
Jerry Liu • 2023-05-28
结合 Text-to-SQL 与语义搜索实现检索增强生成
摘要
在本文中,我们展示了 LlamaIndex 中的一个强大的新查询引擎(SQLAutoVectorQueryEngine),它可以利用 SQL 数据库和向量存储来完成针对结构化数据和非结构化数据组合的复杂自然语言查询。这个查询引擎可以利用 SQL 对结构化数据的表达能力,并将其与来自向量数据库的非结构化上下文结合。我们在几个示例中展示了这个查询引擎,并表明它可以处理同时使用结构化/非结构化数据或仅使用其中一种数据的查询。
在此查看完整指南:https://gpt-index.readthedocs.io/en/latest/examples/query_engine/SQLAutoVectorQueryEngine.html。
背景
企业中的数据湖通常包含结构化数据和非结构化数据。结构化数据通常以表格格式存储在 SQL 数据库中,组织成具有预定义模式和实体间关系的表。另一方面,数据湖中的非结构化数据缺乏预定义的结构,无法整齐地放入传统数据库。这类数据包括文本文档,也包括音频记录、视频等其他多模态格式。
大型语言模型 (LLM) 能够从结构化和非结构化数据中提取见解。目前已经出现了一些初步的工具和技术栈来处理这两种类型的数据
- Text-to-SQL(结构化数据):给定一组表格模式,我们将自然语言转换为 SQL 语句,然后针对数据库执行。
- 语义搜索与向量数据库(非结构化数据):将非结构化文档及其向量嵌入存储在向量数据库中(例如 Pinecone、Chroma、Milvus、Weaviate 等)。在查询时,通过嵌入相似度检索相关文档,然后放入 LLM 输入提示中以合成响应。
每种技术栈都解决了特定的用例。
基于结构化数据的 Text-to-SQL
在结构化场景中,SQL 是处理表格数据的极其富有表现力的语言——在分析场景中,您可以获得聚合、联接多个表中的信息、按时间戳排序等等。使用 LLM 将自然语言转换为 SQL 可以被视为程序合成的“作弊码”——只需让 LLM 编译成正确的 SQL 查询,然后让数据库上的 SQL 引擎处理其余部分!
用例:Text-to-SQL 查询非常适合可以通过执行 SQL 语句找到答案的分析用例。它们不适合需要比结构化表中更详细信息的用例,或者需要更复杂的方法来确定与查询的相关性(超出像 WHERE 条件这样的简单构造)的用例。
适用于 Text-to-SQL 的示例查询
- “北美城市的平均人口是多少?”
- “每个大陆最大的城市和人口是多少?”
基于非结构化数据的语义搜索
在非结构化场景中,检索增强生成系统的行为是先执行检索,然后合成。在检索过程中,我们首先通过嵌入相似度查找与查询最相关的文档。一些向量存储支持处理额外的元数据过滤器进行检索。我们可以选择手动指定所需的过滤器集合,或者让 LLM“推断”查询字符串和元数据过滤器应是什么(请参阅 LlamaIndex 中的自动检索器模块或 LangChain 的自查询模块)。
用例:检索增强生成非常适合那些答案可以在非结构化文本数据的某些部分中获得的查询。大多数现有的向量存储(例如 Pinecone、Chroma)不提供类似 SQL 的接口;因此,它们不太适合涉及聚合、联接、求和等的查询。
适用于检索增强生成的示例查询
- “告诉我关于柏林的历史博物馆”
- “Jordan 代表 Gatsby 向 Nick 提出了什么要求?”
结合这两个系统
对于某些查询,我们可能希望利用结构化表以及向量数据库/文档存储中的知识,以便为查询提供最佳答案。理想情况下,这可以让我们两全其美:对结构化数据的分析能力,以及对非结构化数据的语义理解。
这里有一个示例用例
- 您可以访问存储在向量数据库中的关于不同城市的文章集合
- 您还可以访问一个包含每个城市统计数据的结构化表。
有了这些数据集合,我们来看一个示例查询:“告诉我关于人口最多的城市的艺术和文化。”
回答这个问题的“正确”方法大致如下
- 查询结构化表,找出人口最多的城市。
SELECT city, population FROM city_stats ORDER BY population DESC LIMIT 1- 将原始问题转换为更详细的问题:“告诉我关于东京的艺术和文化。”
- 在您的向量数据库上提出新问题。
- 使用原始问题 + 对 SQL 数据库和向量数据库的中间查询/响应来合成答案。
让我们思考一下这种序列的一些高层含义
- 我们希望将 SQL 查询作为第一个“检索”步骤,而不是进行嵌入搜索(以及可选的元数据过滤器)来检索相关上下文。
- 我们需要确保我们能够以某种方式将 SQL 查询结果与存储在向量数据库中的上下文“联接”起来。目前没有现有的语言来“联接”SQL 数据库和向量数据库之间的信息。我们需要自己实现此行为。
- 任何一个数据源都无法独立回答这个问题。结构化表只包含人口信息。向量数据库包含城市信息,但没有简单的方法来查询人口最多的城市。
结合结构化分析和语义搜索的查询引擎
我们创建了一个全新的查询引擎(SQLAutoVectorQueryEngine),它可以查询、联接、排序和结合来自 SQL 数据库的结构化数据以及来自向量数据库的非结构化数据,以合成最终答案。
SQLAutoVectorQueryEngine 通过传入一个 SQL 查询引擎(GPTNLStructStoreQueryEngine)以及一个使用我们的向量存储自动检索器模块(VectorIndexAutoRetriever)的查询引擎来初始化。SQL 查询引擎和向量查询引擎都被包装成包含 name 和 description 字段的“Tool”对象。
提醒:
VectorIndexAutoRetriever接受自然语言查询作为输入。根据对向量数据库元数据模式的一些了解,自动检索器首先推断其他需要传入的查询参数(例如 top-k 值和元数据过滤器),并使用所有查询参数针对向量数据库执行查询。
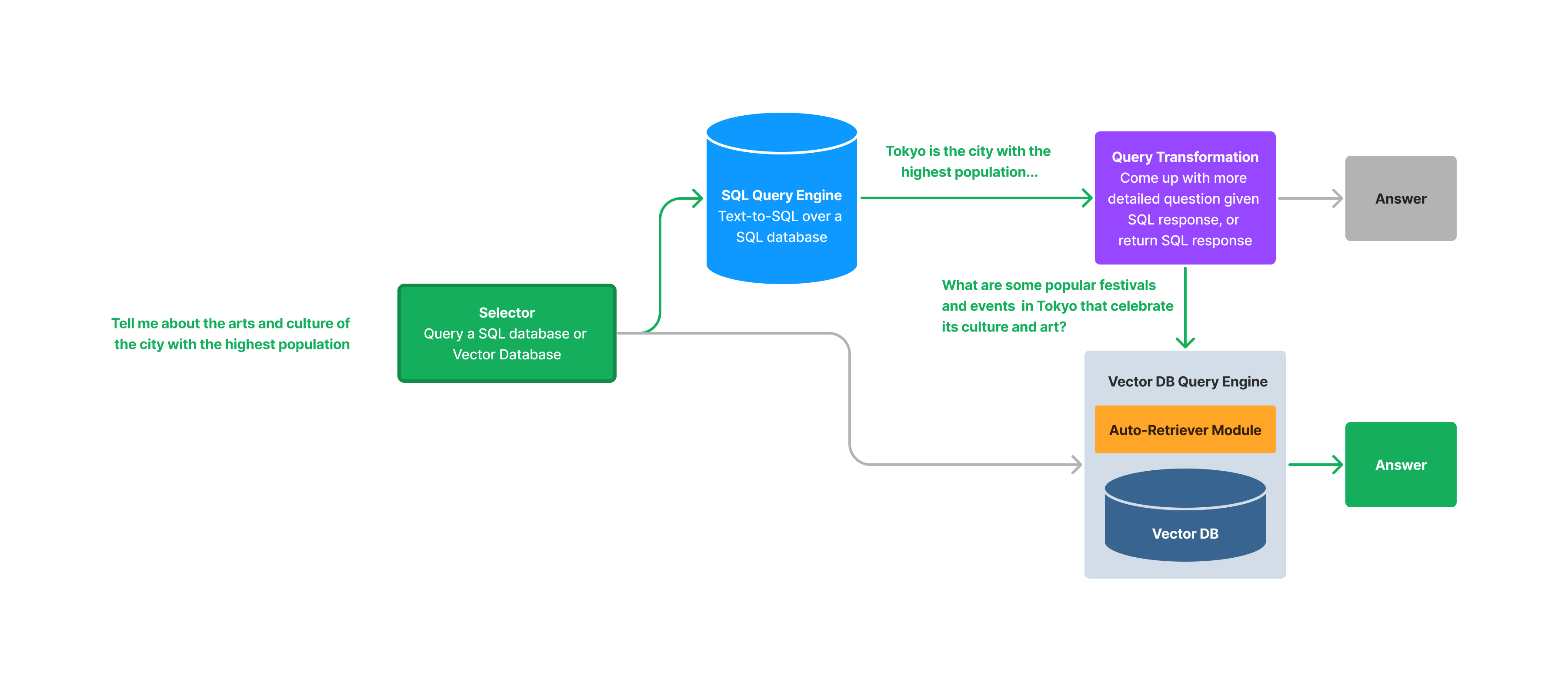
在查询时,我们执行以下步骤
- 一个选择器提示(类似地用在我们的
RouterQueryEngine中,请参阅指南)首先选择是查询 SQL 数据库还是向量数据库。如果选择使用向量查询引擎,则函数执行的其余部分与使用VectorIndexAutoRetriever查询RetrieverQueryEngine相同。 - 如果选择查询 SQL 数据库,它将针对数据库执行 Text-to-SQL 查询操作,并(可选地)合成自然语言输出。
- 运行一个查询转换,根据 SQL 查询的结果,将原始问题转换为更详细的问题。例如,如果原始问题是“告诉我关于人口最多的城市的艺术和文化。”,而 SQL 查询返回东京是人口最多的城市,那么新问题就是“告诉我关于东京的艺术和文化。”唯一的例外是如果 SQL 查询本身足以回答原始问题;如果是,则函数执行以 SQL 查询作为响应返回。
- 然后通过向量存储查询引擎运行新查询,该引擎执行从向量存储中检索,然后进行 LLM 响应合成。我们强制使用
VectorIndexAutoRetriever模块。这允许我们根据 SQL 查询的结果自动推断正确的查询参数(查询字符串、top k、元数据过滤器)。例如,对于上面的示例,我们可能会推断查询为query_str="arts and culture"和filters={"title": "Tokyo"}之类的。 - 原始问题、SQL 查询、SQL 响应、向量存储查询和向量存储响应被组合成一个提示,用于合成最终答案。
回顾一下,以下是关于这种方法的一些一般性评论
- 使用我们的自动检索器模块是我们模拟 SQL 数据库和向量数据库之间联接的一种方式。我们有效地使用 SQL 查询的结果来确定用于查询向量数据库的参数。
- 这也意味着 SQL 数据库中的项目与向量数据库中的元数据之间无需显式映射,因为我们可以依靠 LLM 为不同项目生成正确的查询。不过,对结构化表和文档存储元数据之间的显式关系进行建模会很有趣;这样就不需要在自动检索步骤中花费额外的 LLM 调用来推断正确的元数据过滤器。
实验
那么,这效果如何呢?它在各种查询中表现出惊人的效果,从可以利用结构化和非结构化数据的查询,到特定于结构化数据集合或非结构化数据集合的查询。
设置
我们的实验设置非常简单。我们有一个名为 city_stats 的 SQL 表,其中包含三个不同城市(多伦多、东京和柏林)的城市、人口和国家信息。
我们还使用 Pinecone 索引存储与这三个城市相关的维基百科文章。每篇文章都被分块并存储为单独的“节点”对象;每个块还包含一个包含城市名称的 title 元数据属性。
然后,我们从 Pinecone 向量索引中派生出 VectorIndexAutoRetriever 和 RetrieverQueryEngine。
from llama_index.indices.vector_store.retrievers import VectorIndexAutoRetriever
from llama_index.vector_stores.types import MetadataInfo, VectorStoreInfo
from llama_index.query_engine.retriever_query_engine import RetrieverQueryEngine
vector_store_info = VectorStoreInfo(
content_info='articles about different cities',
metadata_info=[
MetadataInfo(
name='city',
type='str',
description='The name of the city'),
]
)
vector_auto_retriever = VectorIndexAutoRetriever(vector_index, vector_store_info=vector_store_info)
retriever_query_engine = RetrieverQueryEngine.from_args(
vector_auto_retriever, service_context=service_context
)您还可以按如下方式获取 SQL 查询引擎
sql_query_engine = sql_index.as_query_engine()SQL 查询引擎和向量查询引擎都可以包装成 QueryEngineTool 对象。
sql_tool = QueryEngineTool.from_defaults(
query_engine=sql_query_engine,
description=(
'Useful for translating a natural language query into a SQL query over a table containing: '
'city_stats, containing the population/country of each city'
)
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=query_engine,
description=f'Useful for answering semantic questions about different cities',
)最后,我们可以定义我们的 SQLAutoVectorQueryEngine
query_engine = SQLAutoVectorQueryEngine(
sql_tool,
vector_tool,
service_context=service_context
)结果
我们运行了一些示例查询。
查询 1
query_engine.query(
'Tell me about the arts and culture of the city with the highest population'
)中间步骤
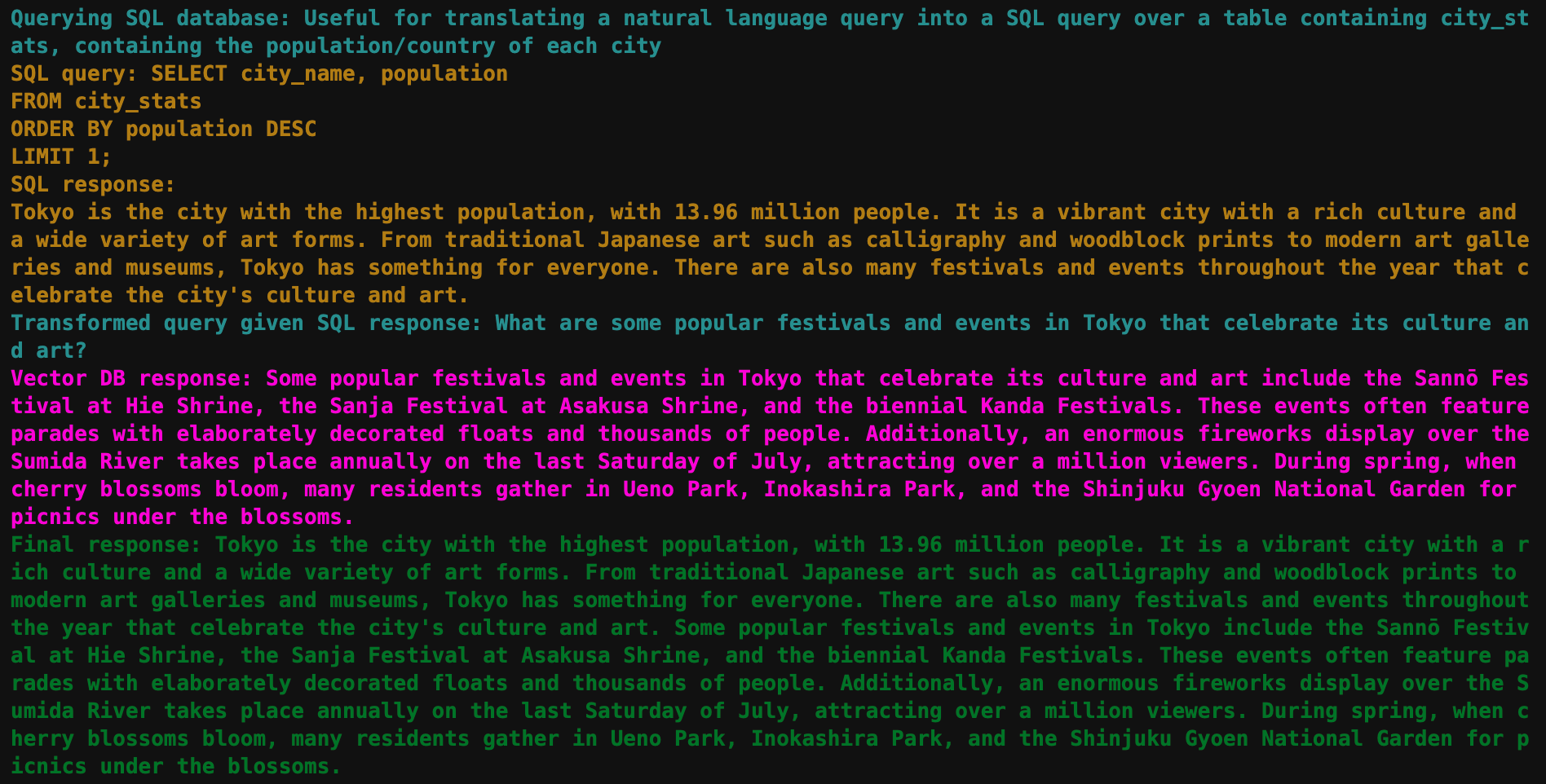
最终响应
Tokyo is the city with the highest population, with 13.96 million people. It is a vibrant city with a rich culture and a wide variety of art forms. From traditional Japanese art such as calligraphy and woodblock prints to modern art galleries and museums, Tokyo has something for everyone. There are also many festivals and events throughout the year that celebrate the city's culture and art. Some popular festivals and events in Tokyo include the Sannō Festival at Hie Shrine, the Sanja Festival at Asakusa Shrine, and the biennial Kanda Festivals. These events often feature parades with elaborately decorated floats and thousands of people. Additionally, an enormous fireworks display over the Sumida River takes place annually on the last Saturday of July, attracting over a million viewers. During spring, when cherry blossoms bloom, many residents gather in Ueno Park, Inokashira Park, and the Shinjuku Gyoen National Garden for picnics under the blossoms.此查询运行了 SQLAutoVectorQueryEngine 的完整流程。它首先查询 SQL 数据库以找出人口最多的城市(“东京”),然后使用新查询查询向量数据库。结果被合并到最终响应中。
查询 2
query_engine.query("Tell me about the history of Berlin")中间步骤

最终响应
Berlin's history dates back to the early 13th century when it was founded as a small settlement. In 1618, the Margraviate of Brandenburg entered into a personal union with the Duchy of Prussia, and in 1701, they formed the Kingdom of Prussia with Berlin as its capital. The city grew and merged with neighboring cities, becoming a center of the Enlightenment under the rule of Frederick the Great in the 18th century.
The Industrial Revolution in the 19th century transformed Berlin, expanding its economy, population, and infrastructure. In 1871, it became the capital of the newly founded German Empire. The early 20th century saw Berlin as a hub for the German Expressionist movement and a major world capital known for its contributions to science, technology, arts, and other fields.
In 1933, Adolf Hitler and the Nazi Party came to power, leading to a decline in Berlin's Jewish community and the city's involvement in World War II. After the war, Berlin was divided into East and West Berlin, with the former under Soviet control and the latter under the control of the United States, United Kingdom, and France. The Berlin Wall was built in 1961, physically and ideologically dividing the city until its fall in 1989. Following the reunification of Germany in 1990, Berlin once again became the capital of a unified Germany and has since continued to grow and develop as a major global city.此查询仅需要向量数据库,而不需要 SQL 数据库。初始选择器正确地识别出我们只需查询向量数据库并返回结果即可。
查询 3
query_engine.query('Can you give me the country corresponding to each city?')中间步骤

最终响应
Toronto is in Canada, Tokyo is in Japan, and Berlin is in Germany.此查询仅通过查询 SQL 数据库即可回答,不需要向量数据库的额外信息。查询转换步骤正确地将“None”识别为后续问题,表明原始问题已经得到解答。
结论
到目前为止,围绕 LLM + 非结构化数据和 LLM + 结构化数据的技术栈在很大程度上是独立的。我们对如何将 LLM 结合到结构化和非结构化数据之上,以新颖有趣的方式解锁新的检索/查询能力感到兴奋!
非常希望您尝试 SQLAutoVectorQueryEngine 并告诉我们您的想法。



