
Jiang Chen • 2024-01-25
使用 LlamaIndex 和 Zilliz Cloud Pipelines 构建可扩展的 RAG 应用
简介
我们看到大量的开发者正在构建检索增强生成(RAG)应用。RAG 技术栈通常包含一个检索管道、LLM 和 prompt,其中 LLM 易于获取,开发者也熟悉 prompt 定制。然而,对于不熟悉搜索和索引的开发者来说,构建一个有效的检索管道通常需要大量的帮助。一个生产就绪的检索管道通常包含以下组件
- 用于解析和分割长文本的文档加载器
- 作为核心索引组件的嵌入模型
- 存储向量嵌入的向量数据库
- 用于未来优化检索质量的高级组件,例如用于更好地判断语义相似度的重排序模型
运行这个复杂的技术栈具有挑战性。它涉及管理软件包依赖、在 Kubernetes 集群中托管服务以及监控 ML 模型的性能。高昂的 DevOps 成本分散了开发者对 RAG 应用用户体验最关键部分的注意力:prompt 工程、答案生成和用户界面。
尽管经验丰富的搜索基础设施工程师可能仍然会为了灵活性而管理复杂的技术栈,但 Zilliz 相信,大多数 RAG 开发者可以从一个用户友好且允许轻度定制的检索 API 服务中受益。
集成 Zilliz Cloud Pipelines 和 LlamaIndex 为解决这个问题带来了一种新方法。Zilliz Cloud Pipelines 是一个完全托管的、可扩展的检索服务。LlamaIndex 是一个灵活的 RAG 框架,提供用于组织业务逻辑(如检索和 prompt 工程)的库和工具。Zilliz Cloud Pipelines 的 API 服务在 LlamaIndex 中被抽象为 ManagedIndex。使用 ZillizCloudPipelineIndex 的 RAG 开发者可以轻松地将应用从一个用户扩展到数百万用户,而无需费心设置和维护复杂的检索技术栈。它将技术复杂性隐藏在少数函数调用背后,从而使开发者能够专注于其 RAG 应用的核心用户体验。
在这篇博客中,我们展示了如何使用 ZillizCloudPipelineIndex 来构建高质量的 RAG 聊天机器人。该聊天机器人具有可扩展性,并通过元数据过滤支持多租户。
设置
由于 Zilliz Cloud Pipelines 是一项 API 服务,首先您需要设置一个 Zilliz Cloud 账户并创建一个免费的无服务器集群。
现在您可以构建 ZillizCloudPipelineIndex 并获取用于稍后索引文档和查询的 handler。
from llama_index.indices import ZillizCloudPipelineIndex
zcp_index = ZillizCloudPipelineIndex(
project_id="<YOUR_ZILLIZ_PROJECT_ID>",
cluster_id="<YOUR_ZILLIZ_CLUSTER_ID>",
token="<YOUR_ZILLIZ_API_KEY>",
)
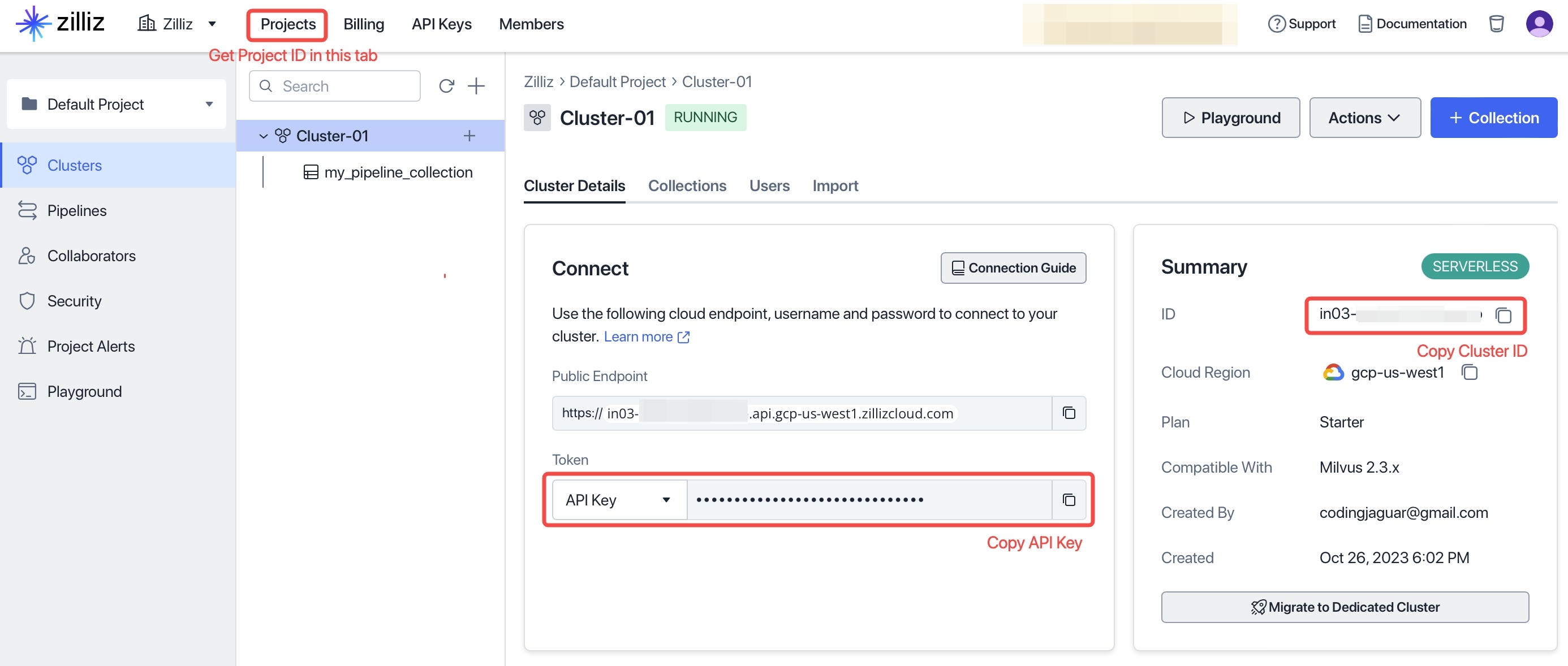
zcp_index.create_pipelines(metadata_schema={"user_id": "VarChar", "version": "VarChar"})您可以从您的 Zilliz 账户中复制 Project ID、Cluster ID 和 API Key,如下所示

摄取文档
假设您的应用有多个用户,并且您希望为每个用户的文档打标签以提供隔离。您的应用逻辑可以按如下方式实现。为简单起见,这里我们演示摄取公共文档。目前,Zilliz Cloud Pipelines 支持存储和管理在 AWS S3 和 Google Cloud Storage 中的文档。本地文档上传也即将支持。
# user1 ingests a document, it is technical documentation for v2.3 version.
zcp_index.insert_doc_url(
url="https://publicdataset.zillizcloud.com/milvus_doc.md",
metadata={"user_id": "user1", "version": "2.3"},
)
# user2 ingests a document, it is technical documentation for v2.2 version.
zcp_index.insert_doc_url(
url="https://publicdataset.zillizcloud.com/milvus_doc_22.md",
metadata={"user_id": "user2", "version": "2.2"},
)查询
要使用 ZillizCloudPipelineIndex 进行语义搜索,您可以通过指定几个参数来使用其 as_query_engine() 方法
- search_top_k: 要检索多少个文本节点/块。可选,默认为 DEFAULT_SIMILARITY_TOP_K (2)。
- filters: 元数据过滤器。可选,默认为 None。在此示例中,我们将过滤器设置为仅检索特定用户的文档,以提供用户级别的数据隔离。
- output_metadata: 与检索到的文本节点一起返回哪些元数据字段。可选,默认为 []。
# Query the documents in ZillizCloudPipelineIndex
from llama_index.vector_stores.types import ExactMatchFilter, MetadataFilters
query_engine_for_user1 = zcp_index.as_query_engine(
search_top_k=3,
filters=MetadataFilters(
filters=[
ExactMatchFilter(key="user_id", value="user1")
] # The query would only search from documents of user1.
),
output_metadata=["user_id", "version"], # output these tags together with document text
)
question = "Can users delete entities by complex boolean expressions?"
# The chatbot will only answer with the retrieved information from user1's documents
answer = query_engine_for_user1.query(question)感谢 LlamaIndex 和 Zilliz Cloud Pipelines 的抽象,仅用 30 行代码,我们就可以演示一个支持多租户的 RAG 服务。最重要的是,这个简单的 RAG 应用可以轻松扩展以服务数百万用户,而无需修改任何代码。
接下来做什么?
您可以查阅官方的 LlamaIndex 文档,了解 ZillizCloudPipelineIndex 的高级定制。如果您有任何问题,请在 Zilliz 用户组 或 LlamaIndex discord 提问。Zilliz Cloud Pipelines 即将支持本地文件上传以及更多嵌入和重排序模型的选择。获取一个免费的 Zilliz Cloud 账户并关注更多更新!



