)的博客,以及我们最新(仍在测试阶段)的抽象,以帮助实现和简化构建多模态 RAG 系统。在本文中,我们将探讨如何合理评估多模态 RAG 系统这一重要话题。
一个自然的起点是回顾传统纯文本 RAG 中的评估方法,然后思考如何修改这些方法以适应多模态场景(例如,在纯文本 RAG 中我们使用 LLM,而在多模态 RAG 中我们需要一个大型多模态模型,简称 LMM)。这正是我们接下来要做的事情,您会看到,总体评估框架与纯文本 RAG 中相同,只需做一些增补和修改,使其更适用于多模态场景。
入门:多模态 RAG vs 纯文本 RAG

让我们看看多模态和纯文本 RAG 之间的主要区别。下面是两个表格,描述了构建 RAG 的考虑因素以及查询时管道,并对比了多模态和纯文本场景在这些方面的差异。


纯文本 RAG 的评估
对于纯文本 RAG,标准方法是分别评估两个阶段:检索和生成。
检索器评估:检索到的文档与用户查询相关吗?
一些更流行的检索评估指标包括召回率、命中率、平均倒数排名、平均精度和归一化折损累计增益。前两个指标(召回率和命中率)不考虑相关文档的位置(或排名),而其他所有指标都以各自的方式考虑。
生成器评估:响应是否充分使用了检索到的文档来回答用户查询?
在抽象式问答系统(如本文讨论的类型)中,衡量生成的响应会更加棘手,因为在书面语言中,充分回答一个查询的方式并非只有一种——而是有很多种!
因此,在这种情况下,我们的衡量依赖于主观判断,这可以由人类来完成,但这成本高昂且难以扩展。另一种方法是使用 LLM 评判器来衡量诸如相关性和忠实度之类的指标。
- 相关性:考虑文本上下文,评估生成的响应与查询的匹配程度。
- 忠实度:评估生成的响应与检索到的文本上下文的匹配程度。
对于这两者,检索到的上下文、查询和生成的响应都会传递给 LLM 评判器。(空间中一些研究人员将这种使用 LLM 评判响应的模式称为 LLM 即评判器(Zheng 等人,2023)。)
目前,llama-index (v0.9.2) 库支持命中率和平均倒数排名用于检索评估,以及相关性、忠实度等指标用于生成器评估。(查看我们的文档中的评估指南!)
多模态 RAG 的评估
对于多模态情况,评估仍然可以(并且应该)针对检索和生成的不同阶段进行。
区分文本和图像模态的检索评估
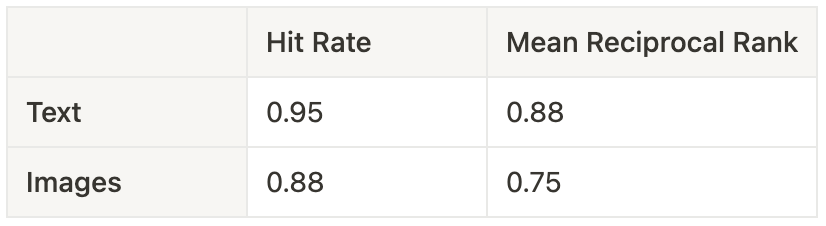
既然检索到的文档可以有两种形式,那么最明智的做法似乎是分别计算图像和文本的常用检索评估指标。这样,您就可以更清楚地了解多模态检索器哪个方面表现良好,哪些方面表现不佳。然后可以应用所需的加权方案,为每个指标建立一个汇总的检索分数。
命中率 平均倒数排名 文本 0.95 0.88 图像 0.88 0.75
使用多模态 LLM 进行生成器评估(LMM 即评判器)
多模态模型(即 LMMs),如 OpenAI 的 GPT-4V 或像 LLaVA 这样的开源替代品,能够接收输入和图像上下文来生成对用户查询的答案。与纯文本 RAG 一样,我们也关注这些生成答案的“相关性”和“忠实度”。但为了在多模态情况下计算这些指标,我们需要一个也能接收上下文图像和文本数据的评判模型。因此,在多模态情况下,我们采用 LMM 即评判器模式来计算相关性、忠实度以及其他相关指标!
- 相关性(多模态):考虑文本和视觉上下文,评估生成的响应与查询的匹配程度。
- 忠实度(多模态):评估生成的响应与检索到的文本和视觉上下文的匹配程度。
如果您想测试这些,那么您很幸运,因为我们最近发布了测试版的多模态评估器抽象!请参阅下面的代码片段,了解如何使用这些抽象对给定查询的生成响应执行各自的评估。
from llama_index.evaluation.multi_modal import (
MultiModalRelevancyEvaluator,
MultiModalFaithfulnessEvaluator
)
from llama_index.multi_modal_llm import OpenAIMultiModal
relevancy_judge = MultiModalRelevancyEvaluator(
multi_modal_llm=OpenAIMultiModal(
model="gpt-4-vision-preview",
max_new_tokens=300,
)
)
faithfulness_judge = MultiModalRelevancyEvaluator(
multi_modal_llm=OpenAIMultiModal(
model="gpt-4-vision-preview",
max_new_tokens=300,
)
)
# Generated response to a query and its retrieved context information
query = ...
response = ...
contexts = ... # retrieved text contexts
image_paths = ... # retrieved image contexts
# Evaluations
relevancy_eval = relevancy_judge.evaluate(
query=query,
response=response,
contexts=contexts,
image_paths=image_paths
)
faithfulness_eval = faithfulness_judge.evaluate(
query=query,
response=response,
contexts=contexts,
image_paths=image_paths
)一些重要说明
首先,值得一提的是,使用 LLM 或 LMM 评判生成的响应有其缺点。这些评判器本身是生成模型,可能会出现幻觉和其他不一致。尽管研究表明强大的 LLM 可以在较高程度上与人类判断保持一致(Zheng 等人,2023),但在生产系统中使用它们应以更高的标准处理。截至撰写本文时,还没有研究表明强大的 LMM 也能很好地与人类判断保持一致。
其次,对生成器的评估主要涉及对其知识和推理能力的评估。评估 LLM 和 LMM 还有其他重要维度,包括对齐和安全性——更多信息请参阅评估 LMMs:一份综合调查。
开始评估吧
在本文中,我们介绍了如何对多模态 RAG 系统进行评估。我们认为,按模态区分检索评估以提高可见性,以及采用 LMM 即评判器的方法,是纯文本 RAG 评估框架的一个合理扩展。我们鼓励您查看我们的实用笔记本指南和文档,了解如何不仅构建多模态 RAG,还能充分评估它们!



